一、使用Docker-compose实现Tomcat+Nginx负载均衡
1.反向代理:代理服务器
- nginx正向代理原理
正向代理,"它代理的是客户端",是一个位于客户端和原始服务器(origin server)之间的服务器,为了从原始服务器取得内容,客户端向代理发送一个请求并指定目标(原始服务器),然后代理向原始服务器转交请求并将获得的内容返回给客户端。客户端必须要进行一些特别的设置才能使用正向代理。 - nginx反向代理原理
反向代理(Reverse Proxy)方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个服务器(原始服务器对于客户端是透明的)。而正向代理(Forward Proxy),客户端请求时要指定原始服务器,代理再向原始服务器转交请求并将获得的内容返回给客户端。
2.nginx代理tomcat集群,代理2个以上tomcat
1、创建如下结构
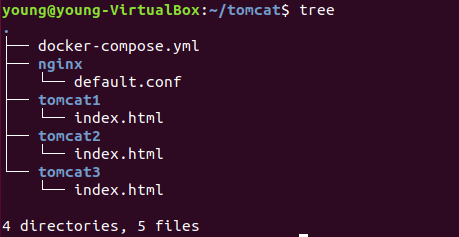
在目录下创建如下文件
- docker-compose.yml
version: "3"
services:
nginx:
image: nginx
container_name: lyhnginx
ports:
- "80:80"
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: lyhtomcat1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
tomcat02:
image: tomcat
container_name: lyhtomcat2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat02:
image: tomcat
container_name: lyhtomcat2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
tomcat03:
image: tomcat
container_name: lyhtomcat3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
default.conf
upstream tomcats {
server mytomcat1:8080; # 主机名:端口号
server mytomcat2:8080; # tomcat默认端口号8080
server mytomcat3:8080; # 默认使用轮询策略
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
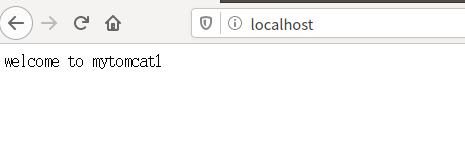
Index.html
welcome to mytomcat1
-运行docker-compose

- 查看容器

- 查看web端
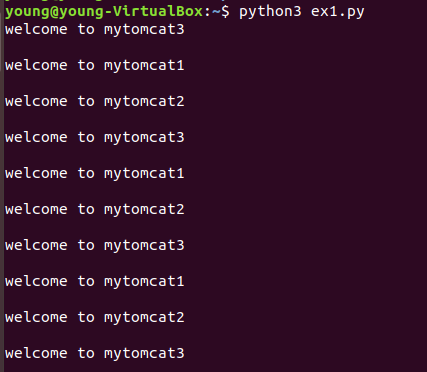
2.了解nginx的负载均衡策略,并至少实现nginx的2种负载均衡策略
- 负载均衡策略1:轮询策略
import requests
url="http://127.0.0.1"
for i in range(0,10):
reponse=requests.get(url)
print(reponse.text)
3.负载均衡策略2:权重策略
- 修改配置文件
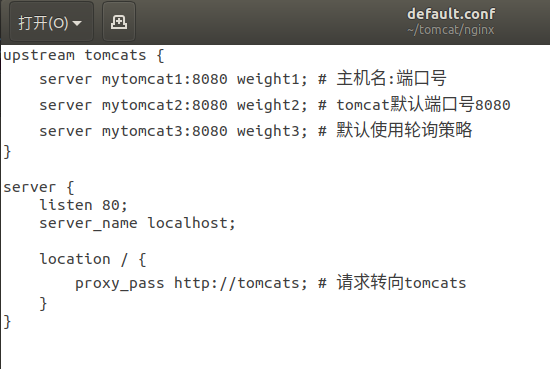
- weight参数用于指定轮询几率,weight的默认值为1,;weight的数值与访问比率成正比
import requests
url='http://localhost'
count={}
for i in range(0,1000):
response=requests.get(url)
if response.text in count:
count[response.text]+=1;
else:
count[response.text]=1
for a in count:
print(a, count[a])

二.使用Docker-compose部署javaweb运行环境
这里参考了参考资料的项目了
- 修改IP地址

- 打开终端运行
docker-compose up -d --build
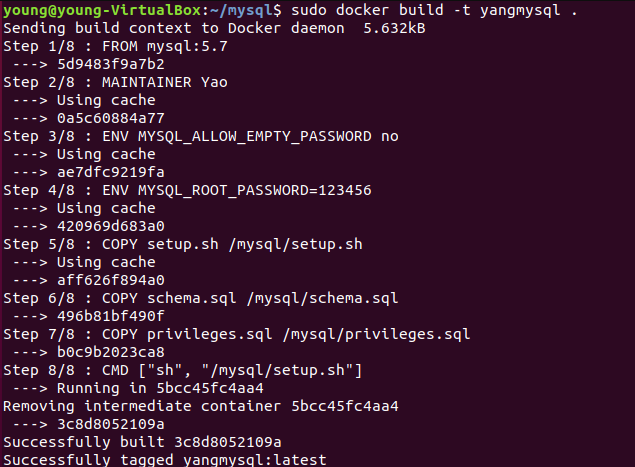
- 在web上查看(由于使用参考资料的用例,所以用户sa ,密码 123)

tomcat+nginx-mysql
- docker-compose.yml
version: "3"services:
nginx:
image: nginx
container_name: lyhnginx
ports:
- "80:80"
volumes:
- ./nginx/default.conf:/etc/nginx/conf.d/default.conf # 挂载配置文件
depends_on:
- tomcat01
- tomcat02
- tomcat03
tomcat01:
image: tomcat
container_name: lyhtomcat1
volumes:
- ./tomcat1:/usr/local/tomcat/webapps/ROOT # 挂载web目录
links:
- "mysql"
tomcat02:
image: tomcat
container_name: lyhtomcat2
volumes:
- ./tomcat2:/usr/local/tomcat/webapps/ROOT
links:
- "mysql"
tomcat03:
image: tomcat
container_name: lyhtomcat3
volumes:
- ./tomcat3:/usr/local/tomcat/webapps/ROOT
links:
- "mysql"
mysql:
build: ./mysql
ports:
- "3306:3306"
volumes:
- ./mysql/data/:/var/lib/mysql/
environment:
MYSQL_ROOT_PASSWORD : 123456
- default.conf
upstream tomcats {
server lyhtomcat1:8080 weight=1; # 主机名:端口号
server lyhtomcat2:8080 weight=2; # tomcat默认端口号8080
server lyhtomcat3:8080 weight=3; # 默认使用权重策略
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://tomcats; # 请求转向tomcats
}
}
- Dockerfile
#基础镜像FROM mysql:5.7
#维护者信息MAINTAINER yangmysql
- 构建镜像
sudo su
docker-compose up -d --build

- 进入mysql容器
docker exec -it tomcat_mysql_1 /bin/bash
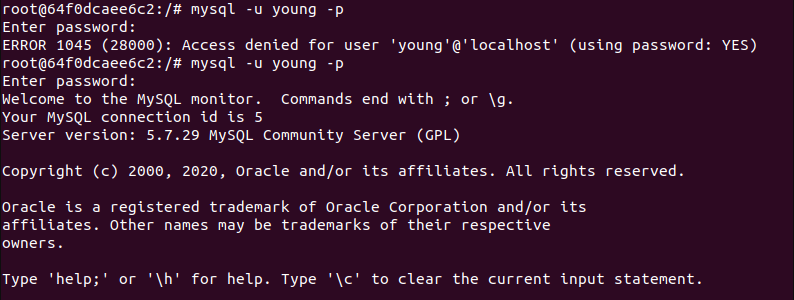
- 查看已有数据库
show databases;

- 创建新的数据库
create database `lyh` default character set utf8 collate utf8_general_ci;
- 使用数据库,建表
use yangmysql;CREATE TABLE user (
`id` varchar(20) NOT NULL,
`name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
);
- 插入数据
INSERT INTO user (`id`, `name`, `sex`)VALUES
('031702331','young');
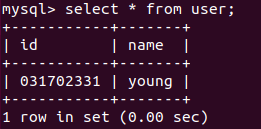
- 查找数据
select * from user;
- 使用爬虫查看负载均衡
import requests
url="http://127.0.0.1"count={}for i in range(0,2000):
response=requests.get(url)
if response.text in count:
count[response.text]+=1;
else:
count[response.text]=1for a in count:
print(a, count[a])

三.使用Docker搭建大数据集群环境
1.pull ubuntu镜像
docker pull ubuntu
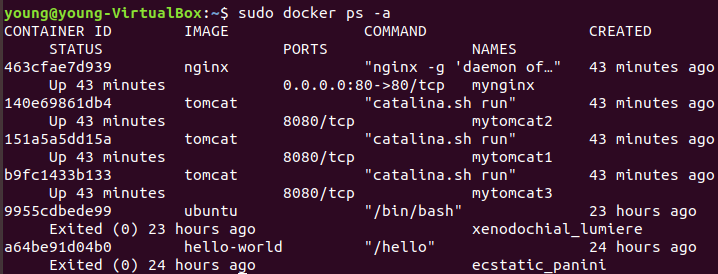
- 创建build文件 运行容器
mkdir build
sudo docker run -it -v /home/young/build:/root/build --name ubuntu ubuntu
- 进入容器换源
cat<<EOF>/etc/apt/sources.list #覆盖掉原先内容,注意左边只有一个>,<<EOF>是覆盖;<<EOF>>则变成追加;截图等我下次改
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
EOF

- 更新系统源和安装一些必要的软件
apt-get update
apt-get install vim
apt-get install ssh
/etc/init.d/ssh start
vim ~/.bashrc #在该文件中最后一行添加如下内容,实现进入Ubuntu系统时,都能自动启动sshd服务
/etc/init.d/ssh start
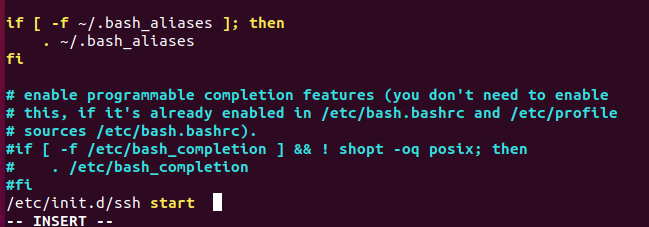
- 配置ssh
cd ~/.ssh
ssh-keygen -t rsa # 一直按回车即可
cat id_rsa.pub >> authorized_keys

- 安装JDK
apt install openjdk-8-jdk
vim ~/.bashrc # 在文件末尾添加以下两行,配置Java环境变量:export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/export PATH=$PATH:$JAVA_HOME/bin
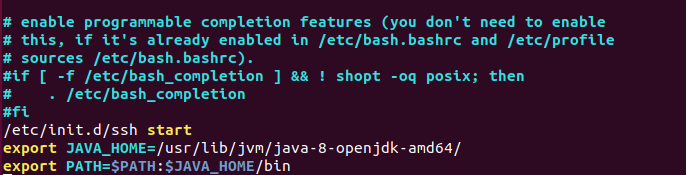
source ~/.bashrc
java -version #查看是否安装成功

- docker commit从容器去创建一个镜像
sudo docker commit b0432b2c0b9a ubuntu:jdk8
sudo docker run -it -v /home/young/build:/root/build --name ubuntu-jdk8 ubuntu:jdk8

2.安装Hadoop
cd /root/build
tar -zxvf hadoop-3.1.3.tar.gz -C /usr/local
cd /usr/local/hadoop-3.1.3
./bin/hadoop version
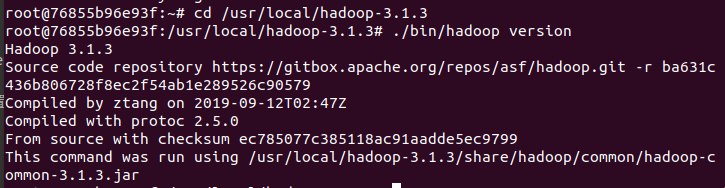
3.配置Hadoop集群
hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/
- core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-3.1.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
- hdfs-site.xml
vim hdfs-site.xml<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-3.1.3/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-3.1.3/datanode_dir</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property></configuration>
- mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<!--使用yarn运行MapReduce程序-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<!--jobhistory地址host:port-->
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<!--jobhistory的web地址host:port-->
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<!--指定MR应用程序的类路径-->
<name>mapreduce.application.classpath</name>
<value>/usr/local/hadoop-3.1.3/share/hadoop/mapreduce/lib/*,/usr/local/hadoop3.1.3/share/hadoop/mapreduce/*</value>
</property>
</configuration>
- yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.5</value>
</property>
</configuration>
- 修改脚本
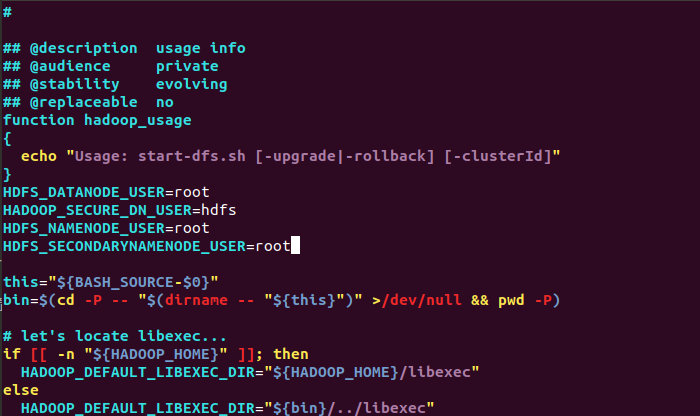
对于start-dfs.sh文件,添加下列参数:
cd /usr/local/hadoop-3.1.3/sbin
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
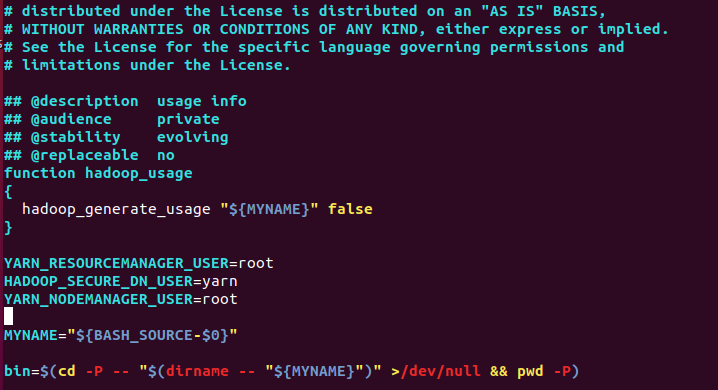
- 对于stop-yarn.sh文件,添加下列参数:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
3.运行Hadoop集群
- 保存镜像
sudo docker commit 76855b96e93f ubuntu/hadoopinstalled

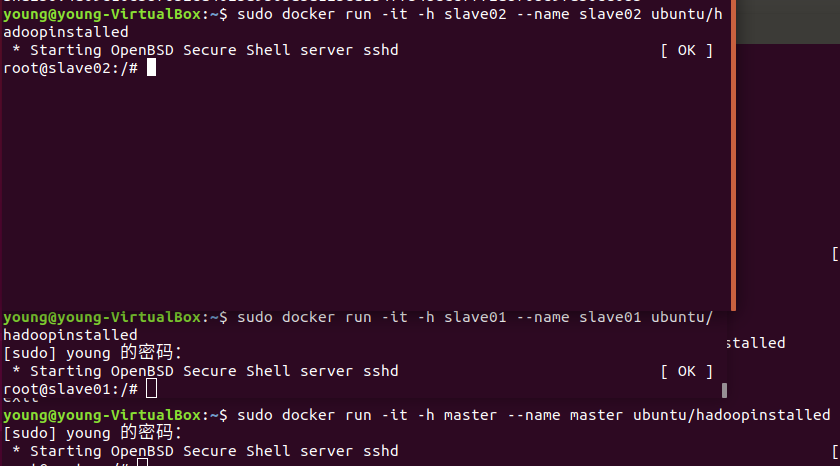
- 从三个终端分别开启三个容器运行ubuntu/hadoopinstalled镜像,分别表示Hadoop集群中的master,slave01和slave02;
sudo docker run -it -h master --name master ubuntu/hadoopinstalled # 第一个终端
sudo docker run -it -h slave01 --name slave01 ubuntu/hadoopinstalled # 第二个终端
sudo docker run -it -h slave02 --name slave02 ubuntu/hadoopinstalled # 第三个终端
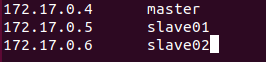
- 三个终端分别打开/etc/hosts,根据各自ip修改为如下形式
cat /etc/hosts
172.17.0.3 master
172.17.0.4 slave
01172.17.0.5 slave02
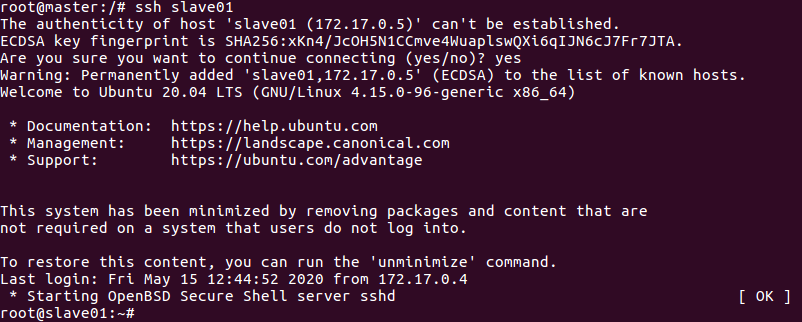
- 在master结点测试ssh;连接到slave结点
ssh slave01
ssh slave02
exit 退出

- 修改master上workers文件;将localhost修改为如下所示
vim /usr/local/hadoop-3.1.3/etc/hadoop/workers
slave01
slave02
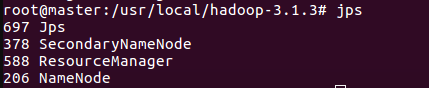
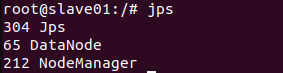
- 测试Hadoop集群
cd /usr/local/hadoop-3.1.3
bin/hdfs namenode -format #首次启动Hadoop需要格式化
sbin/start-all.sh #启动所有服务

- 使用jps查看三个终端

- 建立HDFS文件夹
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/root #注意input文件夹是在root目录下
bin/hdfs dfs -mkdir input
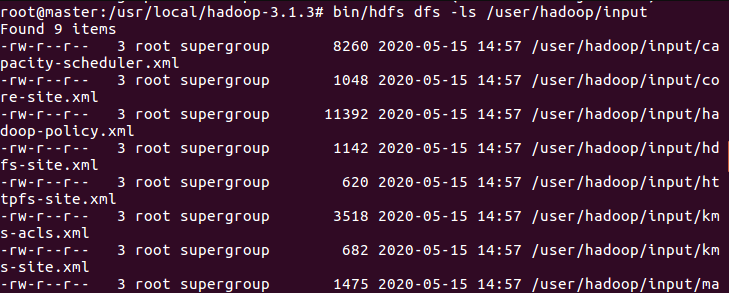
- 运行一个功能为计算字符串个数的jar包
bin/hadoop jar /usr/local/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount input output
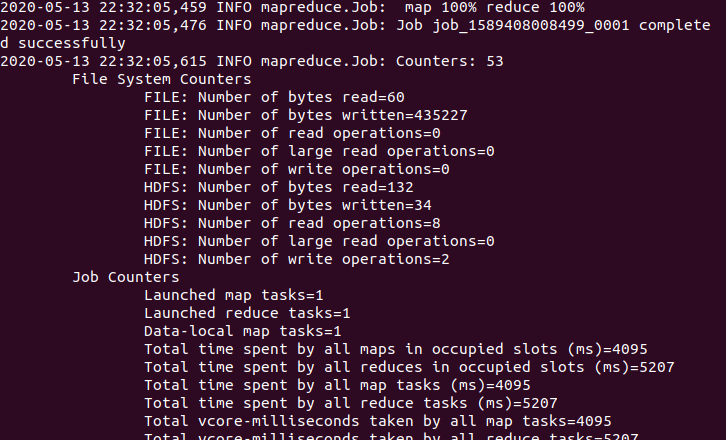
- cat查看output文件夹结果显示
./bin/hdfs dfs -cat output/*

四.实验总结
1.遇到的问题
遇到的问题主要是技术问题,第二个实验内容我就直接运用参考用例的例子了
然后就是在SSH 安装及免密登录设置步骤中,出现了有其他进程正在占用的情况,后来通过百度,解决了此问题

强制解锁命令:
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock
强制关闭其他进程