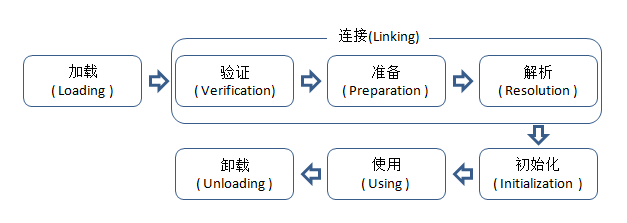
加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。注意,这里笔者写的是按部就班地“开始”,而不是按部就班地“进行”或“完成”,强调这点是因为这些阶段通常都是互相交叉地混合式进行的,通常会在一个阶段执行的过程中调用、激活另外一个阶段。
加载
“加载”是“类加载”(Class Loading)过程的一个阶段,希望读者没有混淆这两个看起来很相似的名词。在加载阶段,虚拟机需要完成以下3 件事情:
- 通过一个类的全限定名来获取定义此类的二进制字节流。
- 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构。
- 在内存中生成一个代表这个类的java. lang. Class 对象,作为方法区这个类的各种数据的访问入口。
虚拟机规范的这3 点要求其实并不算具体,因此虚拟机实现与具体应用的灵活度都是相当大的。例如“通过一个类的全限定名来获取定义此类的二进制字节流”这条,它没有指明二进制字节流要从一个Class 文件中获取,准确地说是根本没有指明要从哪里获取、怎样获取。虚拟机设计团队在加载阶段搭建了一个相当开放的、广阔的“舞台”,Java 发展历程中,充满创造力的开发人员则在这个“舞台”上玩出了各种花样,许多举足轻重的Java 技术都建立在这一基础之上,例如:
- 从ZIP 包中读取,这很常见,最终成为日后JAR、EAR、WAR 格式的基础。
- 从网络中获取,这种场景最典型的应用就是Applet。
- 运行时计算生成,这种场景使用得最多的就是动态代理技术,在java. lang. reflect. Proxy 中,就是用了ProxyGenerator. generateProxyClass 来为特定接口生成形式为"*$ Proxy" 的代理类的二进制字节流。
- 由其他文件生成,典型场景是JSP 应用,即由JSP 文件生成对应的Class 类。
- 从数据库中读取,这种场景相对少见些,例如有些中间件服务器(如SAP Netweaver)可以选择把程序安装到数据库中来完成程序代码在集群间的分发。
相对于类加载过程的其他阶段,一个非数组类的加载阶段(准确地说,是加载阶段中获取类的二进制字节流的动作)是开发人员可控性最强的,因为加载阶段既可以使用系统提供的引导类加载器来完成,也可以由用户自定义的类加载器去完成,开发人员可以通过定义自己的类加载器去控制字节流的获取方式(即重写一个类加载器的loadClass() 方法)。
对于数组类而言,情况就有所不同,数组类本身不通过类加载器创建,它是由Java 虚拟机直接创建的。但数组类与类加载器仍然有很密切的关系,因为数组类的元素类型(Element Type,指的是数组去掉所有维度的类型)最终是要靠类加载器去创建,一个数组类(下面简称为C)创建过程就遵循以下规则:
如果数组的组件类型(Component Type,指的是数组去掉一个维度的类型)是引用类型,那就递归采用本节中定义的加载过程去加载这个组件类型,数组C 将在加载该组件类型的类加载器的类名称空间上被标识(这点很重要,在7. 4 节会介绍到,一个类必须与类加载器一起确定唯一性)。
如果数组的组件类型不是引用类型(例如int[] 数组),Java 虚拟机将会把数组C 标记为与引导类加载器关联。
数组类的可见性与它的组件类型的可见性一致,如果组件类型不是引用类型,那数组类的可见性将默认为public。
加载阶段完成后,虚拟机外部的二进制字节流就按照虚拟机所需的格式存储在法区之中,方法区中的数据存储格式由虚拟机实现自行定义,虚拟机规范未规定此区域的具体数据结构。然后在内存中实例化一个java.lang.Class类的对象(并没有明确规定是在Java堆中,对于HotSpot虚拟机而言,Class对象比较特殊,它虽然是对象,但是存放在方法区里面),这个对象将作为程序访问方法区中的这些类型数据的外部接口。
加载阶段与连接阶段的部分内容(如一部分字节码文件格式验证动作)是交叉进行的,加载阶段尚未完成,连接阶段可能已经开始,但这些夹在加载阶段之中进行的动作,仍然属于连接阶段的内容,这两个阶段的开始时间仍然保持着固定的先后顺序。
验证
验证是连接阶段的第一步,这一阶段的目的是为了确保Class文件的字节流中包含的信息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
从整体上看,验证阶段大致上会完成下面4个阶段的检验动作:文件格式验证、元数据验证、字节码验证、符号引用验证。
- 是否以魔数0xCAFEBABE 开头。
- 主、次版本号是否在当前虚拟机处理范围之内。
- 常量池的常量中是否有不被支持的常量类型(检查常量tag 标志)。
- 指向常量的各种索引值中是否有指向不存在的常量或不符合类型的常量。
- CONSTANT_ Utf8_ info 型的常量中是否有不符合UTF8 编码的数据。
- Class 文件中各个部分及文件本身是否有被删除的或附加的其他信息。
- ……
- 这个类是否有父类(除了java. lang. Object 之外,所有的类都应当有父类)。
- 这个类的父类是否继承了不允许被继承的类(被final 修饰的类)。
- 如果这个类不是抽象类,是否实现了其父类或接口之中要求实现的所有方法。
- 类中的字段、方法是否与父类产生矛盾(例如覆盖了父类的final 字段,或者出现不符合规则的方法重载,例如方法参数都一致,但返回值类型却不同等)。
- ……
- 保证任意时刻操作数栈的数据类型与指令代码序列都能配合工作,例如不会出现类似这样的情况:在操作栈放置了一个int 类型的数据,使用时却按long 类型来加载入本地变量表中。
- 保证跳转指令不会跳转到方法体以外的字节码指令上。
- 保证方法体中的类型转换是有效的,例如可以把一个子类对象赋值给父类数据类型,这是安全的,但是把父类对象赋值给子类数据类型,甚至把对象赋值给与它毫无继承关系、完全不相干的一个数据类型,则是危险和不合法的。
- ……
- 符号引用中通过字符串描述的全限定名是否能找到对应的类。
- 在指定类中是否存在符合方法的字段描述符以及简单名称所描述的方法和字段。
- 符号引用中的类、字段、方法的访问性(private、protected、public、default)是否可被当前类访问。
- ……
public static int value=123;
那变量value在准备阶段过后的初始值为0而不是123,因为这时候尚未开始执行任何Java方法,而把value赋值为123的putstatic指令是程序被编译后,存放于类构造器<clinit>()方法之中,所以把value赋值为123的动作将在初始化阶段才会执行。
如果类字段的字段属性表中存在ConstantValue属性,那在准备阶段变量value就会被初始化为ConstantValue属性所指定的值,假设上面类变量value的定义变为:
public static final int value=123;
编译时Javac将会为value生成ConstantValue属性,在准备阶段虚拟机就会根据ConstantValue的设置将value赋值为123。
符号引用(Symbolic References):符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能无歧义地定位到目标即可。符号引用与虚拟机实现的内存布局无关,引用的目标并不一定已经加载到内存中。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须都是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
直接引用(Direct References):直接引用可以是直接指向目标的指针、相对偏移量或是一个能间接定位到目标的句柄。直接引用是和虚拟机实现的内存布局相关的,同一个符号引用在不同虚拟机实例上翻译出来的直接引用一般不会相同。如果有了直接引用,那引用的目标必定已经在内存中存在。
解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用点限定符7类符号引用进行。public class Test{ static { i=0;//给变量赋值可以正常编译通过 System.out.print(i);//这句编译器会提示"非法向前引用" } static int i=1; }
<clinit>()方法与类的构造函数(或者说实例构造器<init>()方法)不同,它不需要显式地调用父类的类构造器,虚拟机会保证在子类的<clinit>()方法执行之前,父类的<clinit>()方法已经执行完毕。因此在虚拟机中第一个被执行的<clinit>()方法的类肯定是java.lang.Object。