- 注解的作用
-- 150 节点插入 INSERT INTO `order_info` (`order_id`, `uid`, `nums`, `state`, `create_time`, `update_time`) VALUES (9, 1000003, 2673, 1, '2019-9-25 11:35:49', '2019-9-25 11:35:49'); -- 151 节点插入 INSERT INTO `order_detail` (`order_id`, `id`, `goods_id`, `price`, `is_pay`, `is_ship`, `status`) VALUES (9, 20180001, 2673, 19.99, 1, 1, 1);
select a.order_id,b.price from order_info a, order_detail b where a.nums = b.goods_id;
Mycat 作为一个中间件,有很多自身不支持的 SQL 语句,比如存储过程,但是这些 语句在实际的数据库节点上是可以执行的。有没有办法让 Mycat 做一层透明的代理转发, 直接找到目标数据节点去执行这些 SQL 语句呢?
那我们必须要有一种方式告诉 Mycat 应该在哪个节点上执行。这个就是 Mycat 的注 解。我们在需要执行的 SQL 语句前面加上一段代码,帮助 Mycat 找到我们的目标节点。
- 注解的用法
注解的形式是 :
/*!mycat: sql=注解 SQL 语句*/
注解的使用方式是 :
/*!mycat: sql=注解 SQL 语句*/ 真正执行的 SQL
使用时将 = 号后的 "注解 SQL 语句" 替换为需要的 SQL 语句即可。
使用注解有一些限制,或者注意的地方:
| 原始SQL | 注解SQL |
| select |
如果需要确定分片,则使用能确定分片的注解,比如/*!mycat: sql=select * from users where |
| insert | 使用 insert 的表作为注解 SQL,必须能确定到某个分片 原始 SQL 插入的字段必须包括分片字段 非分片表(只在某个节点上):必须能确定到某个分片 |
| delete | 使用 delete 的表作为注解 SQL |
| update | 使用 update 的表作为注解 SQL |
使用注解并不额外增加 MyCat 的执行时间;从解析复杂度以及性能考虑,注解 SQL 应尽量简单,因为它只是用来做路由的。
注解可以帮我们解决什么问题呢?
- 注解使用示例
创建表或存储过程
customer.id=1 全部路由到 146
-- 存储过程 /*!mycat: sql=select * from customer where id =1 */ CREATE PROCEDURE test_proc() BEGIN END ; -- 表 /*!mycat: sql=select * from customer where id =1 */ CREATE TABLE test2(id INT);
特殊语句自定义分片
Mycat 本身不支持 insert select,通过注解支持
/*!mycat: sql=select * from customer where id =1 */ INSERT INTO test2(id) SELECT id FROM order_detail;
多表 ShareJoin
/*!mycat:catlet=io.mycat.catlets.ShareJoin */ select a.order_id,b.price from order_info a, order_detail b where a.nums = b.goods_id;
读写分离
读写分离 : 配置 Mycat 读写分离后,默认查询都会从读节点获取数据,但是有些场 景需要获取实时数据,如果从读节点获取数据可能因延时而无法实现实时,Mycat 支持 通过注解 /*balance*/ 来强制从写节点(write host)查询数据。
/*balance*/ select a.* from customer a where a.id=6666;
读写分离数据库选择(1.6 版本之后)
/*!mycat: db_type=master */ select * from customer; /*!mycat: db_type=slave */ select * from customer; /*#mycat: db_type=master */ select * from customer; /*#mycat: db_type=slave */ select * from customer;
注解支持的'! '不被 mysql 单库兼容
注解支持的'#'不被 MyBatis 兼容
随着 Mycat 的开发,更多的新功能正在加入。
- 注解原理
Mycat 在执行 SQL 之前会先解析 SQL 语句,在获得分片信息后再到对应的物理节 点上执行。如果 SQL 语句无法解析,则不能被执行。如果语句中有注解,则会先解析注 解的内容获得分片信息,再把真正需要执行的 SQL 语句发送对对应的物理节点上。 所以我们在使用主机的时候,应该清楚地知道目标 SQL 应该在哪个节点上执行,注 解的 SQL 也指向这个分片,这样才能使用。如果注解没有使用正确的条件,会导致原始 SQL 被发送到所有的节点上执行,造成数据错误。
3.分片策略详解
分片的目标是将大量数据和访问请求均匀分布在多个节点上,通过这种方式提升数 据服务的存储和负载能力。
总体上分为连续分片和离散分片,还有一种是连续分片和离散分片的结合,例如先 范围后取模。
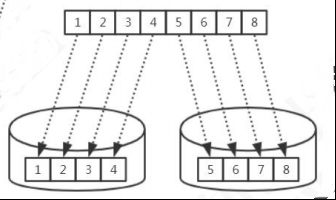

比如范围分片(id 或者时间)就是典型的连续分片,单个分区的数量和边界是确定 的。离散分片的分区总数量和边界是确定的,例如对 key 进行哈希运算,或者再取模。
关键词:范围查询、热点数据、扩容
连续分片优点:
1)范围条件查询消耗资源少(不需要汇总数据)
2)扩容无需迁移数据(分片固定)
连续分片缺点:
1)存在数据热点的可能性
2)并发访问能力受限于单一或少量 DataNode(访问集中)
离散分片优点:
1)并发访问能力增强(负载到不同的节点)
2)范围条件查询性能提升(并行计算)
离散分片缺点:
1)数据扩容比较困难,涉及到数据迁移问题
2)数据库连接消耗比较多
- 连续分片
范围分片(已演示):
<tableRule name="auto-sharding-long"> <rule> <columns>id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> </function>
# range start-end ,data node index # K=1000,M=10000. 0-500M=0 500M-1000M=1 1000M-1500M=2
特点:容易出现冷热数据
按自然月分片:
建表语句:
CREATE TABLE `sharding_by_month` ( `create_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP, `db_nm` varchar(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表:
<schema name="catmall" checkSQLschema="false" sqlMaxLimit="100"> <table name="sharding_by_month" dataNode="dn1,dn2,dn3" rule="qs-sharding-by-month" /> </schema>
分片规则:
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>qs-partbymonth</algorithm>
</rule>
</tableRule>
分片算法:
<function name="qs-partbymonth" class="io.mycat.route.function.PartitionByMonth"> <property name="dateFormat">yyyy-MM-dd</property> <property name="sBeginDate">2019-10-01</property> <property name="sEndDate">2019-12-31</property> </function>
- columns 标识将要分片的表字段,字符串类型,与 dateFormat 格式一致。
- algorithm 为分片函数。
- dateFormat 为日期字符串格式。
- sBeginDate 为开始日期。
- sEndDate 为结束日期
注意:节点个数要大于月份的个数
测试语句:
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-10-16', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-10-27', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-11-04', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-11-11', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-12-25', database());
INSERT INTO sharding_by_month (create_time,db_nm) VALUES ('2019-12-31', database());
另外还有按天分片(可以指定多少天一个分片)、按小时分片
- 离散分片
枚举分片:
将所有可能出现的值列举出来,指定分片。例如:全国 34 个省,要将不同的省的数 据存放在不同的节点,可用枚举的方式。
建表语句:
CREATE TABLE `sharding_by_intfile` ( `age` int(11) NOT NULL, `db_nm` varchar(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表:
<table name="sharding_by_intfile" dataNode="dn$1-3" rule="qs-sharding-by-intfile" />
分片规则:
<tableRule name="sharding-by-intfile">
<rule>
<columns>sharding_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
分片算法:
<function name="hash-int" class="org.opencloudb.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
type:默认值为 0,0 表示 Integer,非零表示 String。
PartitionByFileMap.java,通过 map 来实现。
策略文件:partition-hash-int.txt
16=0 17=1 18=2
插入数据测试:
INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (16, database()); INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (17, database()); INSERT INTO `sharding_by_intfile` (age,db_nm) VALUES (18, database());
特点:适用于枚举值固定的场景。
一致性哈希
一致性 hash 有效解决了分布式数据的扩容问题。
建表语句:
CREATE TABLE `sharding_by_murmur` ( `id` int(10) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表:
<schema name="test" checkSQLschema="false" sqlMaxLimit="100"> <table name="sharding_by_murmurhash" primaryKey="id" dataNode="dn$1-3" rule="sharding-by-murmur" /> </schema>
分片规则:
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>qs-murmur</algorithm>
</rule>
</tableRule>
分片算法:
<function name="qs-murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">3</property>
<property name="virtualBucketTimes">160</property>
</function>
测试语句:
INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (1, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (2, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (3, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (4, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (5, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (6, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (7, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (8, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (9, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (10, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (11, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (12, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (13, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (14, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (15, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (16, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (17, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (18, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (19, database()); INSERT INTO `sharding_by_murmur` (id,db_nm) VALUES (20, database());
特点:可以一定程度减少数据的迁移。
十进制取模分片:
根据分片键进行十进制求模运算。
<tableRule name="mod-long">
<rule>
<columns>sid</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
特点:分布均匀,但是迁移工作量比较大
固定分片哈希
这是先求模得到逻辑分片号,再根据逻辑分片号直接映射到物理分片的一种散列算 法。
建表语句:
CREATE TABLE `sharding_by_long` ( `id` int(10) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
逻辑表:
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="sharding_by_long" dataNode="dn$1-3" rule="qs-sharding-by-long" />
</schema>
分片规则:
<tableRule name="qs-sharding-by-long">
<rule>
<columns>id</columns>
<algorithm>qs-sharding-by-long</algorithm>
</rule>
</tableRule>
平均分成 8 片(%1024 的余数,1024=128*8):
<function name="qs-sharding-by-long" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
* partitionCount 为指定分片个数列表。
* partitionLength 为分片范围列表。

第二个例子:
两个数组,分成不均匀的 3 个节点(%1024 的余数,1024=2*256+1*512):
<function name="qs-sharding-by-long" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
3 个节点,对 1024 取模余数的分布:

测试语句:
INSERT INTO `sharding_by_long` (id,db_nm) VALUES (222, database()); INSERT INTO `sharding_by_long` (id,db_nm) VALUES (333, database()); INSERT INTO `sharding_by_long` (id,db_nm) VALUES (666, database());
特点:在一定范围内 id 是连续分布的。
取模范围分片
逻辑表:
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="sharding_by_pattern" primaryKey="id" dataNode="dn$0-10" rule="qs-sharding-by-pattern" />
</schema>
建表语句:
CREATE TABLE `sharding_by_pattern` ( `id` varchar(20) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
分片规则:
<tableRule name="sharding-by-pattern">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
分片算法:
<function name="sharding-by-pattern" class=" io.mycat.route.function.PartitionByPattern">
<property name="patternValue">100</property>
<property name="defaultNode">0</property>
<property name="mapFile">partition-pattern.txt</property>
</function>
patternValue 取模基数,这里设置成 100
partition-pattern.txt,一共 3 个节点
id=19%100=19,在 dn1;
id=222%100=22,dn2;
id=371%100=71,dn3
# id partition range start-end ,data node index ###### first host configuration 1-20=0 21-70=1 71-100=2 0-0=0
测试语句:
INSERT INTO `sharding_by_pattern` (id,db_nm) VALUES (19, database()); INSERT INTO `sharding_by_pattern` (id,db_nm) VALUES (222, database()); INSERT INTO `sharding_by_pattern` (id,db_nm) VALUES (371, database());
特点:可以调整节点的数据分布。
范围取模分片:
建表语句:
CREATE TABLE `sharding_by_rang_mod` ( `id` bigint(20) DEFAULT NULL, `db_nm` varchar(20) DEFAULT NULL ) ENGINE=InnoDB
逻辑表:
<schema name="test" checkSQLschema="false" sqlMaxLimit="100">
<table name="sharding_by_rang_mod" dataNode="dn$1-3" rule="qs-sharding-by-rang-mod" />
</schema>
分片规则:
<tableRule name="qs-sharding-by-rang-mod">
<rule>
<columns>id</columns>
<algorithm>qs-rang-mod</algorithm>
</rule>
</tableRule>
分片算法:
<function name="qs-rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
partition-range-mod.txt
# range start-end ,data node group size 0-20000=1 20001-40000=2
解读:先范围后取模。Id 在 20000 以内的,全部分布到 dn1。Id 在 20001-40000 的,%2 分布到 dn2,dn3。
插入数据:
INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (666, database()); INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (6667, database()); INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (16666, database()); INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (21111, database()); INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (22222, database()); INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (23333, database()); INSERT INTO `sharding_by_rang_mod` (id,db_nm) VALUES (24444, database());
特点:扩容的时候旧数据无需迁移
其他分片规则:
- 应用指定分片 PartitionDirectBySubString
- 日期范围哈希 PartitionByRangeDateHash
- 冷热数据分片 PartitionByHotDate
也 可 以 自 定 义 分 片 规 则 : extends AbstractPartitionAlgorithm implements RuleAlgorithm。
- 切分规则的选择
步骤:
1、找到需要切分的大表,和关联的表
2、确定分片字段(尽量使用主键),一般用最频繁使用的查询条件
3、考虑单个分片的存储容量和请求、数据增长(业务特性)、扩容和数据迁移 问题。
例如:按照什么递增?序号还是日期?主键是否有业务意义?
一般来说,分片数要比当前规划的节点数要大。
总结:根据业务场景,合理地选择分片规则。
举例:
3.7 亿的数据怎么分表?我是不是分成 3 台服务器?
- 1、一年内到达多少?两年内到达多少?(数据的增长速度)?答:一台设备每秒钟往 3 张表各写入一条数据,一共 4 台设备。每张表一天 86400*4=345600 条。每张表一个月 10368000 条。 分析:增长速度均匀,可以用日期切分,每个月分一张表。
- 2、什么业务?所有的数据都会访问,还是访问新数据为主? 答:访问新数据为主,但是所有的数据都可能会访问到。
- 3、表结构和表数据是什么样的?一个月消耗多少空间? 答:字段不多,算过了,三年数据量有 3.7 亿,30G。 分析:30G 没必要分库,浪费机器。
- 4、访问量怎么样?并发压力大么? 答:并发有一点吧 分析:如果并发量不大,不用分库,只需要在单库分表。不用引入 Mycat 中间件 了。如果要自动路由的话可以用 Sharding-JDBC,否则就是自己拼装表名。
- 5、3 张表有没有关联查询之类的操作? 答:没有。 25 分析:还是拼装表名简单一点。