目录:
- Dictionary Data Structure 词典数据结构
- Wild-Card Query 通配符查询
- Spelling Correction 拼写纠正
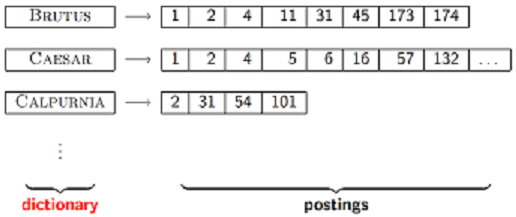
- 索引词(term vocabulary)。
- 文档频率(document frequency,即这个词在多少个文档里出现)。
- 指向倒排表的指针(pointers to each postings list )。


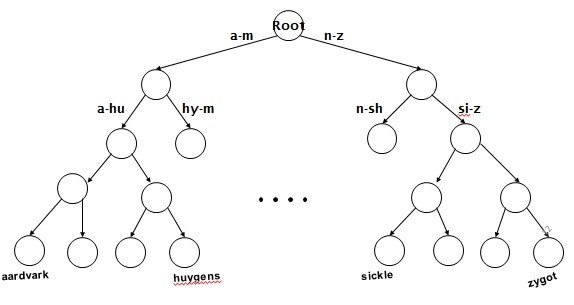
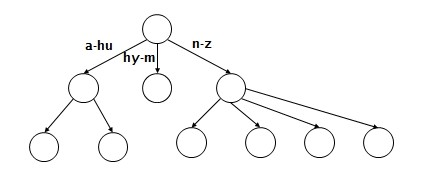
一棵m 阶的B-树满足下列特性的m 叉树:
- 树中每个结点至多有m 棵子树;
- 若根结点不是叶子结点,则至少有两棵子树;
- 除根结点之外的所有非终端结点至少有[m/2] 棵子树;
- 所有的非终端结点中包含以下信息数据:(n,A0,K1,A1,K2,…,Kn,An)。其中:Ki(i=1,2,…,n)为关键码,且Ki<Ki+1,Ai 为指向子树根结点的指针(i=0,1,…,n),且指针Ai-1 所指子树中所有结点的关键码均小于Ki (i=1,2,…,n),An 所指子树中所有结点的关键码均大于Kn。n为关键码的个数。
- 所有的叶子结点都出现在同一层次上,并且不带信息(可以看作是外部结点或查找失败的结点,实际上这些结点不存在,指向这些结点的指针为空)。
这样讲起来或许比较枯燥难懂,看这张图就好了:
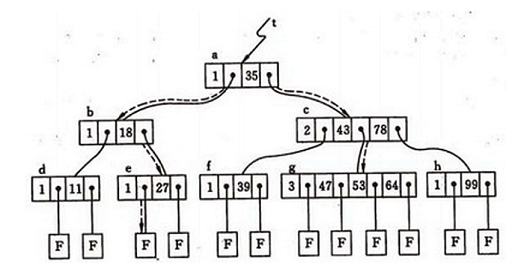
树的优点就是可以解决前缀查找的问题了。
缺点是速度比哈希慢点,是O(logM)并且要求是平衡的,重新平衡一棵树的代价大。(虽然B-树减轻了这种代价)
Wildcard queries,通配符查询。
比如查询语句 mon*:找出所有以mon开头的单词。如果采用树(或者B-树)结构词典,我们可以很容易的解决,只需要查询范围在mon ≤ w < moo的所有单词就ok了。
但是查询语句 *mon:找出所有以mon结尾的单词就比较困难了。其中一种办法就是我们增加一个额外的B-树来存储所有单词,以从后向前的顺序,然后在这个树上查询范围在nom ≤ w < non的所有单词。
可是如何处理通配符在单词中间的查询呢?
比如query是co*tion的话。我们当然可以分别在B-树查询到co*和*tion的所有单词然后合并这些单词,但是这样开销太大了。
解决办法就是:轮排索引(Permuterm Index),我们把query的通配符转换到结尾处。
设置一个标志$表示单词的结尾。
以hello举例,hello可以被转换成hello$, ello$h, llo$he, lo$hel, o$hell。$代表中hello的结束。现在,查询X等于查询X$,查询X*等于查询X*$,查询*X等于查询X$*,查询X*Y等于查询Y$X*。对于hel*o来说,X等于hel,Y等于o。
既然我们已经把通配符都弄到了单词尾部,现在我们又可以通过B-树像以前那样查询拉。
以上,我们已经完成了对query的转换,那么那些存储的索引的词要怎么处理才能配合这种query查询呢?
我们对索引来建立索引!!
Bigram indexes。就是两两个字母来索引。
举例来说,一个文本是“April is the cruelest month”,分别成Bigram indexes就是“$a,ap,pr,ri,il,l$,$i,is,s$,$t,th,he,e$,$c,cr,ru,ue,el,le,es,st,t$, $m,mo,on,nt,h$”,其中$ 代表着单词边界的符号。
那么如何对索引建立索引??
维护第二个倒排表,倒排表的索引词是Bigram indexes,posting list的值就是与之匹配的dictionary terms。
像这样:
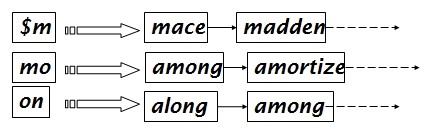
好了!目前为止,我们既对query进行了处理,也对terms进行了处理。
所以现在如果我们要查询 mon*,query会被分解成 $m AND mo AND on ,然后从上图中的倒排表做两个AND可以得到匹配的terms了!!
但是,我们会发现 $m AND mo AND on 也会匹配到单词moon,而moon不符合mon*的格式,这是他的一个缺点。我们必须要过滤掉这些词。
另外,一条查询语句往往相当多的布尔查询,这个开销也挺大的。
Spelling correction,拼写校正。
我们google一下 Alanis Morisett ,得到结果如图:
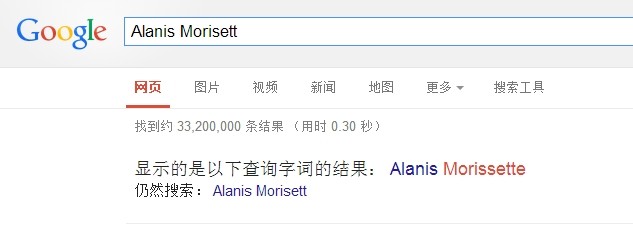
对了,就是这个提示,您找的是不是:xxxxxx。
在搜索引擎中,需要有一个可以查询到所有正确单词的词典。
给定一个词典和一个query,返回一个和query最接近的words。
怎么用才算是最接近??
- 编辑距离算法。
- 带权编辑距离算法。
编辑距离(Edit distance):
给定两个字符串S1和S2,从S1转换到S2的最小步骤就是他们的编辑距离。这些步骤包括,Insert(1步), Delete(1步), Replace(1步),copy(0步)。
比如说:
dof到dog的编辑距离是1,cat到act的编辑距离是2,cat到dog的编辑距离是3.
算法导论里关于编辑距离的伪代码如下:

举例子:算cats到fast的编辑距离~
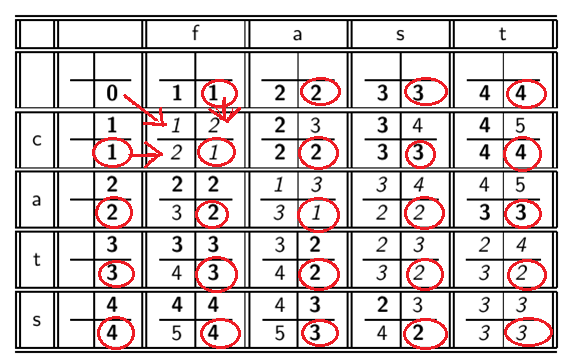
括号里圈出来的表示实际应该填的值,其他的只是用来进行对比,取其中最小的数。
具体到表中的每一格中四个数字的含义就是:

从左边的格子过来代表增加,上边的格子过来代表删除,斜上角的格子过来代表替换(此时两个字符不相等)或复制(此时两个字符不相等)。
编辑距离就是这样子。那么什么是带权编辑距离呢?
比如说,我们打字的时候,m被错打成n的几率会比m错打成p的几率更大,所以我们应该认为m和n的编辑距离小于m到p的编辑距离。因此将m替换为n时计算编辑距离应该比将m替换为p时的编辑距离小。
实现带权编辑距离,我们需要一个额外的权值矩阵。
那么,给定一个查询词,我们是不是得计算这个查询词和所有的索引词之间编辑距离呢?
答案是否定的,因为这样开销很大而且慢。
怎么用减少计算呢??
比如说,如果query是lord:
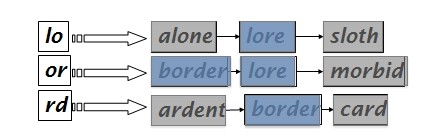
我们只取lo,or,rd中有重叠两次或以上的term,然后合并这些term,以这个为范围进行编辑距离的计算。
如果本文对您有一点点的帮助,请帮忙点个赞,十分感谢!~ =。=
如果您有更好的见解或纠正,欢迎您在下面评论指出。