关于集合
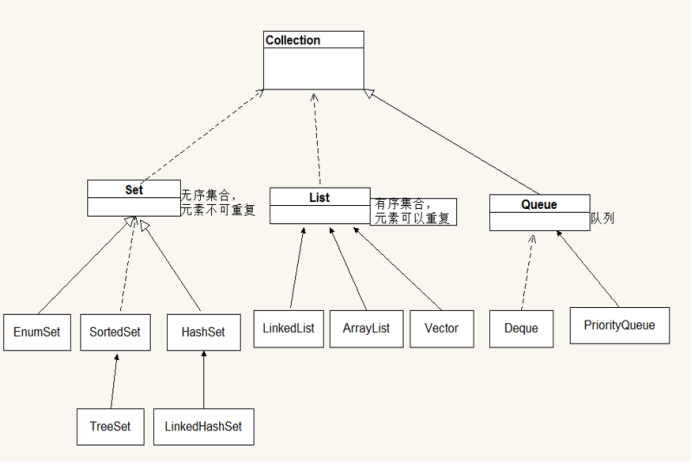
Collection
存出一组相同数据类型的集合
List===存储的是唯一的,无序的数据
ArrayList ======数组
ArrayList实现了随机访问的接口
便于查询,
总结:
ArrayList是基于数据实现的list,而LinkedList是基于链表实现的list。所以,ArrayList拥有着数组的特性,LinkedList拥有着链表的特性。
优缺点
ArrayList
优点:适合随机读取的时候,读取速度快,可以一步get(index)。
缺点:添加值很慢——一方面,添加数据在array中间的时候,需要移动后面的数;另一方面,当长度大于初始长度的时候,每添加一个数,都会需要扩容。
LinkedList =======链表
LinkedList实现了Quene的接口。
适合插入,删除
LinkedList:双向链表
优点:添加值很快——添加在list中间也只需要更改指针;长度不固定。
实现栈和队列方面,LinkedList要优于ArrayList。
Set =====存储无序的数据,唯一的
hashSet ====底层就是使用了hashMap
Set set=new HashSet();
set.add("abc");
set.add(new String("abc"));
set.add(new String("abc"));
System.out.println(set.size());
//底层就是map集合
//当传入相同的字符串的时候,返回的Hash值可能相等
//传入不同的字符串的时候,返回的Hash也可能相同,这个是时候就会往后排1去占用这个空间但是值还是和一开始的字符串的值一样,去找的话还找第一个
//以空间换时间
String a="abc";
System.out.println(a.hashCode());

就是研究Map的键值对中Key是为什么唯一的,就能确定Set为什么是唯一的了。
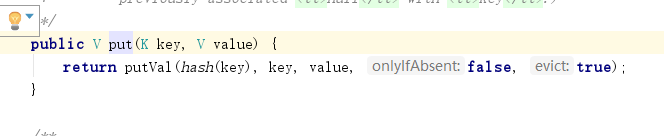
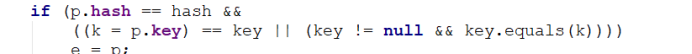
001.比较hash值 (简单int,如果hashcode不一致,不需要再比较了)
002.比较内存地址
003.比较具体的内容
解析:
1. Hash值返回的是int类型的,当Hash不同的时候就不会再往下比较了,直接跳出if,走else,也就是不存在,添加新key值
(1) 不同的字符串,有可能hashcode值一致
(2) 相同的字符串,hashcode值绝对一致
(3) 以空间换时间 (猪圈)
2. 然而呢反过来相同的hash不一定是相同的字符串,所以我们就要比较其内存地址或者真实值了,他这里是用的短路或,,来先用==比较内存地址,如果内存地址相同,ok不用往下比了,内存地址相同了,hash值也相同了,jvm就会认为,嗯,你俩就是一个玩意,,,
3. (这条是我个人理解,错了勿喷)但是呢,也有一种情况就是双方比较的值有一方存在于常量池中,以防在堆上,所以呢双方就没有了可比性,,,,所以不得以而为之equals上场,来吧,,比较真实值,真实值不一样那么一定就不是一个玩意了,那么新开辟key值,确保key值唯一
最后呢,,,总结一下
可以看出,这段底层代码,明明可以直接来比较真实值和hash值就会得到其结果,但是他却历经层层苦难,不到万不得已不会调用equals。。。为什么呢???当然是因为Java这门编程语言的一些思想啦,,,都知道,Java这门主打思想是什么面向对象鬼的。。但是一些一线程序员应该知道这个 --- 以空间换时间 没错,主要是性能、效率,多写些代码无所谓,要确保性能,与运行速度
学过c语言的都知道,其实呢根本不存在String 这个数据类型
那Java中为什么有呢,相信看过底层代码的都知道String 是由 一个char类型数组组成的,那么equals呢,其实是遍历两个数组来进行比较,兄弟,你说说,性能差不差,,所以上面的做法就不言而出了
TreeSet ==== 有序的数据
Treeset原理:
TreeSet存储对象的时候, 可以排序, 但是需要指定排序的算法
Integer能排序(有默认顺序), String能排序(有默认顺序), 自定义的类存储的时候出现异常(没有顺序)
如果想把自定义类的对象存入TreeSet进行排序, 那么必须实现Comparable接口
在类上implement Comparable
重写compareTo()方法
在方法内定义比较算法, 根据大小关系, 返回正数负数或零
在使用TreeSet存储对象的时候, add()方法内部就会自动调用compareTo()方法进行比较, 根据比较结果使用二叉树形式进行存储
TreeSet是依靠TreeMap来实现的。
TreeSet是一个有序集合,TreeSet中的元素将按照升序排列,缺省是按照自然排序进行排列,意味着TreeSet中的元素要实现Comparable接口。或者有一个自定义的比较器。
我们可以在构造TreeSet对象时,传递实现Comparator接口的比较器对象。
Map
HashMap===Hash+链表(数据结构)
负载因子 0.75
如果超过了负载因子的0.75,则会创建原来butcket的原老的两倍
线程不安全
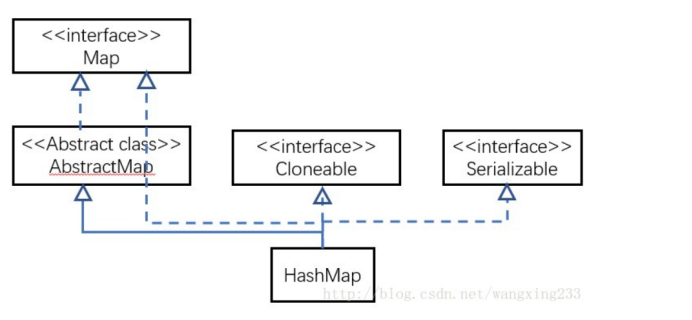
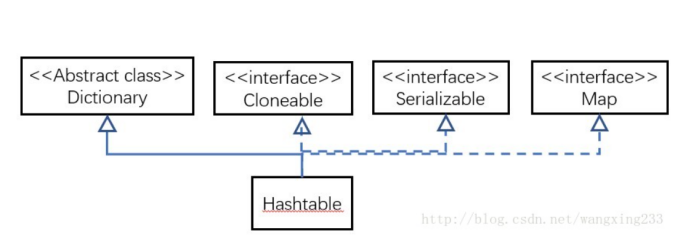
HashMap和Hashtable的区别:
HashMap和Hashtable都实现了Map接口,但决定用哪一个之前先要弄清楚它们之间的分别。主要的区别有:线程安全性,同步(synchronization),以及速度。
1. HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
2. HashMap是非synchronized,而Hashtable是synchronized,这意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
3. 另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
4. 由于Hashtable是线程安全的也是synchronized,所以在单线程环境下它比HashMap要慢。如果你不需要同步,只需要单一线程,那么使用HashMap性能要好过Hashtable。
5. HashMap不能保证随着时间的推移Map中的元素次序是不变的。
6. 继承的父类不同
HashMap和Hashtable不仅作者不同,而且连父类也是不一样的。HashMap是继承自AbstractMap类,而HashTable是继承自Dictionary类。不过它们都实现了同时实现了map、Cloneable(可复制)、Serializable(可序列化)这三个接口