一:java集合框架如下图所示:
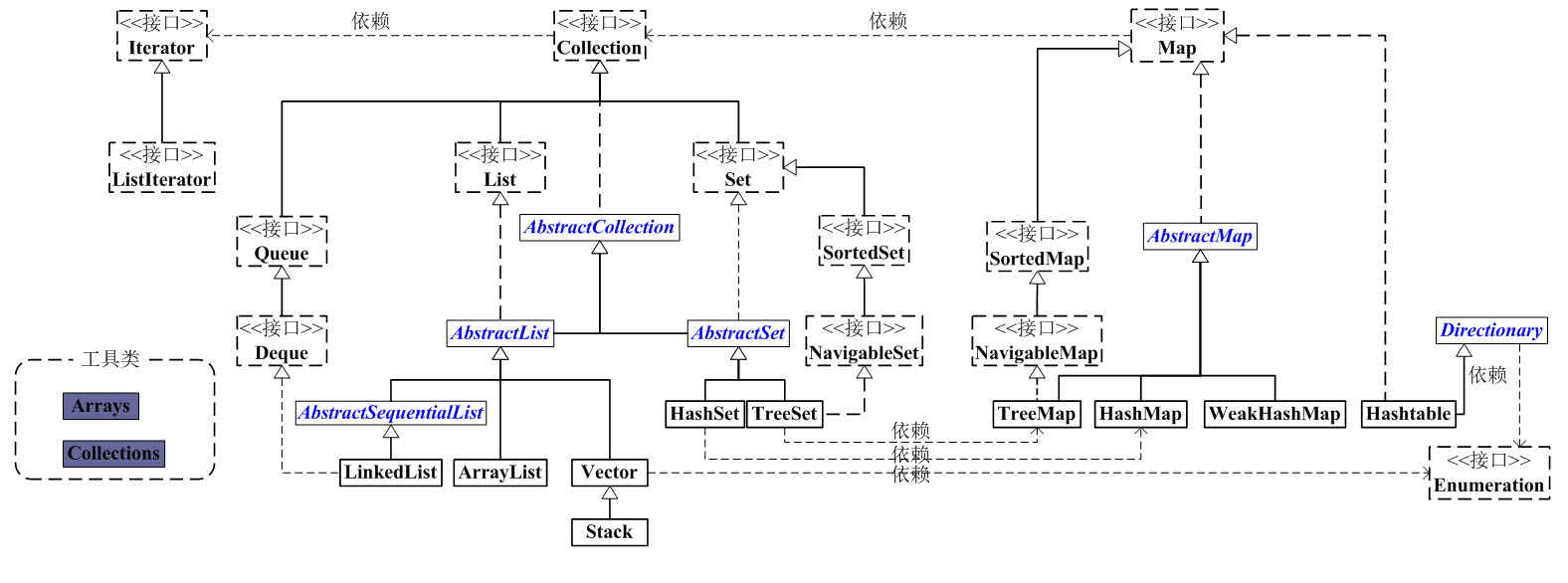
大致说明:
看上面的框架图,先抓住它的主干,即Collection和Map。
1、Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作和属性。Collection包含了List和Set两大分支。
(1)List是一个有序的队列,每一个元素都有它的索引。第一个元素的索引值是0。List的实现类有LinkedList, ArrayList, Vector, Stack。
(2)Set是一个不允许有重复元素的集合。Set的实现类有HastSet和TreeSet。HashSet依赖于HashMap,它实际上是通过HashMap实现的;TreeSet依赖于TreeMap,它实际上是通过TreeMap实现的。
2、Map是一个映射接口,即key-value键值对。Map中的每一个元素包含“一个key”和“key对应的value”。AbstractMap是个抽象类,它实现了Map接口中的大部分API。而HashMap,TreeMap,WeakHashMap都是继承于AbstractMap。Hashtable虽然继承于Dictionary,但它实现了Map接口。
3、接下来,再看Iterator。它是遍历集合的工具,即我们通常通过Iterator迭代器来遍历集合。我们说Collection依赖于Iterator,是因为Collection的实现类都要实现iterator()函数,返回一个Iterator对象。ListIterator是专门为遍历List而存在的。
二.具体详细讲解:
1.List接口:
有序的 collection(也称为序列),允许重复,此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
2.ArrayList原理:
当我们调用无参构造方法来构造ArrayList对象的时候,它会在内部分配一个出事大小为10的一个Object类型数组,当添加的数组容量超过数组大小的时候会产生一个新的数据,新的数组大小为原来数据大小的1.5倍,接着把元数组
中的数据拷贝到新的数组中;
3.LinkedList原理:
LinkedList内部封装的是双向链表数据结构,每一个节点是一个Node对象,Node对象中封装的是你要添加的元素,还有一个指向上一个Node对象的应用和指向下一个Node对象的引用,不同的容器有不同的数据结构,不同的数据结构操作起来性能是
不一样的,链表数据结构做添加、删除的效率比较高,做查询效率比较低;数组结构,做查询效率高,因为可以通过下标直接找到元素,但添加和删除效率比较低,因为要做以为操作;
4.Map接口详解:
映射(map):是一个存储键/值对的对象,给定一个键,可以查询得到它的值,键和值都是对象;
键必须唯一,值可以重复,有些映射可以接收null键和null值,有些则不行;
Map:映射唯一关键字给值;
Map.Entry:描述映射中的元素(关键字/值对),这是Map的一个内部类;
SortedMap:扩展Map以便关键字按照升序保持;
5.HashMap类:基于哈希表的map接口的实现,并允许使用null键和null值;
HashMap实现Map并扩展AbstractMap,本身并没有增加任何新的方法;
散列映射不保证它的元素的顺序,元素加入散列映射的顺序并不一定是它们被迭代读出的顺序;
//当我们调用put(key,value)方法的时候,首先会把key和value封装到Entry这个静态类对象中,
//把Entry对象再添加到数组中,所以我们想获取map中的所有键值对,我们只需要取得数组的所有Entry对象,接下来调用Entry对象
//中的获取键值对的方法
/*hashmap调用默认构造方法会产生一个底层长度为16的Entry数组,
* int hash =hash(key.hashCode());
* 首先调用key的hashcode方法得到一个整数--哈希码
* 把哈希码作为参数传递到hash函数中进行运算-散列函数得到一个整数值
* int i= indexFor(hash,table.length);
* 把散列值和数组的长度进行运算,最终得到Entry对象要存放的数组的位置;
* hashmap的内部结构是数组链表结构,因为不同的key有可能算出来是相同的数列值,根据数列值计算出存放的数组的下表会冲突;
6.哈希码:
当调用对象的hashCode()方法时会返回当前对象的哈希码值,支持此方法是为了提高哈希表的性能;
hashCode的常规协定:
若根据equals(Object)方法,两个对象是相等的,那么对这两个对象中的对象调用hashCode()方法都必须生成相同的整数结果;
同一对象:HashCode相同且或者键相同或者equals相同;
7.TreeMap:
TreeMap类通过使用红黑树实现Map接口,提供按排序顺序存储键/值对的有效手段,同时允许快速检索,不像散列映射,树映射保证它的元素按关键字升序排列;
TreeMap实现SortedMap并且扩展AbstractMap,它本身并没有定义其他方法;
/*TreeMap的key存储引用类型数据,需要满足一定条件:
* 要么引用类型实现Comparable接口
* 要么为该TreeMap容器提供实现Comparable接口的比较器对象
* */
8.Set容器:
Set容器是一个不包含重复元素的Collection,并且最多包含你一个null元素,它和list容器相反,Set容器不能保证其元素的顺序,常用实现类有Hash和TreeSet;
9.HashSet:
HashSet扩展AbstractSet并且实现Set接口,HashSet使用散列表(又称哈希表)进行存储,没有定义任何超过他的父类和接口提供的其他方法;
散列集合没有确保其元素的顺序,因为散列通常不参与排序;
10.TreeSet:
TreeSet为使用树来进行存储的Set接口提供了一个工具,对象按升序存储,访问和检索很快;在存储了大量的需要进行快速检索的排序信息时,TreeSet可以得到很好的应用;
TreeSet的内部操作的底层结构是TreeMap,只是我们操作的是TreeMap的key;
11.Collections类:
Collections类是类集工具类,定义了若干用于类集合映射的算法,这些算法被定义为静态方法;