优先队列不是绝对标准的队列实现,每次出队的元素都是优先级最高的元素。不允许添加null元素。
优先队列的元素有两种排序方式:自然排序和定制排序。
自然排序:优先队列集合中元素实现的Comparable接口。
定制排序:创建队列时传进的Comparator对象。
采用了小顶堆的实现方式,保证了每次poll都是最小的元素(也可根据自定义的比较器)。
1.成员变量:
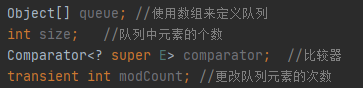
2.构造器:未传入数组的初始化长度则默认长度为11。未传入比较器则默认为null,前提是元素类必须实现了Comparable接口。
//其实上边所说的几种构造器最终会走到该构造器 public PriorityQueue(int initialCapacity, Comparator<? super E> comparator) { //对传入的参数进行判断,小于1则抛出异常 if (initialCapacity < 1) throw new IllegalArgumentException(); //初始化数组 this.queue = new Object[initialCapacity]; this.comparator = comparator; }
传入的是集合:在代码中我们可以看到首先判断集合的类型是否为SortedSet或PriorityQueue,因为这两个类元素类实现了Comparable接口或者定义的时候传进了Comparator对象。所以比较器一定不为空
public PriorityQueue(Collection<? extends E> c) { if (c instanceof SortedSet<?>) { SortedSet<? extends E> ss = (SortedSet<? extends E>) c; this.comparator = (Comparator<? super E>) ss.comparator(); initElementsFromCollection(ss); } else if (c instanceof PriorityQueue<?>) { java.util.PriorityQueue<? extends E> pq = (java.util.PriorityQueue<? extends E>) c; this.comparator = (Comparator<? super E>) pq.comparator(); initFromPriorityQueue(pq); } else { this.comparator = null; initFromCollection(c); } } private void initElementsFromCollection(Collection<? extends E> c) { //将集合转为数组 Object[] es = c.toArray(); int len = es.length; //若c的运行时类型不为Object,则将该数组转为Object类型 if (es.getClass() != Object[].class) es = Arrays.copyOf(es, len, Object[].class); if (len == 1 || this.comparator != null) for (Object e : es) if (e == null) throw new NullPointerException(); //该方法主要是判断es的长度是否大于0,是就返回该数组,不是则new一个长度为1的Object数组, this.queue = ensureNonEmpty(es); this.size = len; } private void initFromPriorityQueue(PriorityQueue<? extends E> c) { //判断集合类型是否为PriorityQueue,不是则转到initFromCollection方法 if (c.getClass() == PriorityQueue.class) { this.queue = ensureNonEmpty(c.toArray()); this.size = c.size(); } else { initFromCollection(c); } } //此处我们先大概知道heapify是将数组转化成我们想要的堆。 //通过initElementsFromCollection方法已经将集合转为数组了,为什么还要转成我们想要的堆呢? //因为在Sorted集合中数组已经是按我们想要的顺序进行排列,而我们传入的该集合并没有可以让其有顺序的排列的功能,所以还需要调用heapify方法将数组元素的顺序做进一步的转化。 private void initFromCollection(Collection<? extends E> c) { initElementsFromCollection(c); heapify(); }
总结一下:如果没有传入比较器,则元素类必须实现了Comparable接口或者在创建队列时传入Comparator对象。如果没有传入队列的长度就使用源码中的默认初始化长度:11。如果传入的是集合:若集合的类型为SortedSet:转为Object类型的数组;是PriorityQueue则直接转化为数组,因为其本身就是Object类型的数组,无需再做转化;以上两种都不是则先将其转化为Object类型的数组,再调用heapify()进行排序。
3.入队
优先队列内部是以堆来实现的,那我们首先来看看堆是如何添加元素的。(以小顶堆为例)
假如有这样一个数组:1,3,9,8,10 接下来将模拟该数组以堆的方式建立
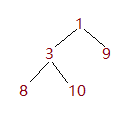 假如想将2添加进去,第一步就是将2先放到数组的最后一位,如图所示
假如想将2添加进去,第一步就是将2先放到数组的最后一位,如图所示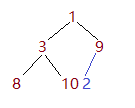
此时2在数组中的下标为5,通过5我们可以计算出其父节点的下标为(5-1)/2 = 2.可以看到2下标对应的数是9。比较后发现子节点的数值小于父节点,不符合小顶堆的定义,所以更换两个数的位置。如图:
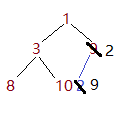 继续比较其与其父节点的大小,2<1,符合小顶堆的定义。至此就添加成功了。接下来将对照源码说明。
继续比较其与其父节点的大小,2<1,符合小顶堆的定义。至此就添加成功了。接下来将对照源码说明。
public boolean add(E e) { return offer(e);//可以看出add()其实也是调用了offer()完成入队操作。 } public boolean offer(E e) { //如果传进来的是null值就抛异常 if (e == null) throw new NullPointerException(); modCount++;//队列操作数+1. int i = size; //如果此时队列已经满了,则调用grow()进行扩容,该方法待会详说 if (i >= queue.length) grow(i + 1); //优先队列并不是按元素添加的顺序排列的,所以不能直接添加到数组的尾部,调用该方法相当于完成刚才添加元素2的操作。 siftUp(i, e); //更新队列长度 size = i + 1; return true; } private void siftUp(int k, E x) { //如果比较器不为空,使用自定义的比较器进行元素的添加 if (comparator != null) siftUpUsingComparator(k, x, queue, comparator); else //比较器为空。其实两者原理相同,我们详说比较器为空的方法。 siftUpComparable(k, x, queue); } //对参数加以说明:k是当前队列的长度(也是新元素添加进来的下标),x是待入队的元素,es是当前队列 private static <T> void siftUpComparable(int k, T x, Object[] es) { Comparable<? super T> key = (Comparable<? super T>) x; while (k > 0) { //通过该表达式得到待添加元素父节点的下标 int parent = (k - 1) >>> 1; Object e = es[parent]; //如果待添加元素的值大于父节点的值,则说明我们找到了新元素待插入的位置,即k,并跳出循环。 if (key.compareTo((T) e) >= 0) break; //如果不是,则将父节点的元素下移,且父节点的下标为待添加元素上移的下标,继续while循环判断当前下标与其父节点的大小。 es[k] = e; k = parent; } //k即为即为我们确定的新节点待插入的位置 es[k] = key; }
其实源码与我们刚才图所示的有点出入,我们发现源码并没有做值得交换,只是一直与其现在所处位置的父节点进行比较,并在满足条件时进行上移,直到找到待插入的位置才将key插入。
上述代码中还有一个方法未提到,grow()。接下来就谈谈优先队列的扩容机制:
private void grow(int minCapacity) { int oldCapacity = queue.length; //可以看到,在调用newLength()这个方法的第三个参数:以旧容量与64的大小做了一个判断:如果旧容量小于64,那么增长因子为2;
若旧容量大于64,那么增长因子就为1.5。
还有一个要说明的是。若传入的minCapacity大于旧容量的2倍,则扩容后的数组的长度为minCapacity。 int newCapacity = ArraysSupport.newLength(oldCapacity, minCapacity - oldCapacity, /* minimum growth */ oldCapacity < 64 ? oldCapacity + 2 : oldCapacity >> 1 /* preferred growth */); queue = Arrays.copyOf(queue, newCapacity); } public static int newLength(int oldLength, int minGrowth, int prefGrowth) { //我们以oldLength=11,minGrowth=1,prefGrowth=13为例 int newLength = Math.max(minGrowth, prefGrowth) + oldLength;//计算得出newLength = 24;即验证了我们刚才所说的增长因子为2:12*2=24。 if (newLength - MAX_ARRAY_LENGTH <= 0) { return newLength; } //当扩容后数组的长度大于MAX_ARRAY_LENGTH则调用hugeLength() return hugeLength(oldLength, minGrowth); }
出队列:
若队列长度为1:返回队顶元素并将队列长度置为0即可。
若队列长度 > 1:队顶元素依然是出队列的元素。不同的是要改变队列元素的位置。
那么问题就来了:如何改变队列元素的位置使其依然是小顶堆呢?
源代码中通过有无比较器调用相对应的方法,但其本质是相同的。
public E poll() { final Object[] es; final E result; //判断队列是否为空 if ((result = (E) ((es = queue)[0])) != null) { modCount++; //队列操作数+1 final int n; //n是当前队列最后一个元素的下标,对应的x就是最后一个元素 final E x = (E) es[(n = --size)]; es[n] = null; 如果n=0:该队列仅有一个元素:x。返回x即可。 if (n > 0) { final Comparator<? super E> cmp; if ((cmp = comparator) == null) siftDownComparable(0, x, es, n); else siftDownUsingComparator(0, x, es, n, cmp); } } return result; }
用图来解释 siftDownComparable()该方法是如何工作的:
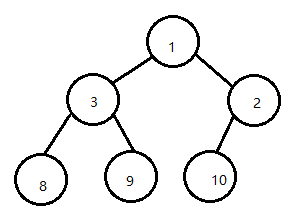 要做的工作是:元素 1 出队列,并将队列的长度-1。
要做的工作是:元素 1 出队列,并将队列的长度-1。
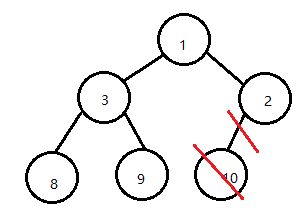 保存队列的最后一个元素 x = 10; n = 5:为队列最后一个元素的下标,half = n/2 = 2:为去除下标对应的元素后第一个叶子节点的下标 。
保存队列的最后一个元素 x = 10; n = 5:为队列最后一个元素的下标,half = n/2 = 2:为去除下标对应的元素后第一个叶子节点的下标 。
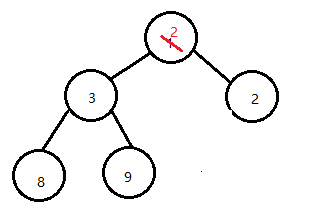 找出队顶元素子节点的最小值:2。并保存其下标:child = (k * 2)+1 / (k * 2)+2 ,这个表达式主要是找到k的子节点的最小值。判断最小值2与10的大小:2 < 10,所以2上浮。若k的子节点都比 10 大,说明k就是10待插入的下标。不用再作比较,跳出循环即可。
找出队顶元素子节点的最小值:2。并保存其下标:child = (k * 2)+1 / (k * 2)+2 ,这个表达式主要是找到k的子节点的最小值。判断最小值2与10的大小:2 < 10,所以2上浮。若k的子节点都比 10 大,说明k就是10待插入的下标。不用再作比较,跳出循环即可。
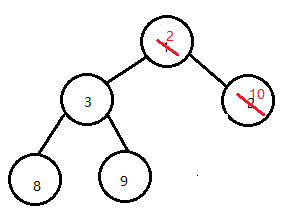 上述工作完成后另 k = child,比较 k 与 child的大小:若k大则说明k节点下还有子节点可以用来与 10 做比较,不是则说明 k 就是 10待插入的下标。此处 k = 2 , child = 2:说明找到了1带插入的位置,即k。
上述工作完成后另 k = child,比较 k 与 child的大小:若k大则说明k节点下还有子节点可以用来与 10 做比较,不是则说明 k 就是 10待插入的下标。此处 k = 2 , child = 2:说明找到了1带插入的位置,即k。
private static <T> void siftDownComparable(int k, T x, Object[] es, int n) { // assert n > 0; Comparable<? super T> key = (Comparable<? super T>)x; int half = n >>> 1; // loop while a non-leaf //half是第一个无子节点的节点的下标 while (k < half) { int child = (k << 1) + 1; // assume left child is least Object c = es[child]; int right = child + 1; //找出节点k的子节点中较小的那一个,并将其下标赋给child if (right < n && ((Comparable<? super T>) c).compareTo((T) es[right]) > 0) c = es[child = right]; //若key比较小的那一个还小,则k就是key待插入的下标,并跳出循环 if (key.compareTo((T) c) <= 0) break; //否则将c上浮,并更新待比较节点的位置,直至跳出循环 es[k] = c; k = child; } es[k] = key; }
以上就是我对优先队列源码的分析,不正之处欢迎大家指正。感谢!