简单动态字符串(SDS),双端链表,字典,压缩列表,整数集合等数据结构。
构成字符串对象,列表对象,哈希对象,集合对象,有序集合对象五种类型。
针对不同的使用场景设置不同的数据结构实现,从而优化使用效率。
redis对象系统基于引用技术的内存回收机制和对象共享机制。
还有维护一个lru值,空转时长较大的键可能被优先删除
一个redis对象结构
typedef struct redisObject{ //类型 unsigned type:4; //编码 unsigned encoding:4; //指向底层实现数据结构的指针 void *ptr; //... }robj;
类型记录对象的类型,五个之一。
使用的数据结构和编码有关
REDIS_ENCODING_INT 使用整数值
REDIS_ENCODING_EMBSTR 使用embstr编码的简单动态字符串
REDIS_ENCODING_RAM 使用简单动态字符串
REDIS_ENCODING_ZIPLIST 使用压缩列表
REDIS_ENCODING_LINKEDLIST 使用双端链表
REDIS_ENCODING_HT 使用字典
REDIS_ENCODING_INTSET 使用整数集合
REDIS_ENCODING_SKIPLIST 使用跳跃表和字典
字符串对象,有三种实现


如果一个字符串对象保存的是整数值,且在long范围内,则用REDIS_ENCODING_INT,ptr指针类型变为long
如果是一个字符串值并且长度大于39字节,则用一个简单动态字符串保存,编码为REDIS_ENCODING_RAW
如果是字符串且小于等于39,则使用embstr编码的SDS。
embstr编码是专门用于保存短字符串的一种优化编码方式,将redisObject和sdshdr分配一块连续的空间。
好处:将内存分配次数从两次变成一次。释放也是一次。更好利用缓存的优势。
浮点数也是保存在字符串对象中,有需要时转换回浮点型。
redis没有为embstr编写相应的修改程序,所以当需要修改时会先转成raw,也不会变回来了
列表对象,有两种实现
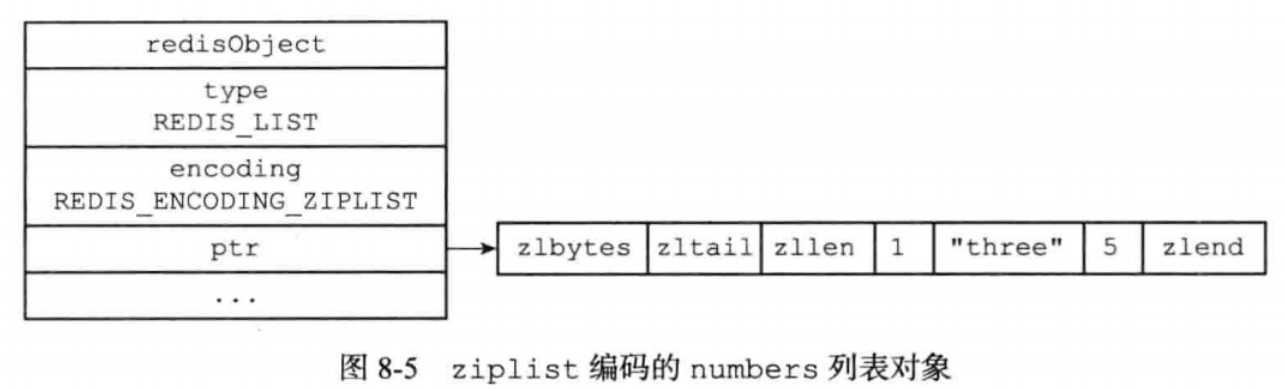
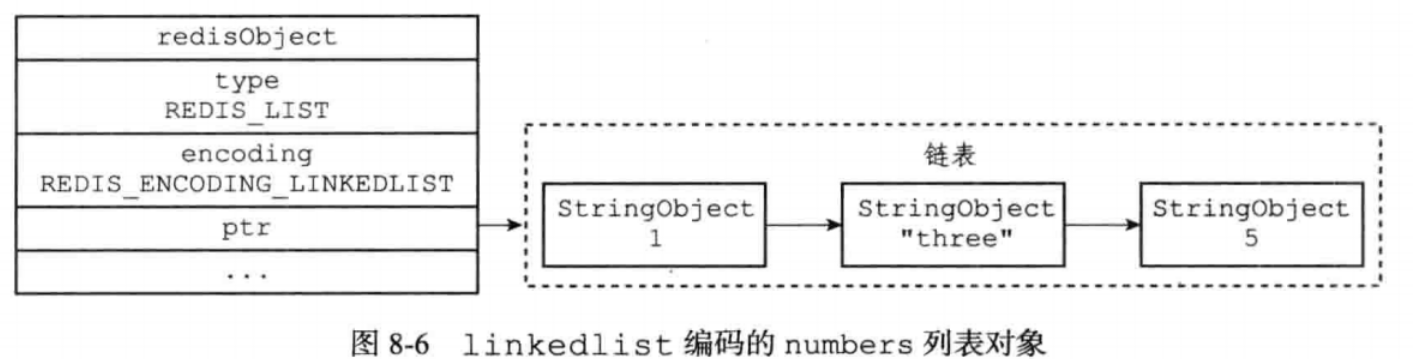
ziplist和双端链表
当列表对象保存的字符串元素的长度都小于64,元素总数小于512,就用ziplist,否则就是双端链表
这两个条件的上限可以改变,配置文件
哈希对象,有两种实现
ziplist或hashtable
ziplist会将键和值紧挨推入压缩列表末尾。
条件和上一个一样,可以改变
集合对象,有两种实现
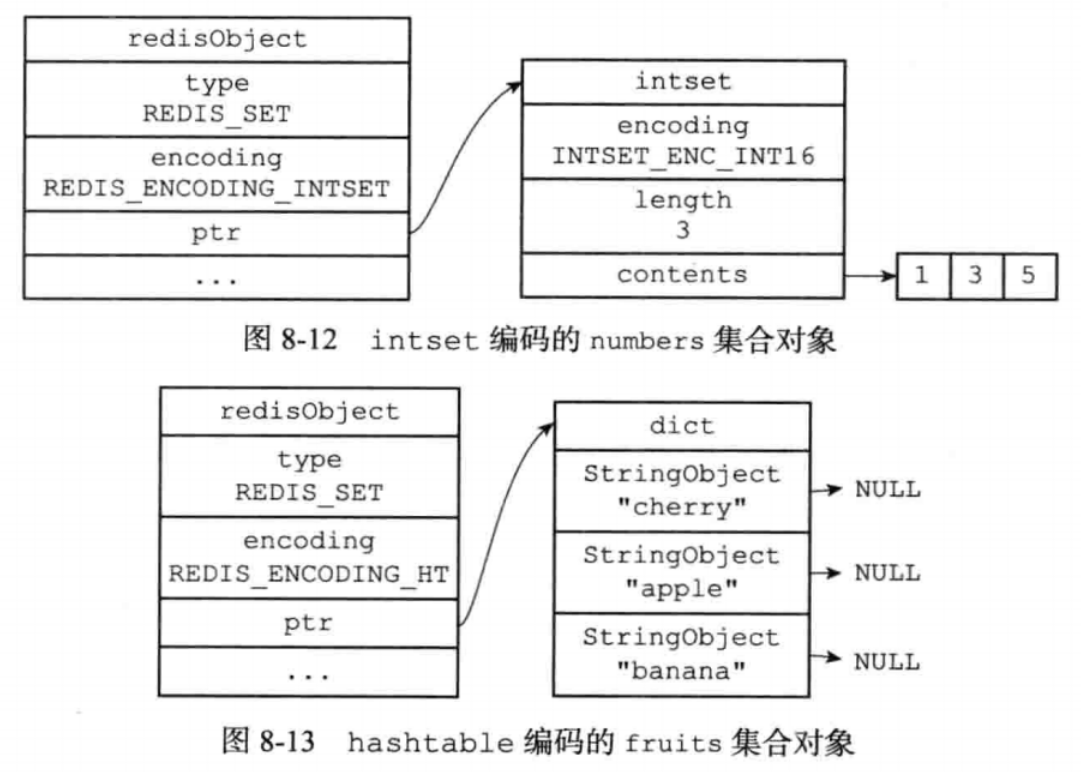
intset和hashtable
集合都是整数,且数量不超过512则用inset否则hashtable
第二个条件可以改变
有序集合对象,有两种实现

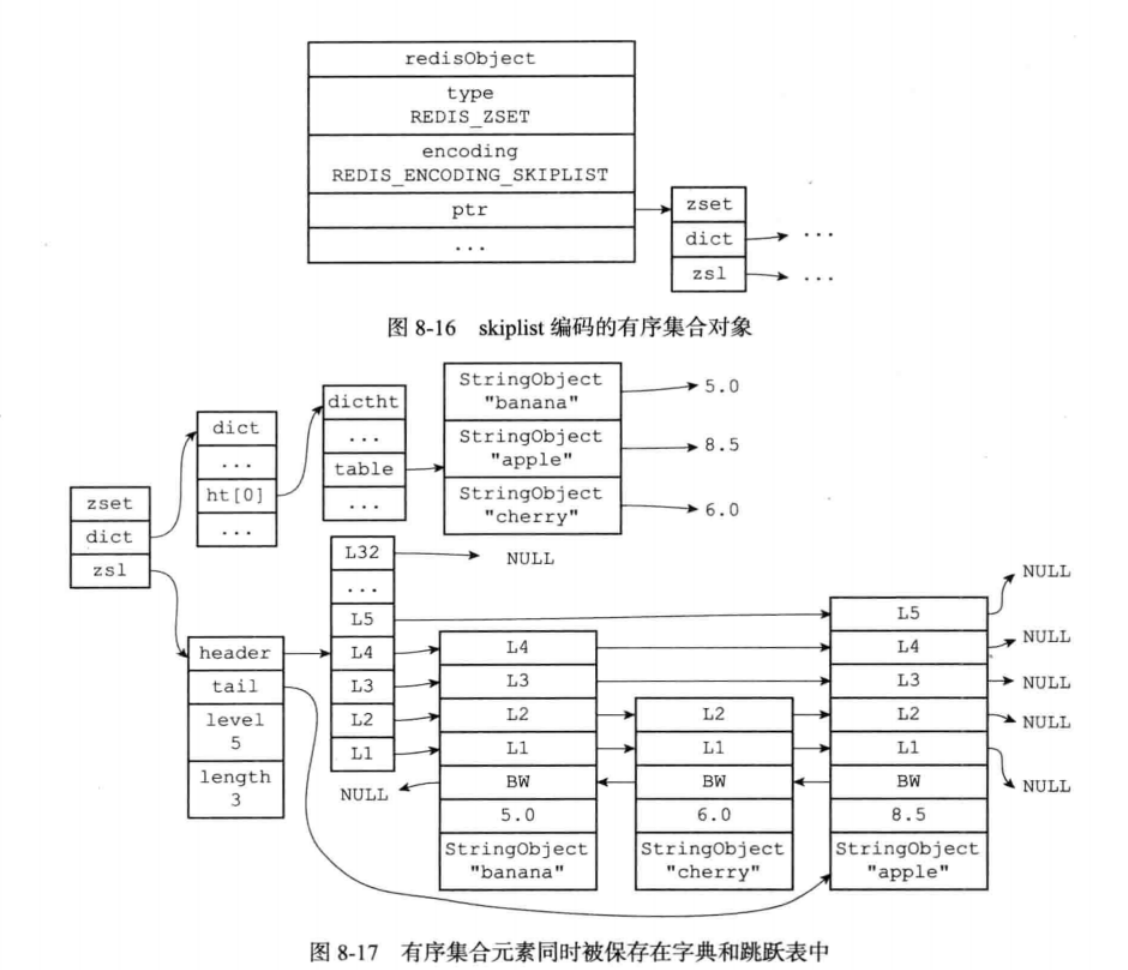
ziplist或者skiplist
ziplist需要保存分值紧挨着,按从小到大排序维护
skiplist的结构用zset表示
typedef struct zset{ zskiplist *zsl; dict *dict; }zset;
除了跳表外,还保留了映射的字典,减少了字典不能范围查找的缺点以及查找效率提高,不会浪费内存,会共享数据。
当保存元素都小于64字节,数量小于128个,则用ziplist,否则skiplist,可以设置改变
会操作键命令对类型进行检查,实现多态。内存回收利用引用计数的方法,会共享一些对象。
为什么redis不共享包含字符串的对象?
因为需要验证是否完全相同,而验证的时候复杂度会高,消耗cpu时间过长。可能达到n^2,验证整数是O(1),字符串是O(n)。
所以redis只对包含整数值的字符串对象共享。
空转时长
实际上就是维护一个lru属性。该属性记录了对象最后一次被命令执行的时间,空转时长就是当前时间减去lru的值。