概述:
在web功能设计中,很多时候我们会要将需要访问的文件定义成变量,从而让前端的功能便的更加灵活。 当用户发起一个前端的请求时,便会将请求的这个文件的值(比如文件名称)传递到后台,后台再执行其对应的文件。
在这个过程中,如果后台没有对前端传进来的值进行严格的安全考虑,则攻击者可能会通过“../”这样的手段让后台打开或者执行一些其他的文件。 从而导致后台服务器上其他目录的文件结果被遍历出来,形成目录遍历漏洞。
看到这里,你可能会觉得目录遍历漏洞和不安全的文件下载,甚至文件包含漏洞有差不多的意思,是的,目录遍历漏洞形成的最主要的原因跟这两者一样,都是在功能设计中将要操作的文件使用变量的
方式传递给了后台,而又没有进行严格的安全考虑而造成的,只是出现的位置所展现的现象不一样,因此,这里还是单独拿出来定义一下。
需要区分一下的是,如果你通过不带参数的url(比如:http://xxxx/doc)列出了doc文件夹里面所有的文件,这种情况,我们成为敏感信息泄露。
而并不归为目录遍历漏洞。(关于敏感信息泄露你你可以在"i can see you ABC"中了解更多)
你可以通过“../../”对应的测试栏目,来进一步的了解该漏洞。
靶场:
1.进入靶场,
2.点击不同的链接,会有不同的回显,
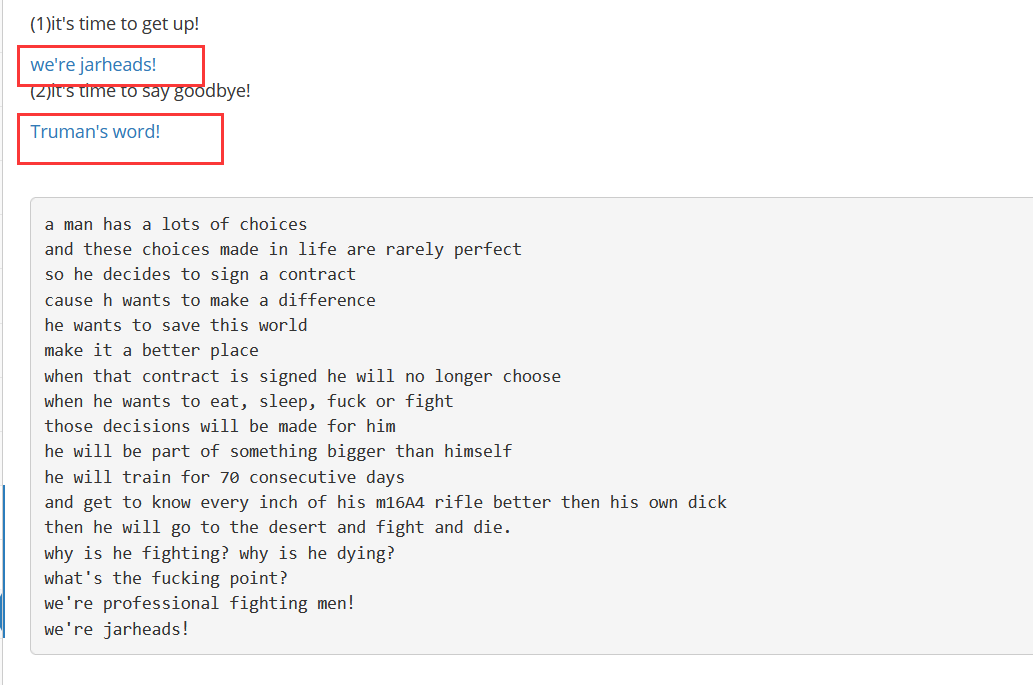
3.通过输入payload跳转到后台服务器的根目录下,获取我们想要的文件信息(注:输入的payload得是后台服务器对应系统的目录路径)
../../../../../../../../../../Windows/System32/drivers/etc/hosts
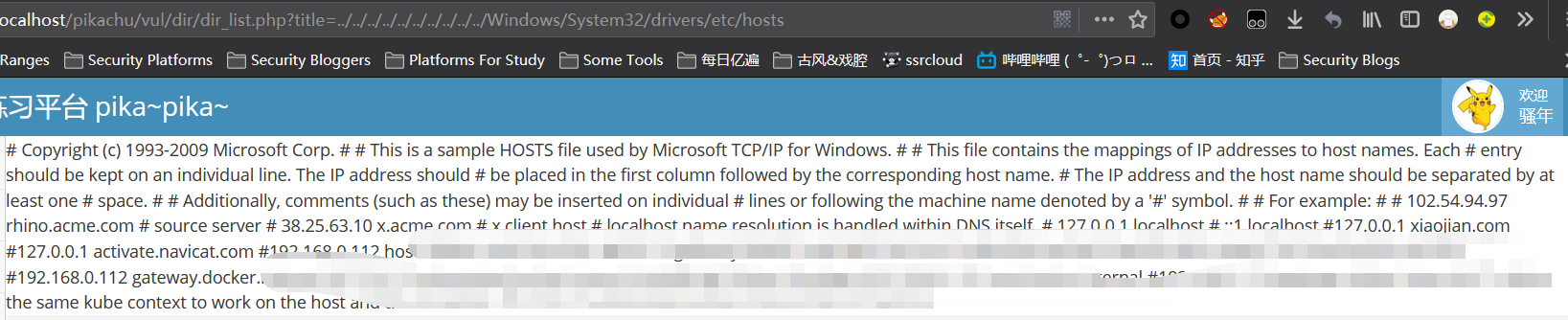
4.查看源代码,可以看出它收到前端的get请求后,并没有做任何的安全措施考虑,直接就读取执行了,这样就很容易让用户直接从前端绕过,从而获取后台服务器的信息
