启动spark-shell时,报错如下:
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.hadoop.security.HadoopKerberosName.setRuleMechanism(Ljava/lang/String;)V at org.apache.hadoop.security.HadoopKerberosName.setConfiguration(HadoopKerberosName.java:84) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:318) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:303) at org.apache.hadoop.security.UserGroupInformation.doSubjectLogin(UserGroupInformation.java:1827) at org.apache.hadoop.security.UserGroupInformation.createLoginUser(UserGroupInformation.java:709) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:659) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:570) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2422) at org.apache.spark.util.Utils$$anonfun$getCurrentUserName$1.apply(Utils.scala:2422) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.util.Utils$.getCurrentUserName(Utils.scala:2422) at org.apache.spark.SecurityManager.<init>(SecurityManager.scala:79) at org.apache.spark.deploy.SparkSubmit.secMgr$lzycompute$1(SparkSubmit.scala:348) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$secMgr$1(SparkSubmit.scala:348) at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:356) at org.apache.spark.deploy.SparkSubmit$$anonfun$prepareSubmitEnvironment$7.apply(SparkSubmit.scala:356) at scala.Option.map(Option.scala:146) at org.apache.spark.deploy.SparkSubmit.prepareSubmitEnvironment(SparkSubmit.scala:355) at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:784) at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161) at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184) at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86) at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:930) at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:939) at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
解决方法:
这是由于错误的配置导致了hadoop的包和spark的包冲突。
原来是不知道啥时候修改了spark-defaults.conf中的配置。
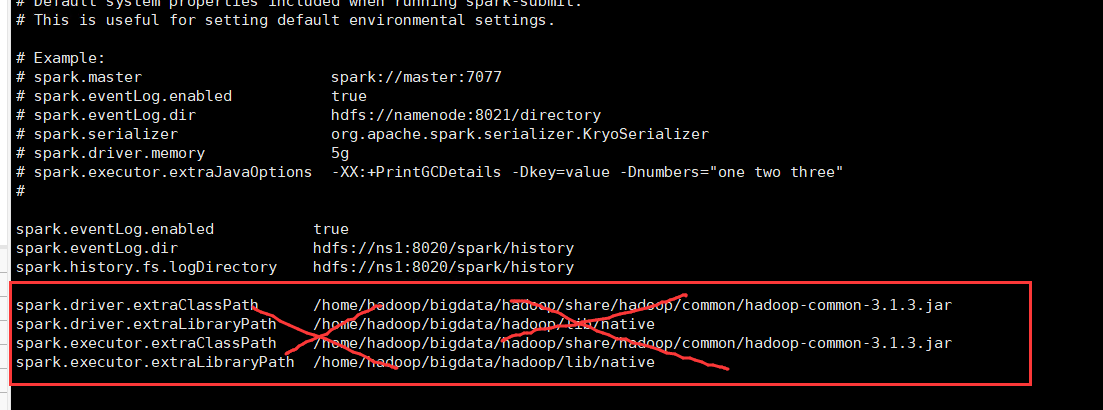
所以解决方法也是很简单,删除这个配置就可以。
