一:概述
- 我有一个需求是需要邮箱登录的,
- mysql> select f1, f2 from SUser where email='xxx';
- 我们知道,如果不在 email 上建立索引,那么将会走全表扫描。
- 于是,我们有两种建立方式
- mysql> alter table SUser add index index1(email); // 普通索引
- mysql> alter table SUser add index index2(email(6)); // 前缀索引
二:普通索引和前缀索引的区别?
- 我们看看,他们建立的索引树有什么不同
- 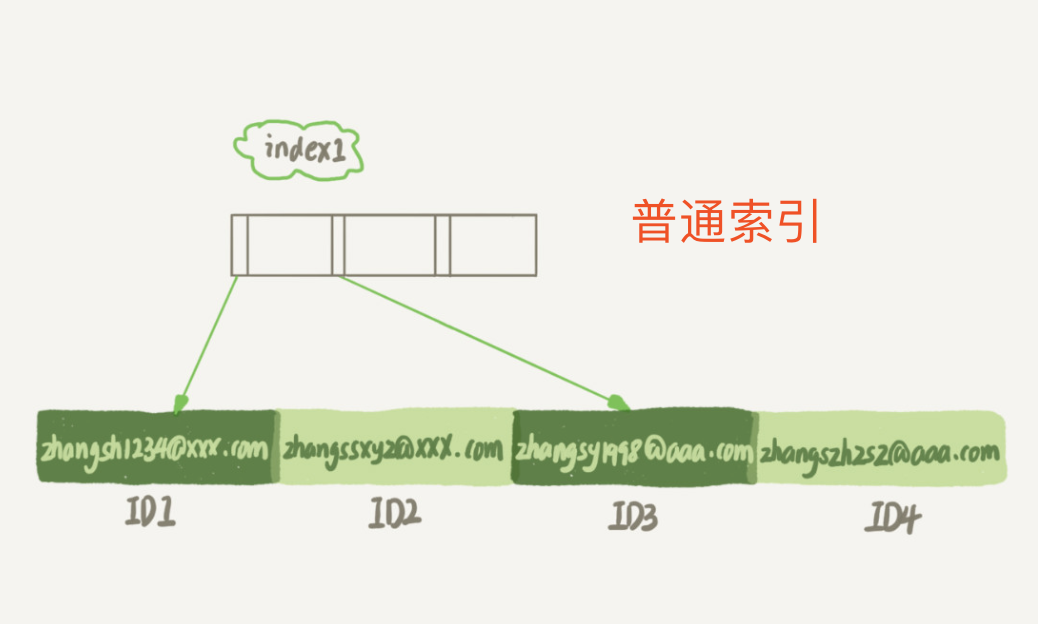

- 从图中你可以看到
- 由于 email(6) 这个索引结构中每个邮箱字段都只取前 6 个字节(即:zhangs),所以占用的空间会更小,这就是使用前缀索引的优势。
三:普通索引和前缀索引查询流程的不同?
- 举例
- select id,name,email from SUser where email='zhangssxyz@xxx.com';
- 普通索引
- 从索引树找到满足索引值是 'zhangssxyz@xxx.com' 的这条记录,取得 ID2 的值;
- 到主键上查到主键值是 ID2 的行,判断 email 的值是正确的,将这行记录加入结果集;
- 取索引树上刚刚查到的位置的下一条记录,发现已经不满足 email='zhangssxyz@xxx.com'的条件了,循环结束。
- 这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行。
- 前缀索引
- 索引树找到满足索引值是 'zhangs' 的记录,找到的第一个是 ID1;
- 到主键上查到主键值是 ID1 的行,判断出 email 的值不是'zhangssxyz@xxx.com',这行记录丢弃;
- 取到刚刚查到的位置的下一条记录,发现仍然是’zhangs‘,取出 ID2,再到 ID 索引上取整行然后判断,这次值对了,将这行记录加入结果集;
- 重复上一步,直到取到的值不是'zhangs'时,循环结束。
- 在这个过程中,要回主键索引取 4 次数据,也就是扫描了 4 行。
- 结论
- 通过这个对比,你很容易就可以发现,使用前缀索引后,可能会导致查询语句读数据的次数变多。
四:区分度
- 通过上面的测试,我们知道,是否会导致查询变多,主要是建立前缀索引的区分度的选择。
- SELECT COUNT(DISTINCT LEFT(column_name, $length)) / COUNT(*) FROM table_name; // 查询区分度
五: 前缀索引对覆盖索引的影响
- 使用前缀索引后,无法在使用覆盖索引,面对查询条件,可能需要回表操作。
六:面对字符串,我们也可以采取其他方式存储
- hash
- bit 位
- 倒序
- 等等