集成学习不是一种具体的算法,而是在机器学习中为了提升预测精度而采取的一种或多种策略。其原理是通过构建多个弱监督模型并使用一定策略得到一个更好更全面的强监督模型。集成学习简单的示例图如下:

通过训练得到若干个个体学习器,并通过一定策略得到一个集成学习器。
集成方式因为学习算法的不同又分为“同质”和“异质”,如果个体学习器中只包含一种学习算法,例如都是决策树,或都是神经网络,这样的集成就是同质集成,如果个体学习器中包含了多种学习算法,则称为异质集成。
集成学习的目的是得到一个比单一学习器预测性能更好的集成学习器,这就要求个体学习器“好而不同”,要求个体学习器有一定的准确性,同时又有一定的差异性。
下图是西瓜书中的一个图示,浅显易懂地表示出了个体学习器对集成学习效果的影响,用四个字来归纳就是“好而不同”

现在的集成学习大致可以分为两大类:Boosting和Bagging。
Boosting:个体学习器间存在强依赖关系,根据其表现,对训练样本进行调整,使得之前分类错误的样本后续更受关注,用改变后的样本学习下一个分类器。重复学习N个分类器。
Bagging:个体学习器间不存在强依赖关系,可同时训练生成,要求个体学习器之间有较大的差异性。
-- Boosting
Boosting的算法原理如下图:

Boosting方法可以看做是一个不断迭代训练的方法,首先用初始权重训练一个弱分类器1,根据1的误差来更新训练样本的权重,正确的样本权重下降,错误样本的权重变高,使得前一个分类器中分类错误的样本在下一个弱分类器训练中得到更多的重视。这样经过T个迭代后,得到T个弱分类器,将这T个弱分类器通过一定策略进行组合,最后得到效果较好的强分类器。
Adaboost是Boosting方法的典型代表,下面以Adaboost为例简单讲述下整个集成学习的过程。
1、如下图1所示,有两类共10个数据样本,开始时,训练数据中每个样本被赋予一个相等的初始权重,都为0.1,构成权重向量D

2、在训练集上训练出一个弱分类器并计算该分类器的错误率和分类器权重,我们采用直线对数据集进行分类(实际情况中可能是决策树等经典学习算法),从图上来看,有3个数据样本分类错误,可根据公式计算误差![]()
、分类器权重![]()
,然后再根据公式分别更新正确分类样本权重和错误分类样本权重;
正确分类样本权重更新: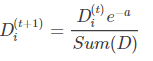
错误分类样本权重更新: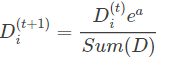

3、第二次迭代再进行分类,如下图,同样有3个点分错了,分类器2的错误率和分类器权重根据公式可计算如下:

4、第三次迭代进行分类,同样可以计算出分类器3的错误率和分类器权重:

5、将每个弱分类器按照分类结果与分类器权重相乘累加的形式组合起来,如果得到的分类结果误差为0或者分类器数目达到用户指定的值,则迭代结束。本例经过3次迭代,最后的集成分类器分类效果如下:

sklearn中已经实现了Adaboost的方法,可直接调用,下面示例代码展示了采用单一分类器和Adaboost方法的准确率的差别,可以看到集成学习在分类准确率上有明显的提升。
import pandas as pd
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import AdaBoostClassifier
from sklearn import tree
breast_data = datasets.load_breast_cancer()
data = pd.DataFrame(datasets.load_breast_cancer().data)
data.columns = breast_data['feature_names']
data_np = breast_data['data']
target_np = breast_data['target']
x_train, x_test, y_train, y_test = train_test_split(data_np,target_np,test_size = 0.3,random_state = 0)
# 采用一个弱分类器(决策树)进行分类
model = tree.DecisionTreeClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
# 基分类器采用决策树的Adaboost分类,迭代10次
model = AdaBoostClassifier(n_estimators=10, algorithm='SAMME')
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
=============================================================
0.9064327485380117
0.9473684210526315
-- Bagging
Bagging的算法原理如下图:

bagging相比boosting最大的不同在于多个弱学习器之间没有依赖关系,可以并行训练生成,通过T次对训练样本的随机采样(有放回的随机采样),可以得到T个训练集,进而可以训练出T个弱分类器。再将这T个分类器按照一定策略进行结合,最终得到分类准确率较高的集成分类器。
随机森林是最有代表性的bagging方法,它是以决策树为基学习算法,通过多个采样训练集训练多个决策树,并通过投票(Voting)或是加权投票的策略确定分类结果的强分类器。
如下示例代码展示了随机森林在sklearn中是如何应用的,同样相比单一的决策树模型,随机森林的分类准确率也有较大的提升:
import pandas as pd
from sklearn import datasets
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
from sklearn.ensemble import RandomForestClassifier
breast_data = datasets.load_breast_cancer()
data = pd.DataFrame(datasets.load_breast_cancer().data)
data.columns = breast_data['feature_names']
data_np = breast_data['data']
target_np = breast_data['target']
x_train, x_test, y_train, y_test = train_test_split(data_np,target_np, test_size = 0.3,random_state = 0)
# 通过决策树模型进行预测
model = tree.DecisionTreeClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
# 通过随机森林进行分类预测
model = RandomForestClassifier()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)
print(accuracy_score(y_test, y_pred))
================================================
0.9181286549707602
0.9649122807017544作者:华为云专家周捷