以下所有的内容基于eSpeak1.06 的移植过程
1. 分析下espeak.c 文件先写的main 函数,大致就是初始化,设置回调函数,转换文件,里面的具体参数还不了解。
目前还存在的问题,怎么支持中文,源码里面的 非 C 非 H 的文件怎么放到工程中
void espeak_trans_text()
{
int synth_flags = espeakCHARS_AUTO | espeakPHONEMES | espeakENDPAUSE;
const char* sText = "tralalalallala";
char file_type[] = ".wav";
//初始化
//nRate 是什么?
samples_split = espeak_Initialize(AUDIO_OUTPUT_SYNCHRONOUS, 10000, NULL, 0);
samples_split = samplerate * samples_split_seconds;
espeak_SetSynthCallback(SynthCallback);
espeak_SetParameter(espeakRATE, 175, 0);
espeak_Synth(sText,15,0,POS_CHARACTER,0,synth_flags,NULL,NULL);
espeak_Terminate();
}
2. 关键应该是这个回调函数
wav代表什么? 从下面的写函数 推测出 fwrite(wav,numsamples*2,1,f_wavfile); ,推测出 wav就是 音频数据,写到文件中,但是为啥要乘以2。
numsamples就是 音频数据的长度/2
还要处理两个事件,不懂
FILE *f_wavfile = NULL; 应该就是生成的.wav文件了。
samples_split 是样本
filetype 文件类型,已经提取是 .wav
samples_split = samples_split_seconds * samplerate; 怎么看,样本数就是 时间 乘以 采样率,解释的通,距离=时间乘以速度。类似的
跟下面的对不上啊 sprintf(fname,"%s_%.2d%s",wavefile,wavefile_count+1,filetype); 应该是多个 文件, hello01.wav,hello02.wav,是不是文件大小有限制,超过了,就生成多个文件,那么为啥用samples_split大于0 ,就分割了? 这里是个疑问?
不对,sentence 句子,下面说了,文件有限制,超过的话需要分割,那么分割的是samples_split_seconds ,就是制定 几秒大小的wav文件,超过了就分成多个,那么为啥我测试的时候,只能一个单词,不科学啊?以后再研究吧,难道是参数不对?
static int SynthCallback(short *wav, int numsamples, espeak_EVENT *events)
{//========================================================================
char fname[210];
//if(quiet) return(0); // -q quiet mode,应该是命令的
if(wav == NULL)
{
CloseWavFile(); //wav代表什么
return(0);
}
while(events->type != 0) //事件类型
{
if(events->type == espeakEVENT_SAMPLERATE) //取样频率
{
samplerate = events->id.number;
samples_split = samples_split_seconds * samplerate;
}
else
if(events->type == espeakEVENT_SENTENCE) //宣判,什么意思?
{
// start a new WAV file when the limit is reached, at this sentence boundary
if((samples_split > 0) && (samples_total > samples_split))
{
CloseWavFile();
samples_total = 0;
wavefile_count++;
}
}
events++;
}
if(f_wavfile == NULL)
{
if(samples_split > 0) //样本
{
sprintf(fname,"%s_%.2d%s",wavefile,wavefile_count+1,filetype);
if(OpenWavFile(fname, samplerate) != 0)
return(1);
}
else
{
if(OpenWavFile(wavefile, samplerate) != 0)
return(1);
}
}
if(numsamples > 0)
{
samples_total += numsamples;
fwrite(wav,numsamples*2,1,f_wavfile);
}
return(0);
}
3. fflush 函数,会强迫将缓冲区的数据写会参数stream 指定的文件中。是文件系统中的文件吗?
stout 是什么?一个宏,应该是指定某个文件!
函数 ftell 用于得到文件位置指针当前位置相对于文件首的偏移字节数。
static void CloseWavFile()
{
unsigned int pos;
if((f_wavfile==NULL) || (f_wavfile == stdout))
return;
fflush(f_wavfile);
pos = ftell(f_wavfile);
fseek(f_wavfile,4,SEEK_SET);
Write4Bytes(f_wavfile,pos - 8);
fseek(f_wavfile,40,SEEK_SET);
Write4Bytes(f_wavfile,pos - 44);
fclose(f_wavfile);
f_wavfile = NULL;
} // end of CloseWavFile
4. 看下,wave_hdr 应该是 wav 文件的格式,这个文件的头应该是这样的,我找个试试
定义函数:int isspace(int c);
函数说明:检查参数c是否为空格字符,也就是判断是否为空格(' ')、定位字符(' ')、CR('
')、换行('
')、垂直定位字符(' v ')或翻页(' f ')的情况。
int OpenWavFile(char *path, int rate)
{
static unsigned char wave_hdr[44] = {
'R','I','F','F',0x24,0xf0,0xff,0x7f,'W','A','V','E','f','m','t',' ',
0x10,0,0,0,1,0,1,0, 9,0x3d,0,0,0x12,0x7a,0,0,
2,0,0x10,0,'d','a','t','a', 0x00,0xf0,0xff,0x7f};
if(path == NULL)
return(2);
while(isspace(*path)) path++;
f_wavfile = NULL;
if(path[0] != 0)
{
if(strcmp(path,"stdout")==0)
f_wavfile = stdout;
else
f_wavfile = fopen(path,"wb");
}
if(f_wavfile == NULL)
{
fprintf(stderr,"Can't write to: '%s'
",path);
return(1);
}
fwrite(wave_hdr,1,24,f_wavfile);
Write4Bytes(f_wavfile,rate);
Write4Bytes(f_wavfile,rate * 2);
fwrite(&wave_hdr[32],1,12,f_wavfile);
return(0);
}
打开winhex 看看,对比了
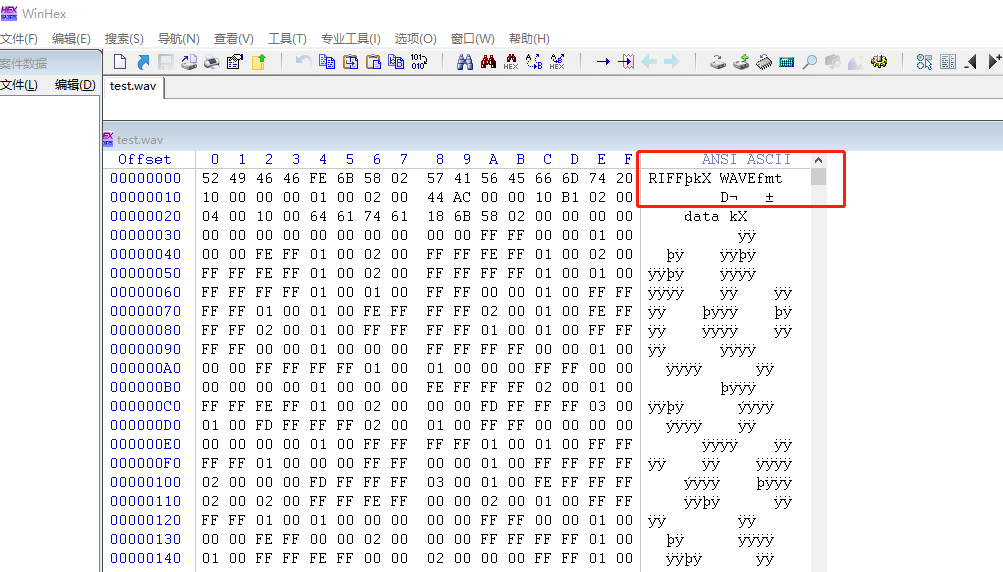
对比下文档的说明

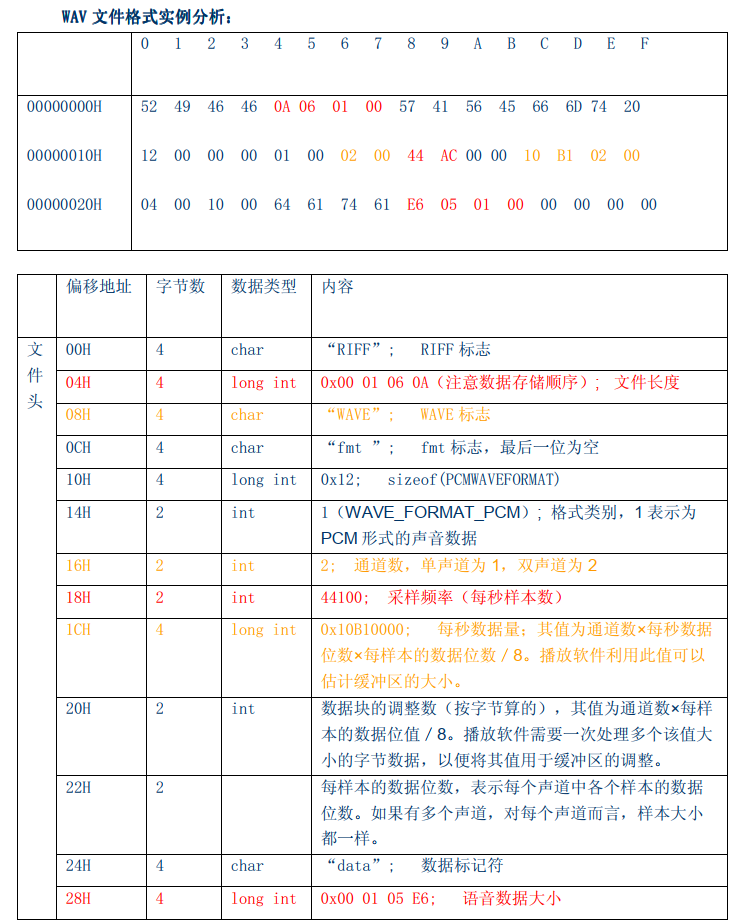
查询文件的长度,像是标准Linux 的写法
int GetFileLength(const char *filename)
{//====================================
struct stat statbuf;
if(stat(filename,&statbuf) != 0)
return(0);
if((statbuf.st_mode & S_IFMT) == S_IFDIR)
return(-2); // a directory
return(statbuf.st_size);
} // end of GetFileLength
播放声音的函数