大家可以关注一下我的博客 我的博客所有随笔都是我从基础开始学习java的所有知识点
--数值型函数 --四舍五入round(x,y)对x保留y为小数 --四舍五入数值 select round(23.225) from dual; --输出结果:24 --四舍五入(小数点后保留1位小数)数值 select round(23.652,1)from dual; --输出结果:23.7 --四舍五入(四舍五入到小数点前1位小数)数值 select round(25.2466,-1)from dual; --输出结果:30 -- 返回x按精度y截取后的值 --未四舍五入的值 select trunc(23.621) from dual; --输出结果:23 select trunc(14.562,1)from dual; --输出结果:14.5 select trunc(15.25,-1) from dual; --输出结果:10 -- mod(x,y)求余数 select mod(9,2)from dual; --输出结果:1 -- ceil 向上取整 select ceil(1.8)from dual; --输出结果:2 -- floor 向下取整 select floor(1.8)from dual; --输出结果:1
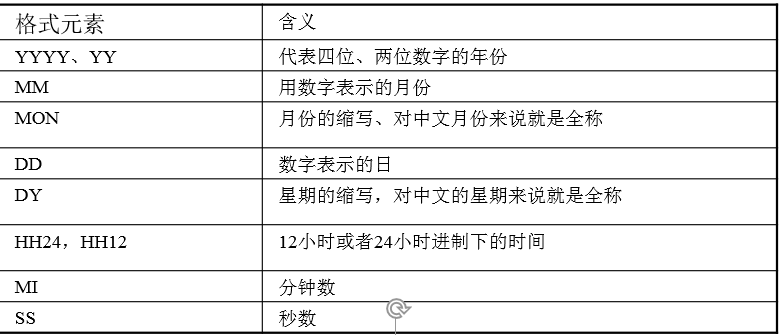
----------------------------------------------------- --------------------------------日期函数 -- 返回系统当前时间 select sysdate from dual; -- 返回当前会话时区中的当前日期 select current_date from dual; -- 添加月数(在当前时间上加一个月) select add_months(sysdate,1)from dual; -- 返回两个时间相差的月数 select months_between(sysdate,add_months(sysdate,1))from dual; -- 需求:查询工作年限在30年以上 select e.ename,e.hiredate from emp e where months_between(sysdate,e.hiredate)/12>30; -- 返回date所在月份最后的一天 select last_day(sysdate)from dual; -- next_day(date1,week) 返回date1下周星期几的日期 select next_day(sysdate,'星期一') from dual; -- 查询会话的环境参数(我的是china) select * from nls_session_parameters; -- 日期计算(oracle的时间计算单位为天) --明天的此时 select sysdate+1 from dual; --前天的此时 select sysdate-2 from dual;------------------------------------------------ --转换函数 --转换函数就是把字符、日期、数值型数据进行相互转换。类型转换分两种:隐式类型转换和显式类型转换 --隐式类型转换 --字符和数字/日期之间的隐式转换 -- 字符隐式转换成数值 select '100'-10 from dual; -- 字符隐式转化为日期 --DD-MON-RR默认的日期格式 select 1 from dual where sysdate>'13-1月-19'; -- 查date format格式 select * from nls_session_parameters
------------显示类型转换 -- to_char -- 【1】把日期转化成字符 -- 按照默认格式DD-MON-RR select to_char(sysdate) from dual; -- 按指定格式(格式查文档) select to_char(sysdate,'YYYY"年"MM"月"DD"日" HH24:MI:SS') as "时间" from dual; --输出结果:2019年05月14日 19:34:50 -- 【2】把数值格式化成字符串 select to_char(12345,'999999.99')from dual; --输出结果: 12345.00 select to_char(1230.45,'9999999.9999')from dual; --输出结果:1230.4500 select to_char(1255.55,'0000000.0000000')from dual; --输出结果: 0001255.5500000 select to_char(12345,'$00000.0000')from dual; --输出结果: $12345.0000 --需求:把18612341234格式化成186-1234-1234 select replace(to_char(18612341234,'999,9999,9999'),',','-') from dual; ---------- to_number select to_number('$12,345','$99,999')from dual; --输出结果:12345 ----------------- to_date select to_date('14-1月-19','DD-MON-RR') from dual; --输出结果:2019/1/14 select to_date('2004-08-27','YYYY-MM-DD') from dual; --输出结果:2004/8/27 ----------------函数可以嵌套 -- 查询雇用期满6个月的下一个周一的日期。 select e.hiredate,next_day(add_months(e.hiredate,6),'星期一')from emp e where months_between(sysdate,e.hiredate)>6; -------------------------------decode/case when --decode(条件,值1,“返回值1”, 值2,“返回值2”,,,“默认值”) -- 需求:查询员工所在的部门名称 select e.ename,e.deptno,decode(e.deptno,10,'部门1',20,'部门2',30,'部门3','未知')from emp e; ---------case when X then 'y'else ''... end select e.ename,e.deptno,case e.deptno when 10 then '部门1' when 20 then '部门2' when 30 then '部门3' else '未知' end from emp e; -- 需求:对各个部门进行涨薪,10->1.1 20->1.2 30->1.3 其他->1.0 select e.deptno,e.ename,e.sal as "涨薪前", decode(e.deptno,10,e.sal*1.1,20,e.sal*1.2,30,e.sal*1.3) as "涨薪后" from emp e; -- 需求:根据工资分布输出以下信息 /* <1000 真屌丝 (1001,2000] 屌丝 (2001,3000] 白领 (3001,5000] 高富帅 (5001,10000] 土豪 */ select e.ename "姓名" ,e.sal "工资", case when e.sal<=1000 then '真屌丝' when e.sal<=2000 then '屌丝' when e.sal<=3000 then '白领' when e.sal<=5000 then '高富帅' when e.sal<=10000 then '土豪' else '未知' end "描述" from emp e; -----------------------------总结: --decode 多用于等值匹配;case when可以用于等值,多用于条件分支。
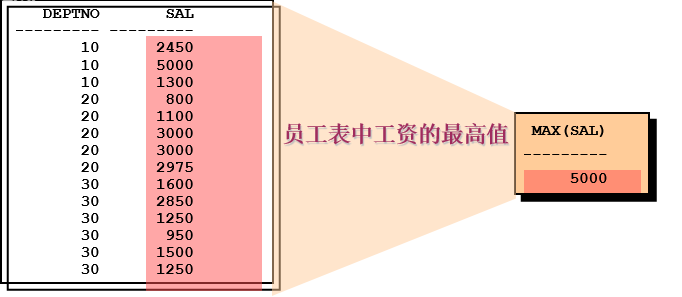
----------------------------------组函数 --组函数把多行数据经过运算后返回单个值。也称聚合函数。 -- 求公司雇员的数量 --count 字段的总数(一般指定主键,指定某个字段时,null会被忽略不计,但*会计) select count(*) from emp e; select count(e.empno) from emp e; select count(1) from emp e; -- avg:对多个记录的某个字段求平均值 -- 需求:求底薪的平均值 select avg(e.sal) from emp e; -- max/min需求:求雇员的最高薪资/最低薪资 select max(e.sal),min(e.sal),avg(e.sal) from emp e; -- sum(总数) 需求:求公司一个月的员工基本开销 select sum(e.sal) from emp e;
-- 最早入职的员工
select e.ename,e.hiredate
from emp e
where e.hiredate = (select min(e.hiredate) from emp e);
--------------------------------注意: --[1] 组函数或聚合函数是对一个数据集(表数据、查询出来的表、分组的表)进行聚合。 --[2] 聚合函数对字段是null的值进行忽略。count(*) --[3] max/min 适合任意数据类型,sum/avg 只适用于数值类型。 --聚合函数的结果可以作为其他查询条件。
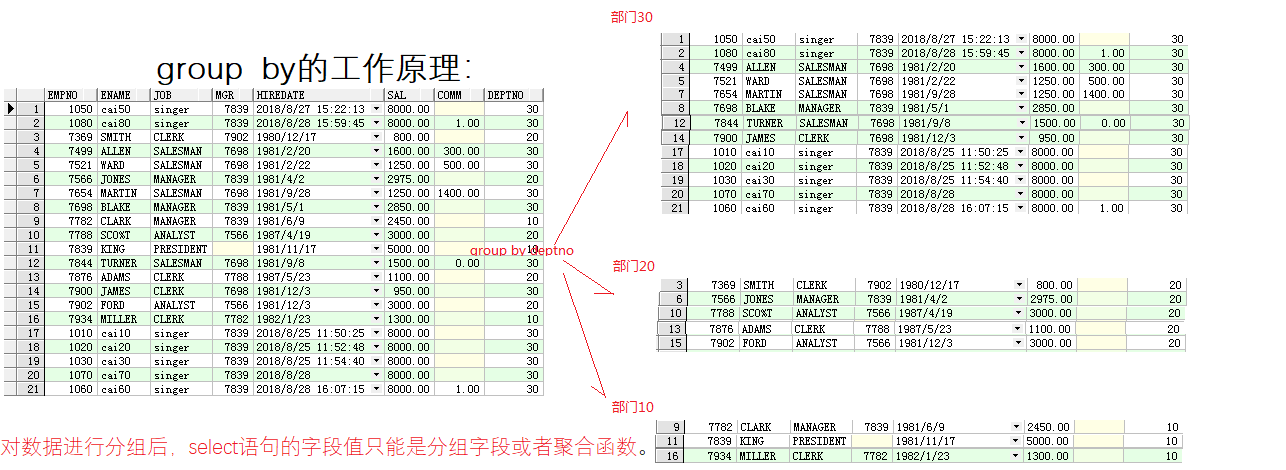
----------------------------------------分组(group by) /*在处理统计或聚合数据时,很多时候需要对数据进行分组 语法 select field1,。。。 from tableName group by field1[,field2,…] 按照field1[,field2,…] 分组,字段值相同的记录分到一组。*/ ----------------------[1]分组和聚合函数 -- 需求:统计部门10的人数 select count(1) from emp e where e.deptno=10; -- 需求:求各个部门的人数 select e.deptno,count(e.ename) from emp e group by e.deptno; group by e.deptno; -- 需求:求各个部门的平均薪资 select e.deptno,avg(e.sal) from emp e group by e.deptno; -- 需求:求各个部门的月收入平均值 select e.deptno,avg(e.sal+nvl(e.comm,0)) from emp e group by e.deptno; -- ----------特例:按照津贴分组(所以null统一分为一组) select e.comm,count(1) from emp e group by e.comm; -----------------------------having --如果需要对分组的数据进行条件过滤,必须使用having!!! -- group by having -- 查询部门平均薪资大于3000的部门 select e.deptno from emp e group by e.deptno having avg(e.sal)>3000; -- 查询部门薪资大于3000的雇员按部门分组的平均薪资 select e.deptno,avg(e.sal) from emp e where e.sal>3000 group by e.deptno; --注意: --[1] Where过滤行,having过滤分组。 --[2] Having支持所有where操作符。 --对数据进行分组后,select语句的字段值只能是分组字段或者聚合函数。 ---------------------排序 (order by) /*排序 (order by)(select field1, field2,。。。 from tablename order by field1,field2 对数据集进行排序,先按field1排序,如果field1排序相同,按照field2排序,依次类推。 -asc 升序,默认 -desc 降序*/ -- order by -- 需求:按雇员薪资排序 select e.ename,e.sal from emp e order by e.sal desc; -----------order by 一般都是最后执行。 --薪资大于1200的雇员 所在部门的平均薪资大于1500的部门,按照平均薪资升序排序 select e.deptno,avg(e.sal) from emp e where e.sal>1200 group by e.deptno having avg(e.sal)>1500 order by avg(e.sal) asc ; ---------order by 既可以用于数据行(记录)排序。也可以对分组的结果进行排序,此时需要聚合函数配合。 --Select 语言的执行顺序 /*1.读取from子句中的基本表、视图的数据,[执行笛卡尔积操作]。 2.选取满足where子句中给出的条件表达式的元组 3.按group子句中指定列的值分组,同时提取满足Having子句中组条件表达式的那些组 4.按select子句中给出的列名或列表达式求值输出 5.Order by子句对输出的目标表进行排序。 from -> where -> group by -> having -> select -> order by */ --交集、全集、并集、差集 -- 并集:把集合A的结果和集合B的结果合并,并去掉重复的记录。 select e.* from emp e where e.deptno = 10 union select e.* from emp e where e.deptno = 20; -- 有重复记录取并集 select e.* from emp e where e.deptno = 10 or e.deptno = 20 union select e.* from emp e where e.deptno = 20; -- 全集:: 把集合A的结果和集合B的结果合并,保留重复记录 select e.* from emp e where e.deptno = 10 or e.deptno = 20 union all select e.* from emp e where e.deptno = 10; --交集: 把集合A的结果和集合B的结果取相同部门 select e.* from emp e where e.deptno = 10 or e.deptno = 20 intersect select e.* from emp e where e.deptno = 10; --差集: 在集合A的结果中去掉集合B的结果 (A-B) select e.* from emp e where e.deptno = 10 or e.deptno = 20 minus select e.* from emp e where e.deptno = 10; -- 笛卡尔积(两张表合在一起,新表行数等于两张表行数相乘【第一张表的每行加一次第二章表所有行】) select * from emp,dept -- 等值连接 -- 需求:查询雇员的部门名称 select e.ename ,e.deptno ,d.dname from emp e,dept d where e.deptno=d.deptno -- 不等值连接 -- 查询每个雇员的薪资等级 select e.ename,e.sal,s.grade from emp e,salgrade s where e.sal between s.losal and s.hisal --外连接 --左外连接:左边的表作为主表,右边表作为从表,主表数据都显示,从表数据没有,用null填充,用+号表示。 -- 需求:查询所有部门的雇员 select * from dept d,emp e where d.deptno=e.deptno(+) -- 右外连接 --右外连接: 右边的表作为主表,左边表作为从表,主表数据都显示,从表数据没有,用null填充,用+号表示。 select * from emp e,dept d where e.deptno(+) = d.deptno; --自连接 --一个表自身连接自身时,称为自连接。自连接以不同的视角看待同一张表。 -- 查询每个雇员的上级领导 select e.ename "雇员",nvl(m.ename,'boss') "领导" from emp e,emp m where e.mgr = m.empno(+) /*多于两张表的查询 如果有多个表参与查询,先把t1xt2笛卡尔积得到一个大表T1,再把T1xt3笛卡尔积得到一个另外的大表T2,依次类推。 所有的多表查询最终都是两种表的查询。*/