周总结八
本周学习了pandas,对大量的数据进行了操作尝试
1.读取.csv格式的数据文件
#导包
import pandas
#读取数据文件,并将数据赋值成一个变量
food_info = pandas.read_csv("food_info.csv")
#将数据赋值成一个变量后,打印此变量的类型为Dataframe
print(type(food_info))
#打印文件中数据的类型。object类型即string类型
print(food_info.dtypes)
#若对pandas中的某函数不了解,可以通过help()来查看
print(help(pandas.read_csv))
运行结果:
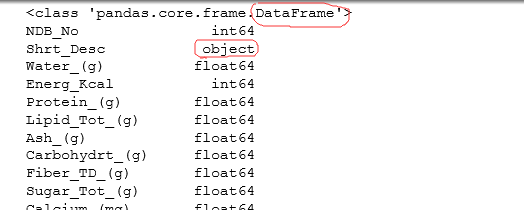
补充:DataFrame结构中的dtype类型
object————for string values
int————for integer values
float————for float values
datetime————for time values
bool————for Boolean values
2. DataFrame类型的变量拥有的操作
在第一步中,将要处理的数据文件读取出来并赋值给一个变量food_info,此变量的类型为DataFrame类型,下边将会对这个变量进行操作。
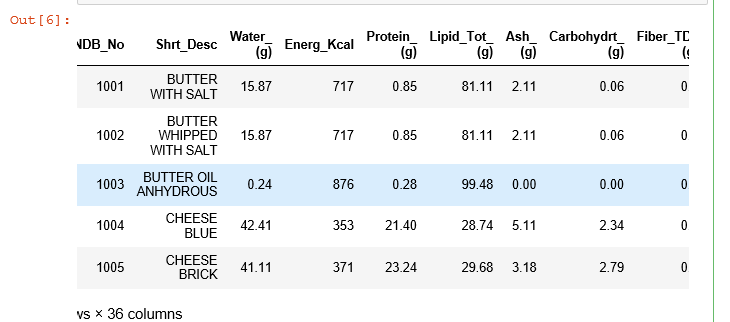
2.1 .head()函数:读取并显示数据的前几行
A. 无参数:缺省默认显示前5行数据
#缺省默认显示前5行数据
food_info.head()
运行结果:
B. 有参数: .head(a)函数如果添加参数a,则显示数据的前a行
#读取并显示数据的前3行
food_info.head(3)
运行结果:

2.2 .tail()函数:读取并显示数据的后几行
A. 无参数:.缺省默认显示后5行数据
#缺省默认显示后5行数据
food_info.tail()
运行结果:

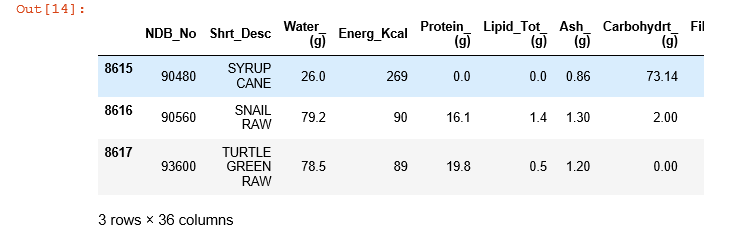
B. 有参数:.tail(a)函数如果添加参数a,则显示数据的末尾a行
#读取并显示数据的后3行
food_info.tail(3)
运行结果:
有print与没有print的区别
没有实质性的差别,只是显示的形式不同而已。
print(food_info.tail(3)) #有print和没有print显示形式有些不同
运行结果:

2.3 .columns函数:读取并显示列名
#读取并显示列名
food_info.columns
#print(food_info.columns)
运行结果:
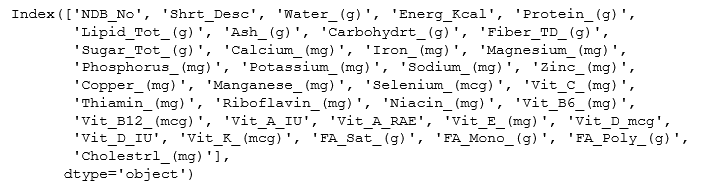
2.4 .shape函数:返回数据文件的行数和列数
#读取并显示文件的行数和列数
food_info.shape
运行结果:

2.5 .loc[ ]函数:读取文件中特定行位置的数据
在Pandas中取文件特定位置的数据不像python和numpy中那样直接通过index来调
A. .loc[a]函数,参数a:取第a+1行的数据(index是从0开始的)
#读取并显示特定行的数据
#返回第一行的文件数据
food_info.loc[0]
运行结果:

注意:当index的值超过了文件的样本个数,会报错(越界)
#返回第8889行的文件数据
food_info.loc[8888]
运行结果:

B. .loc[a:b]函数,参数a:b :取从第a行到第b行的数据
#返回数据文件的3——6行数据
food_info.loc[3:6]
运行结果:
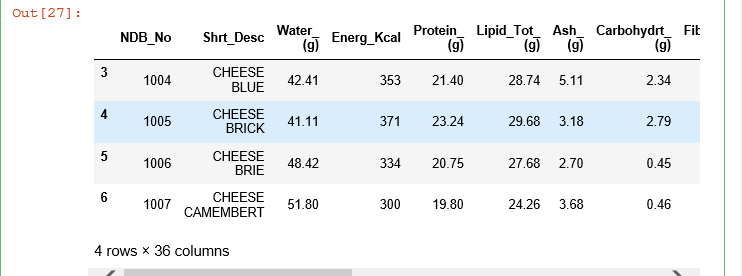
C. .loc[[a,b,c]]函数,参数a,b,c :取第a,b,c三行的数据
注意:这里的参数是*元组*形式 [a, b, c]
#返回数据文件的3,5,7行数据
food_info.loc[[3,5,7]]
运行结果:
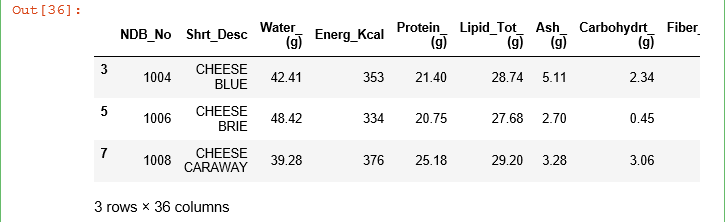
2.6 读取文件中特定列位置的数据
A. 取一列数据
#读取并显示列名为“NDB_No”所在的那一列
ndb_col = food_info["NDB_No"]
print(ndb_col)
#也可以将列名“NDB_No”赋值给变量,然后通过变量来返回数据
col_name = "NDB_No"
ndb_col = food_info[col_name]
print(ndb_col)
运行结果:

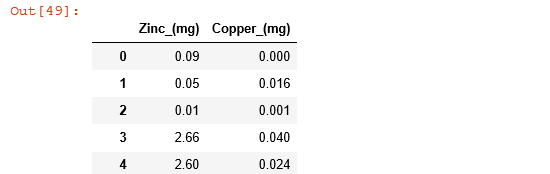
B. 取特定几列数据
想要取特定的几列,则只需要将想要取得列的列名弄到一起,组成一个list就可以了
#将要取得两列的列名放到一个list里,并赋给变量
columns = ["Zinc_(mg)","Copper_(mg)"]
#通过变量取得两列的数据
zinc_coop = food_info[columns]
print(zinc_coop)
#完全可以不依靠中间变量,意义相同
#food_info[["Zinc_(mg)","Copper_(mg)"]]
运行结果:
参考:
https://blog.csdn.net/weixin_39549734/article/details/81113018 如有侵权,请联系删除
代码量100行
平均学习 1小时