一、准备过程
首先打开hao123漫画筛选区,网址是https://www.hao123.com/manhua/list/?finish=&audience=&area=&cate=&order=1
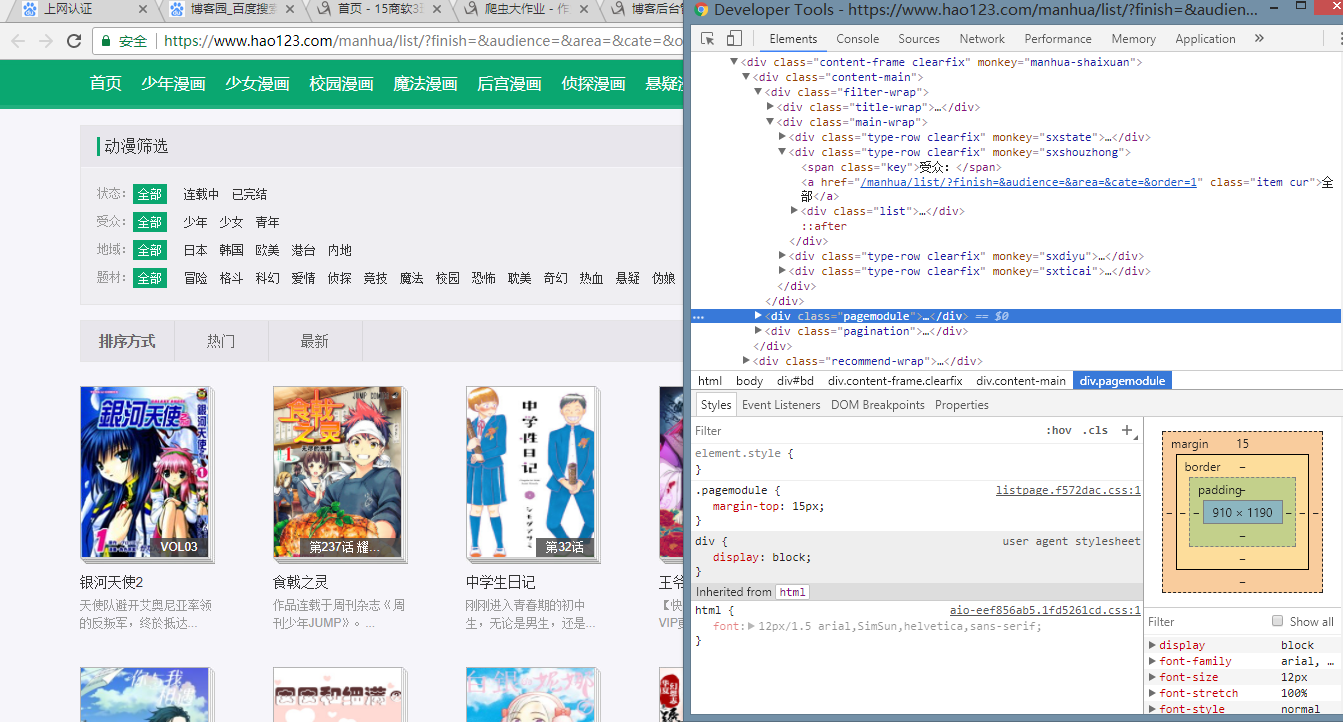
在这里可以通过审查模式看到第一页的详细信息,而目的则是通过爬取漫画筛选页面的每部漫画的人气与题材来分析最近漫画迷的观漫需求
环境如下:
python3.6.2 PyCharm
Windows8.1 第三方库(jieba,wordcloud,bs4,Requests,re,wordcloud)
二、代码
1.用requests库和BeautifulSoup库,爬取hao123漫画网当前页面的每部漫画的漫画名、地域、题材、人气、链接等,将获取漫画详情的代码定义成一个函数
def getCartoonDetail(cartoonUrl):
# 将获取hao123漫画详情的代码定义成一个函数 def getCartoonDetail(cartoonUrl): def getCartoonDetail(cartoonUrl): resd = requests.get(cartoonUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') cartoons = {} # 获取除了标题外的字符串 a = soupd.select('.title-wrap')[0].select('span')[0].text # 计算字符串的长度 num = len(a) # 标题 cartoons['title'] = soupd.select('.title-wrap')[0].text[:-num] ul = soupd.select('.info-list')[0] # 地域 cartoons['territory'] = ul.select('li')[1].text.lstrip('地域:').replace('xa0'," ") #漫画题材 cartoons['theme'] = ul.select('li')[-2].text.lstrip('题材:').replace('xa0'," ") #人气 cartoons['moods'] = ul.select('li')[-1].text.lstrip('人气:') writeCartoonDetail(cartoons['theme'] + ' ' + cartoons['moods'] + ' ') return cartoons
2.取出一个漫画列表页的全部漫画 包装成函数def getListPage(pageUrl):
def getListPage(pageUrl): res = requests.get(pageUrl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') cartoonlist = []for cartoon in soup.select('.item-1'): # cartoon.select('.title')获取列表里的漫画标题 if len(cartoon.select('.title')) > 0: a = cartoon.select('a')[0].attrs['href']#链接 cartoonlist.append(getCartoonDetail(a)) return cartoonlist
3.获取总的漫画篇数,算出漫画总页数包装成函数def getPageN():
def getPageN(): res = requests.get('https://www.hao123.com/manhua/list/?finish=&audience=&area=&cate=&order=1') res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') n = int(soup.select('.gray')[1].text.lstrip('共').rsplit('页')[0]) return n
4. 获取全部漫画列表页的全部漫画详情。(爬取页面前30页,原因是爬取的数据太多,搞到电脑蓝屏,列表好像出现过溢出)
cartoontotal = [] pageUrl = 'https://www.hao123.com/manhua/list/?finish=&audience=&area=&cate=&order=1' cartoontotal.extend(getListPage(pageUrl)) n = getPageN() for i in range(2, 30 + 1): pageUrl = 'https://www.hao123.com/manhua/list/?finish=&audience=&area=&cate=&order=1&pn={}'.format(i) cartoontotal.extend(getListPage(pageUrl))
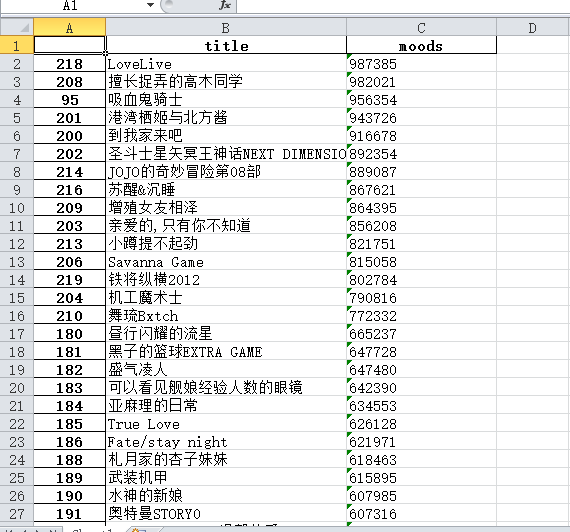
5.将爬取到所有信息通过pandas根据评分排序,然后只爬取'title'和'moods'两列的信息,并保存至excel表中
df = pandas.DataFrame(cartoontotal) # 将爬取到所有信息通过pandas根据人气排序,然后只爬取'title'和'moods'两列的信息,并保存至excel表中 dfs=df.sort_index(by='moods', ascending=False) dfsn=dfs[['title', 'moods']] dfsn.to_excel('cartoon.xlsx', encoding='utf-8')
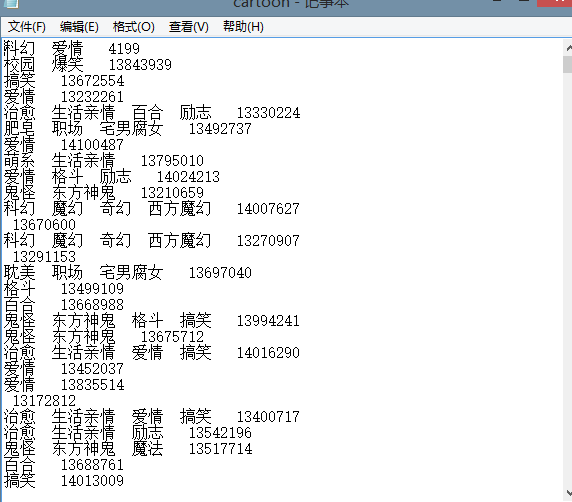
6.将爬取到的漫画题材通过构造方法writeNewsDetail(content)写入到文本cartoon.txt中
def writeCartoonDetail(content): f=open('cartoon.txt','a',encoding='utf-8') f.write(content) f.close()
三、生成词云
通过导入wordcloud的包,来生成词云
from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator # image= Image.open('./logo.jpg') # graph = np.array(image) # 获取上面保存的字典 title_dict = changeTitleToDict() graph = np.array(title_dict) font = r'C:WindowsFontssimhei.ttf' # backgroud_Image代表自定义显示图片,这里我使用默认的 backgroud_Image = plt.imread("G:/大三2/大数据/filedocuments/logo1.jpg") wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image) # wc = WordCloud(background_color='white',max_words=500,font_path=font) wc.generate_from_frequencies(title_dict) plt.imshow(wc) plt.axis("off") plt.show()
选择的图片:
原图:

由于生成的词云是按照背景色来生成的,故显示效果为

一个矩形,明显不是我想要的效果,所以重新抠图如下:

效果如下:
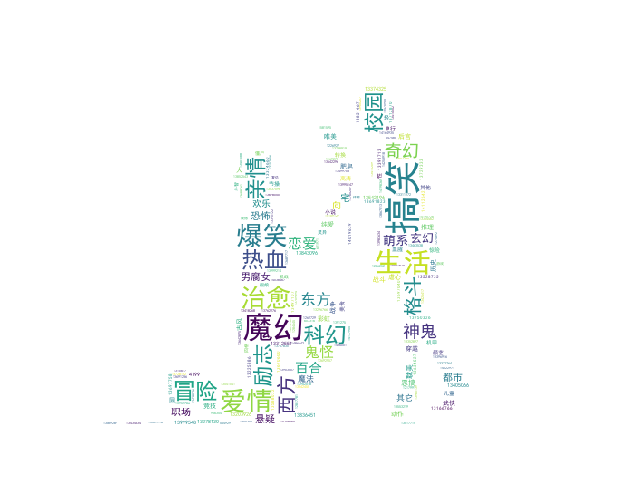
四、遇到的问题及解决方案
1.在导入wordcloud这个包的时候,会遇到很多问题
首先通过使用pip install wordcloud这个方法在全局进行包的下载,可是最后会报错误error: Microsoft Visual C++ 14.0 is required. Get it with “Microsoft Visual C++ Build Tools”: http://landinghub.visualstudio.com/visual-cpp-build-tools
这需要我们去下载VS2017中的工具包,但是网上说文件较大,所以放弃。
之后尝试去https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud下载whl文件,然后安装。
下载对应的python版本进行安装,如我的就下载wordcloud-1.4.1-cp36-cp36m-win32.whl,wordcloud-1.4.1-cp36-cp36m-win_amd64
两个文件都放到项目目录中,两种文件都尝试安装
通过cd到这个文件的目录中,通过pip install wordcloud-1.4.1-cp36-cp36m-win_amd64,进行导入
但是两个尝试后只有win32的能导入,64位的不支持,所以最后只能将下好的wordcloud放到项目lib中,在Pycharm中import wordcloud,最后成功
2.在爬取漫画信息的时候,爬取漫画标题的时候,会因为soupd.select('.title-wrap')[0].text获取除标题外的其他值,如已完结,如下图

解决方案如下:
# 获取除了标题外的字符串 a = soupd.select('.title-wrap')[0].select('span')[0].text # 计算字符串的长度 num = len(a) # 标题 cartoons['title'] = soupd.select('.title-wrap')[0].text[:-num]
五、数据分析与结论
通过对词云的查看,可以看出漫画迷对于类型类型为搞笑、爱情、生活、魔幻、治愈、冒险等题材的漫画喜欢,而对都市、竞技、悬疑等题材的漫画选择很少,这说明观看漫画选择的大多数是有关于有趣与刺激的,而对于推理类的漫画选择少,这样在出版漫画时可以通过受众程度来出版。
而在这次作业中,我了解并实现如何爬取一个网站的有用信息,如何对爬取的信息分析并得到结论,虽然我对于大数据技术深度的技术并不了解,而且基础的知识也需要我不断加深巩固。
六、所有代码
# 大数据大作业 # 爬取hao123漫画网中的漫画人气最多的题材 import requests import re from bs4 import BeautifulSoup import pandas import jieba # 将爬取到的漫画题材通过构造方法writeNewsDetail(content)写入到文本cartoon.txt中 def writeCartoonDetail(content): f=open('cartoon.txt','a',encoding='utf-8') f.write(content) f.close() # 将获取hao123漫画详情的代码定义成一个函数 def getCartoonDetail(cartoonUrl): def getCartoonDetail(cartoonUrl): resd = requests.get(cartoonUrl) resd.encoding = 'utf-8' soupd = BeautifulSoup(resd.text, 'html.parser') # print(cartoonUrl) cartoons = {} # 获取除了标题外的字符串 a = soupd.select('.title-wrap')[0].select('span')[0].text # print(a) # 计算字符串的长度 num = len(a) # print(num) # 标题 cartoons['title'] = soupd.select('.title-wrap')[0].text[:-num] # print(title) # b = soupd.select('.info-list')[0].select('li')[-1].text # print(b) ul = soupd.select('.info-list')[0] # print(ul) # 地域 cartoons['territory'] = ul.select('li')[1].text.lstrip('地域:').replace('xa0'," ") # print(territory) #漫画题材 cartoons['theme'] = ul.select('li')[-2].text.lstrip('题材:').replace('xa0'," ") # print(theme) #人气 cartoons['moods'] = ul.select('li')[-1].text.lstrip('人气:') # print(moods) # b = soupd.select('.chapter-page') # print(b) writeCartoonDetail(cartoons['theme'] + ' ' + cartoons['moods'] + ' ') return cartoons # 取出一个漫画列表页的全部漫画 包装成函数def getListPage(pageUrl): def getListPage(pageUrl): res = requests.get(pageUrl) res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') cartoonlist = [] # c = soup.select('.list-page') # c = soup.select('.item-1') # print(c) # a = c[0].select('a')[0].attrs['href']#链接 # print(a) # soup.select('.item-1')获取漫画列表 for cartoon in soup.select('.item-1'): # cartoon.select('.title')获取列表里的漫画标题 if len(cartoon.select('.title')) > 0: # print(cartoon.select('.title')) a = cartoon.select('a')[0].attrs['href']#链接 # print(a) cartoonlist.append(getCartoonDetail(a)) # print(cartoonlist) return cartoonlist # 获取总的漫画篇数,算出漫画总页数包装成函数def getPageN(): def getPageN(): res = requests.get('https://www.hao123.com/manhua/list/?finish=&audience=&area=&cate=&order=1') res.encoding = 'utf-8' soup = BeautifulSoup(res.text, 'html.parser') n = int(soup.select('.gray')[1].text.lstrip('共').rsplit('页')[0]) return n # 获取全部漫画列表页的全部漫画详情。 cartoontotal = [] pageUrl = 'https://www.hao123.com/manhua/list/?finish=&audience=&area=&cate=&order=1' cartoontotal.extend(getListPage(pageUrl)) # print(cartoontotal) n = getPageN() # print(n) for i in range(2, 6 + 1): pageUrl = 'https://www.hao123.com/manhua/list/?finish=&audience=&area=&cate=&order=1&pn={}'.format(i) cartoontotal.extend(getListPage(pageUrl)) # print(cartoontotal) # print(cartoontotal) cartoonsList = {} for c in cartoontotal: # print(c) cartoonsList['theme'] = c['theme'] cartoonsList['moods'] = c['moods'] print(cartoonsList) df = pandas.DataFrame(cartoontotal) # print(df) # 将爬取到所有信息通过pandas根据人气排序,然后只爬取'title'和'moods'两列的信息,并保存至excel表中 dfs=df.sort_index(by='moods', ascending=False) dfsn=dfs[['title', 'moods']] # print(dfsn) dfsn.to_excel('cartoon.xlsx', encoding='utf-8') # import jieba # f = open('cartoon.txt','r',encoding="UTF-8") # str1 = f.read() # f.close() # str2 = list(jieba.cut(str1)) # countdict = {} # for i in str2: # countdict[i] = str2.count(i) # dictList = list(countdict.items()) # dictList.sort(key=lambda x: x[1], reverse=True) # f = open("G:/大三2/大数据/filedocuments/jieba.txt", "a") # for i in range(30): # f.write(' ' + dictList[i][0] + " " + str(dictList[i][1])) # print(f) # f.close() # 读取保存的内容,并转化为字典,同时把结果返回生成词云; def changeTitleToDict(): f = open("cartoon.txt", "r", encoding='utf-8') str = f.read() stringList = list(jieba.cut(str)) delWord = {"+", "/", "(", ")", "【", "】", " ", ";", "!", "、"} stringSet = set(stringList) - delWord title_dict = {} for i in stringSet: title_dict[i] = stringList.count(i) return title_dict # 生成词云 from PIL import Image,ImageSequence import numpy as np import matplotlib.pyplot as plt from wordcloud import WordCloud,ImageColorGenerator # image= Image.open('./logo.jpg') # graph = np.array(image) # 获取上面保存的字典 title_dict = changeTitleToDict() graph = np.array(title_dict) font = r'C:WindowsFontssimhei.ttf' # backgroud_Image代表自定义显示图片,这里我使用默认的 backgroud_Image = plt.imread("G:/大三2/大数据/filedocuments/logo.jpg") wc = WordCloud(background_color='white',max_words=500,font_path=font, mask=backgroud_Image) # wc = WordCloud(background_color='white',max_words=500,font_path=font) wc.generate_from_frequencies(title_dict) plt.imshow(wc) plt.axis("off") plt.show()