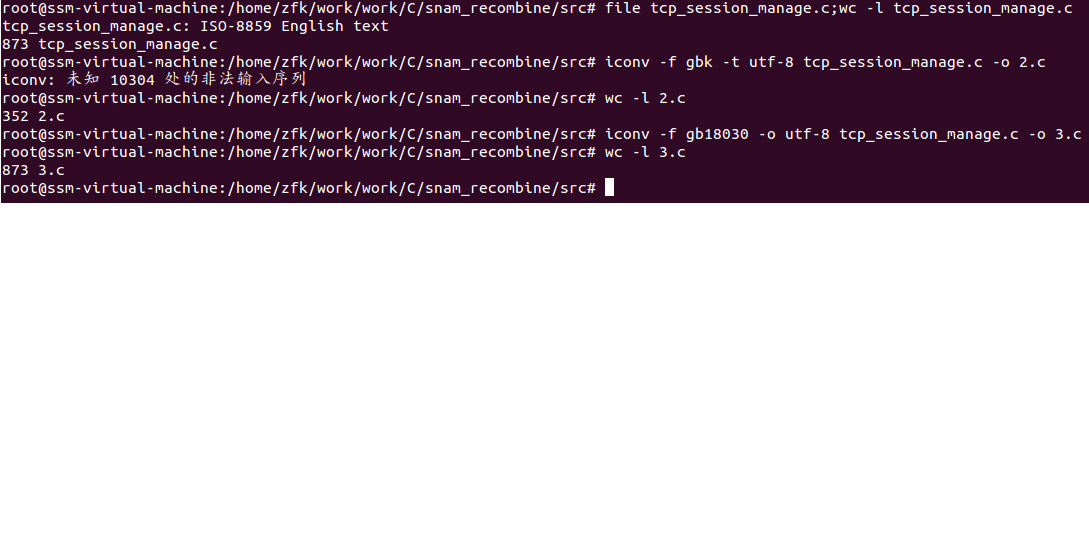
今天,再由ISO-8859编码格式转化为UTF-8格式过程中,出现报错:iconv: 未知 10304 处的非法输入序列。
问题分析:ISO-8859是英文格式的编码方式,不支持中文,为了解决中文支持的问题,出现了GB2312,但GB2312只支持中文简体,为了解决繁体和其它字符支持问题,出现了GBK编码方式,后来又为了支持更多的字符(猜测可能是日文韩文等语言支持)出现了GB18030编码方式。可得出结论ISO8859->GB2312->GBK->GB18030编码方式是依次扩展起来的,而且符合向下兼容的规律。因此,当执行命令iconv -f gbk -t utf-8报上面的错误的时候,可以尝试iconv -f gb18030 -t utf-8来解决。需要注意的是,网上介绍的用iconv -c 忽略未知字符的方式是错误的。
下图为实际验证结果:
参考资料:
http://jingyan.baidu.com/article/020278118741e91bcd9ce566.html
http://www.cnblogs.com/wangkangluo1/archive/2012/05/08/2490670.html