Zookeeper 的一致性
Zookeeper 的来源
对于 zookeeper 的一致性问题,有很多朋友有疑问,我这边再帮大家从来源层面梳理一遍一致性的问题。上篇,我们讲到了 zookeeper 的来源,是来自于 google chubby。为了解决在分布式环境下,如何从多个 server 中选举出 master server。那么这多个 server 就需要涉及到一致性问题,这个一致性体现的是多个server 就 master 这个投票在分布式环境下达成一致性。简单来说就是最终听谁的。但是在网络环境中由于网络的不可靠性,会存在消息丢失和或者被篡改等问题。所以如何在这样一个环境中快速并且正确的在多个server 中对某一个数据达成一致性并且保证不论发生任何异常,都不会破坏整个系统一致性呢?所以在 Lamport 大神设计了一套 Paxos 的算法,多个 server 基于这个算法就可以达成一致。而 google chubby 就是基于 paxos 算法的实现,用来实现分布式锁服务。并且提供了 master 选举的服务。
Paxos 在 Chubby 中的应用
很多朋友会有疑问,Chubby 和 paxos 算法有什么关系?Chubby 本来应该设计成一个包含 Paxos 算法的协议库,是的应用程序可以基于这个库方便的使用 Paxos 算法,但是它并没有这么做,而是把 Chubby 设计成了一个需要访问中心化节点的分布式锁服务。既然是一个服务,那么它肯定需要是一个高可靠的服务。所以 Chubby 被构建为一个集群,集群中存在一个中心节点(MASTER),采用 Paxos 协议,通过投票的方式来选举一个获得过半票数的服务器作为 Master,在 chubby 集群中,每个服务器都会维护一份数据的副本,在实际的运行过程中, 只有 master 服务器能执行事务操作,其他服务器都是使用paxos协议从master节点同步最新的数据。而 zookeeper 是 chubby 的开源实现,所以实现原理和 chubby 基本是一致的。
Zookeeper 的一致性是什么情况?
Zookeeper 的一致性,体现的是什么一致呢?
根据前面讲的 zab 协议的同步流程,在 zookeeper 集群内部的数据副本同步,是基于过半提交的策略,意味着它是最终一致性。并不满足强一致的要求。其实正确来说,zookeeper 是一个顺序一致性模型。由于 zookeeper 设计出来是提供分布式锁服务,那么意味着它本身需要实现顺序一致性( http://zookeeper.apache.org/doc/r3.5.5/zookeeperProgrammers.html#ch_zkGuarantees )顺序一致性是在分布式环境中实现分布式锁的基本要求,比如当一个多个程序来争抢锁,如果 clientA 获得锁以后,后续所有来争抢锁的程序看到的锁的状态都应该是被 clientA 锁定了,而不是其他状态。
什么是顺序一致性呢?
在讲顺序一致性之前,咱们思考一个问题,假如说 zookeeper 是一个最终一致性模型,那么他会发生什么情况ClientA/B/C 假设只串行执行, clientA 更新 zookeeper 上的一个值 x。ClientB 和 clientC 分别读取集群的不同副本,返回的 x 的值是不一样的。clientC 的读取操作是发生在 clientB 之后,但是却读到了过期的值。很明显,这是一种弱一致模型。如果用它来实现锁机制是有问题的。
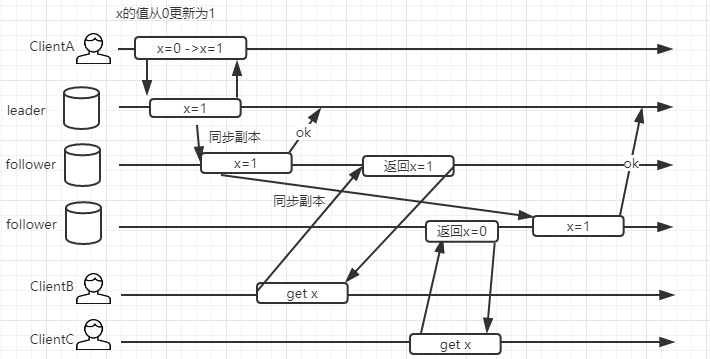
顺序一致性提供了更强的一致性保证,我们来观察下面这个图,从时间轴来看,B0 发生在 A0 之前,读取的值是 0,B2 发生在 A0 之后,读取到的x 的值为 1.而读操作 B1/C0/C1 和写操作 A0 在时间轴上有重叠,因此他们可能读到旧的值为 0,也可能读到新的值 1. 但是在强顺序一致性模型中,如果 B1 得到的 x 的值为 1,那么 C1 看到的值也一定是 1.
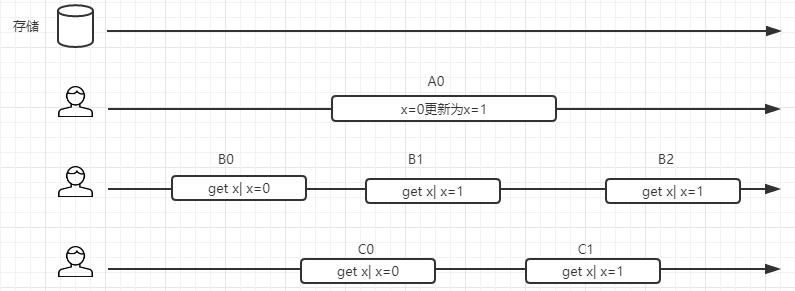
需要注意的是:由于网络的延迟以及系统本身执行请求的不确定性,会导致请求发起的早的客户端不一定会在服务端执行得早。最终以服务端执行的结果为准。简单来说:顺序一致性是针对单个操作,单个数据对象。属于 CAP 中 C这个范畴。一个数据被更新后,能够立马被后续的读操作读到。但是 zookeeper 的顺序一致性实现是缩水版的,在下面这个网页中,可以看到官网对于一致性这块做了解释http://zookeeper.apache.org/doc/r3.5.5/zookeeperProgrammers.html#ch_zkGuaranteeszookeeper 不保证在每个实例中,两个不同的客户端具有相同的zookeeper 数据视图,由于网络延迟等因素,一个客户端可能会在另外一个客户端收到更改通知之前执行更新,考虑到 2 个客户端 A 和 B 的场景,如果 A 把 znode /a 的值从 0 设置为1,然后告诉客户端 B 读取 /a, 则客户端 B 可能会读取到旧的值 0,具体取决于他连接到那个服务器,如果客户端 A 和 B 要读取必须要读取到相同的值,那么 client B 在读取操作之前执行 sync 方法。
除此之外,zookeeper 基于 zxid 以及阻塞队列的方式来实现请求的顺序一致性。如果一个 client 连接到一个最新的 follower 上,那么它 read 读取到了最新的数据,然后 client 由于网络原因重新连接到 zookeeper 节点,而这个时候连接到一个还没有完成数据同步的 follower 节点,那么这一次读到的数据不就是旧的数据吗?实际上 zookeeper 处理了这种情况,client 会记录自己已经读取到的最大的 zxid,如果 client 重连到 server 发现 client 的 zxid 比自己大。连接会失败。
Single System Image 的理解
zookeeper 官网还说它保证了“Single System Image”,其解释为“A clientwill see the same view of the service regardless of the server that itconnects to.”。实际上看来这个解释还是有一点误导性的。其实由上面 zxid的原理可以看出,它表达的意思是“client 只要连接过一次 zookeeper,就不会有历史的倒退”。https://github.com/apache/zookeeper/pull/931
leader 选举的原理
接下来再我们基于源码来分析 leader 选举的整个实现过程。
leader 选举存在与两个阶段中,一个是服务器启动时的 leader 选举。 另一个是运行过程中 leader 节点宕机导致的 leader 选举 ;在开始分析选举的原理之前,先了解几个重要的参数服务器 ID(myid)
比如有三台服务器,编号分别是 1,2,3。
编号越大在选择算法中的权重越大。
zxid 事务 id 值越大说明数据越新,在选举算法中的权重也越大。
逻辑时钟(epoch – logicalclock)或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步 leader 状态,参与投票。
- OBSERVING,观察状态,同步 leader 状态,不参与投票。LEADING,领导者状态。
- LEADING,领导者状态。
服务器启动时的 leader 选举
每个节点启动的时候状态都是 LOOKING,处于观望状态,接下来就开始进行选主流程。
若进行 Leader 选举,则至少需要两台机器,这里选取 3 台机器组成的服务器集群为例。在集群初始化阶段,当有一台服务器 Server1 启动时,其单独无法进行和完成 Leader 选举,当第二台服务器 Server2 启动时,此时两台机器可以相互通信,每台机器都试图找到 Leader,于是进入 Leader选举过程。选举过程如下:
(1) 每个 Server 发出一个投票。由于是初始情况,Server1 和 Server2 都会将自己作为 Leader 服务器来进行投票,每次投票会包含所推举的服务器的 myid 和 ZXID、epoch,使用(myid, ZXID,epoch)来表示,此时 Server1 的投票为(1, 0),Server2 的投票为(2, 0),然后各自将这个投票发给集群中其他机器。
(2) 接受来自各个服务器的投票。集群的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自LOOKING 状态的服务器。
(3) 处理投票。针对每一个投票,服务器都需要将别人的投票和自己的投票进行 PK,PK 规则如下
- 优先比较 epoch
- 其次检查 ZXID。ZXID 比较大的服务器优先作为 Leader
- 如果 ZXID 相同,那么就比较 myid。myid 较大的服务器作为Leader 服务器。
对于 Server1 而言,它的投票是(1, 0),接收 Server2 的投票为(2, 0),首先会比较两者的 ZXID,均为 0,再比较 myid,此时 Server2 的myid 最大,于是更新自己的投票为(2, 0),然后重新投票,对于
Server2 而言,其无须更新自己的投票,只是再次向集群中所有机器发出上一次投票信息即可。
(4) 统计投票。每次投票后,服务器都会统计投票信息,判断是否已经有过半机器接受到相同的投票信息,对于 Server1、Server2 而言,都统计出集群中已经有两台机器接受了(2, 0)的投票信息,此时便认为已经选出了 Leader。
(5) 改变服务器状态。一旦确定了 Leader,每个服务器就会更新自己的状态,如果是 Follower,那么就变更为 FOLLOWING,如果是 Leader,就变更为 LEADING。
运行过程中的 leader 选举
当集群中的 leader 服务器出现宕机或者不可用的情况时,那么整个集群将无法对外提供服务,而是进入新一轮的 Leader 选举,服务器运行期间的 Leader 选举和启动时期的 Leader 选举基本过程是一致的。
(1) 变更状态。Leader 挂后,余下的非 Observer 服务器都会将自己的服务器状态变更为 LOOKING,然后开始进入 Leader 选举过程。
(2) 每个 Server 会发出一个投票。在运行期间,每个服务器上的 ZXID 可能不同,此时假定 Server1 的 ZXID 为 123,Server3 的 ZXID 为 122;在第一轮投票中,Server1 和 Server3 都会投自己,产生投票(1, 123),(3, 122),然后各自将投票发送给集群中所有机器。接收来自各个服务器的投票。与启动时过程相同。
(3) 处理投票。与启动时过程相同,此时,Server1 将会成为 Leader。
(4) 统计投票。与启动时过程相同。
(5) 改变服务器的状态。与启动时过程相同。

leader 选举的源码分析
源码分析,最关键的是要找到一个入口,对于 zk 的 leader 选举,并不是由客户端来触发,而是在启动的时候会触发一次选举。因此我们可以直接
去看启动脚本 zkServer.sh 中的运行命令,ZOOMAIN 就是 QuorumPeerMain。那么我们基于这个入口来看:

QuorumPeerMain.main 方法
main 方法中,调用了 initializeAndRun 进行初始化并且运行
protected void initializeAndRun(String[] args) throws ConfigException, IOException{
//这段代码比较简单,设置配置参数,如果 args 不为空,可以基于外部的配置路径来进行解析
QuorumPeerConfig config = new QuorumPeerConfig();
if (args.length == 1) {
config.parse(args[0]);
}
// 这里启动了一个线程,来定时对日志进行清理,从命名来看也很容易理解
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config.getDataDir(),
config.getDataLogDir(), config.getSnapRetainCount(), config.getPurgeInterval());
purgeMgr.start();
//如果是集群模式,会调用 runFromConfig.servers 实际就是我们在 zoo.cfg 里面配置的集群节点
if (a config.servers.size() > 0) {
runFromConfig(config);
} else {//否则直接运行单机模式
LOG.warn("Either no config or no quorum defined in config, running " + " in standalone mode");
// there is only server in the quorum -- run as standalone
ZooKeeperServerMain.main(args);
}
}
runFromConfig
从名字可以看出来,是基于配置文件来进行启动。
所以整个方法都是对参数进行解析和设置 ,因为这些参数暂时还没用到,所以没必要去看。直接看核心的代码quorumPeer.start(), 启动一个线程,那么从这句代码可以看出来QuorumPeer 实际是继承了线程。那么它里面一定有一个 run 方法:
public void runFromConfig(QuorumPeerConfig config) throws IOException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
try {
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns());
quorumPeer = getQuorumPeer();
quorumPeer.setQuorumPeers(config.getServers());
quorumPeer.setTxnFactory(new FileTxnSnapLog( new File(config.getDataLogDir()), new File(config.getDataDir())));
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
//投票决定方式,默认超过半数就通过
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setQuorumVerifier(config.getQuorumVerifi er());
quorumPeer.setClientPortAddress(config.getClientPor tAddress());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
// sets quorum sasl authentication
configurationsquorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if(quorumPeer.isQuorumSaslAuthEnabled()){
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
//启动主线程
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
}
}
QuorumPeer.start
QuorumPeer.start 方法,重写了 Thread 的 start。也就是在线程启动之前,会做以下操作
1. 通过 loadDataBase 恢复快照数据
2. cnxnFactory.start() 启动 zkServer,相当于用户可以通过 2181 这个端口进行通信了,这块后续在讲。我们还是以 leader 选举为主线
@Override
public synchronized void start() {
loadDataBase();
cnxnFactory.start();
startLeaderElection();
super.start();
}
startLeaderElection
看到这个方法,有没有两眼放光的感觉?没错,前面铺垫了这么长,终于进入 leader 选举的方法了
synchronized public void startLeaderElection() {
try {
// 构建一个票据,用于投票
currentVote = new Vote(myid, getLastLoggedZxid(), getCurrentEpoch());
} catch (IOException e) {
RuntimeException re = new RuntimeException(e.getMessage());
re.setStackTrace(e.getStackTrace());
throw re;
}
// 这个 getView 返回的就是在配置文件中配置的server.myid=ip:port:port。view 在哪里解析的呢?
for (QuorumServer p : getView().values()) {
if (p.id == myid) {// 获得当前 zkserver myid 对应的 ip 地址
myQuorumAddr = p.addr;
break;
}
}
if (myQuorumAddr == null) {
throw new RuntimeException("My id " + myid + " not in the peer list");
} // 根据 electionType 匹配对应的选举算法,electionType 默认值为 3.可以在配置文件中动态配置
if (electionType == 0) {
try {
udpSocket = new DatagramSocket(myQuorumAddr.getPort());
responder = new ResponderThread();
responder.start();
} catch (SocketException e) {
throw new RuntimeException(e);
}
}
this.electionAlg = createElectionAlgorithm(electionType);
}
quorumPeer. createElectionAlgorithm
根据对应的标识创建选举算法
protected Election createElectionAlgorithm(int electionAlgorithm) {
Election le = null;
// TODO: use a factory rather than a switch
switch (electionAlgorithm) {
case 0:
le = new LeaderElection(this);
break;
case 1:
le = new AuthFastLeaderElection(this);
break;
case 2:
le = new AuthFastLeaderElection(this, true);
break;
case 3:
qcm = createCnxnManager();
QuorumCnxManager.Listener listener = qcm.listener;
if (listener != null) {
listener.start(); // 启动监听器,这个监听具体做什么的暂时不管,后面遇到需要了解的地方再回过头来看
le = new FastLeaderElection(this, qcm);// 初始化 FastLeaderElection
} else {
LOG.error("Null listener when initializing cnx manager");
}
break;
default:
assert false;
}
return le;
}
FastLeaderElection
初始化FastLeaderElection,QuorumCnxManager 是一个很核心的对象,用来实现领导选举中的网络连接管理功能,这个后面会用到
public FastLeaderElection(QuorumPeer self, QuorumCnxManager manager){
this.stop = false;
this.manager = manager;
starter(self, manager);
}
FastLeaderElection. starter
starter 方法里面,设置了一些成员属性,并且构建了两个阻塞队列,分别是 sendQueue 和 recvqueue。并且实例化了一个 Messager
private void starter(QuorumPeer self, QuorumCnxManager manager) {
this.self = self;
proposedLeader = -1;
proposedZxid = -1;
sendqueue = new LinkedBlockingQueue<ToSend>();
recvqueue = new LinkedBlockingQueue<Notification>();
this.messenger = new Messenger(manager);
}
Messenger
在 Messenger 里面构建了两个线程,一个是 WorkerSender,一个是WorkerReceiver。 这两个线程是分别用来发送和接收消息的线程。具体做什么,暂时先不分析。
Messenger(QuorumCnxManager manager) {
this.ws = new WorkerSender(manager);
Thread t = new Thread(this.ws,
"WorkerSender[myid=" + self.getId() + "]");
t.setDaemon(true);
t.start();
this.wr = new WorkerReceiver(manager);
t = new Thread(this.wr,
"WorkerReceiver[myid=" + self.getId() + "]");
t.setDaemon(true);
t.start();
}
阶段性总结
ok,分析到这里,先做一个简单的总结,通过一个流程图把前面部分的功能串联起来。
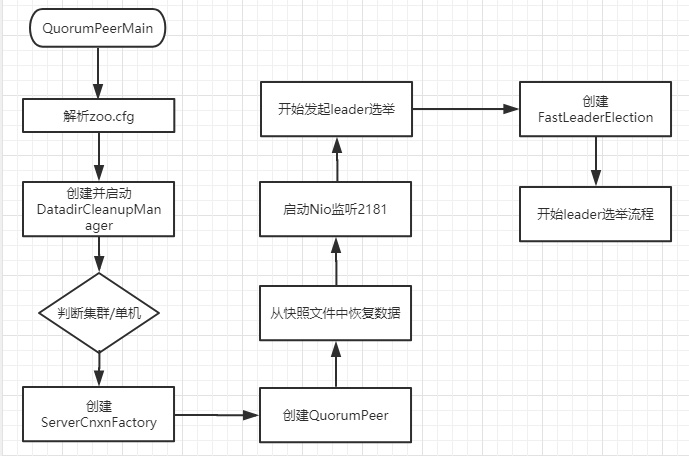
至此,先做如上总结~