学习笔记
这一章节系统性地学习了C语言的文件操作和I/O库函数,介绍了I/O库函数和系统调用之间的关系。I/O可以简单理解为输入(input)和输出(output),是最简单的人机交互,不过实际上系统调用就能解决计算机的读写问题,但其功能较为基础,若要实现一些更加复杂的功能则需要借助I/O 设备,I/O 设备的多样性及复杂性,给程序设计者访问这些设备带来了很大的难度和不便,这里就有一个关于“流”的概念。标准 I/O 系统把任意输入的源端或任意输出的终端,都抽象转换成了概念上的“标准 I/O 设备”或称“标准逻辑设备”。程序绕过具体设备,直接与该“标准逻辑设备”进行交互,这样就为程序设计者提供了一个不依赖于任何具体 I/O 设备的统一操作接口,通常把抽象出来的“标准逻辑设备”或“标准文件”称作“流”。“流”一般有两种,文本流以 ASCII 码字符序列传输,二进制流以字节序列传递信息。
弄懂I/O的基本原理后,书中介绍了若干常用的I/O库函数,并对这些函数的功能用法、注意事项进行了讲解,通过书中的一些练习我综合运用了这些文本操作函数,对知识进行了巩固。章节的最后几页介绍了一些变参函数,对于这一块内容我进行了检视阅读。
知识点归纳以及自己最有收获的内容
文本文件与二进制文件
根据文件中数据的组织形式的不同,可以把文件分为:文本文件和二进制文件。
- 文本文件:把要存储的数据当成一系列字符组成,把每个字符的 ASCII 码值存入文件中。每个 ASCII 码值占一个字节,每个字节表示一个字符。故文本文件也称作字符文件或 ASCII 文件,是字符序列文件。
- 二进制文件:把数据对应的二进制形式存储到文件中,是字节序列文件。
| 字 符 | ‘ 1 ’ |
|---|---|
| 二进制 | 0011 0001 |
| 十进制 | 49 |
缓冲和非缓冲文件系统
C语言中文件系统可分为两大类,一种是缓冲文件系统也称为标准文件系统,另一种是非缓冲文件系统。ANSI C 标准中只采用缓冲文件系统。
缓冲文件系统:系统自动为每个打开的文件在内存开辟一块缓冲区,缓冲区的大小一般由系统决定。当程序向文件中输出(写入)数据时,程序先把数据输出到缓冲区,待缓冲区满或数据输出完成后,再把数据从缓冲区输出到文件;当程序从文件输入(读取)数据时,先把数据输入到缓冲区,待缓冲区满或数据输人完成后,再把数据从缓冲区逐个输入到程序。
非缓冲文件系统:系统不自动为打开的文件开辟内存缓冲区,由程序设计者自行设置缓冲区及大小。
程序每一次访问磁盘等外存文件都需要移动磁头来定位磁头扇区,如果程序频繁地访问磁盘文件,会缩短磁盘的寿命,况且速度较慢,与快速的计算机内存处理速度不匹配。
带缓冲区文件系统的好处是减少对磁盘等外存文件的操作次数,先把数据读取(写入)到缓冲区中,相当于把缓冲区中的数据一次性与内存交互,提髙了访问速度和设备利用率。
一般把带缓冲文件系统的输入输出称作标准输入输出(标准 I/O),而非缓冲文件系统的输入输出称为系统输入输出(系统 I/O)。
文件的打开与关闭
这里的“打开”和“关闭”可调用标准库 stdio.h 中的 fopen 和 fclose 函数实现。在书中介绍可知,
打开函数 fopen 的原型如下。
FILE * fopen(char *filename, char *mode);
函数参数:
1.filename:文件名,包括路径,如果不显式含有路径,则表示当前路径。例如,“D:f1.txt”表示 D 盘根目录下的文件 f1.txt 文件。“f2.doc”表示当前目录下的文件 f2.doc。
2.mode:文件打开模式,指出对该文件可进行的操作。常见的打开模式如 “r” 表示只读,“w” 表示只写,“rw” 表示读写,“a” 表示追加写入。
返回值:打开成功,返回该文件对应的 FILE 类型的指针;打开失败,返回 NULL。故需定义 FILE 类型的指针变量,保存该函数的返回值。可根据该函数的返回值判断文件打开是否成功。
关闭函数 fclose 的原型如下。
int fclose(FILE *fp);
函数参数:
fp:已打开的文件指针。
返回值:正常关闭,返回否则返回 EOF(-1)。
编程演示文件的打开和关闭:
FILE *fpl,*fp2; //定义两个文件指针变量fpl和fp2
fpl=fopen(”D:\fl.txt”,”r”); //以只读模式打开文件 fl.txt
if (NULL==fpl) //以返回值fpl判断是否打开成功,如果为NULL表示失败
{
printf ("Failed to open the file !
");
exit (0) ; //终止程序,stdlib .h头文件中
}
fp2=fopen ("f2.txt","a") ; //以追加写入的模式打开文件f2 .txt
if(NULL==fp2)
{
printf ("Failed to open the file !
");
exit (0);
}
fclose (fpl); //关闭fpl指针对应文件(fl.txt)的流
fclose (fp2); //关闭fp2指针对应文件(f2.txt)的流
```
文件的顺序读写
换字符输入输出
c 语言中提供了从文件中逐个输入字符及向文件中逐个输出字符的顺序读写函数 fgetc 和 fputc 及调整文件读写位置到文件开始处的函数 rewind。这些函数均在标准输入输出头文件 stdio.h 中。
字符输入函数 fgetc 的函数原型为:
`int fgetc(FILE *fp);`
函数功能:从文件指针 fp 所指向的文件中输入一个字符。输入成功,返回该字符;已读取到文件末尾,或遇到其他错误,即输入失败,则返回文本文件结束标志 EOF
注意:由于 fgetc 是以 unsigned char 的形式从文件中输入(读取)一个字节,并在该字节前面补充若干 0 字节,使之扩展为该系统中的一个 int 型数并返回,而非直接返回 char 型。当输入失败时返回文本文件结束标志 EOF 即 -1,也是整数。故返回类型应为 int 型,而非 char 型。
字符输出函数 fputc 的函数原型为:
`int fputc (intc,FILE *fp);`
函数功能:向 fp 指针所指向的文件中输出字符 c,输出成功,返回该字符;输出失败,则返回 EOF(-1)。
文件读写位置复位函数 rewind 的函数原型为:
`void rewind (FILE *fp);`
函数功能:把 fp 所指向文件中的读写位置重新调整到文件开始处。
接字符串输入输出
字符串输入函数 fgets 的函数原型为:
`char * fgets (char *s, int size, FILE * fp);`
函数功能:从 fp 所指向的文件内,读取若干字符(一行字符串),并在其后自动添加字符串结束标志 '�' 后,存入 s 所指的缓冲内存空间中(s 可为字符数组名),直到遇到回车换行符或已读取 size-1 个字符或已读到文件结尾为止。该函数读取的字符串最大长度为 size-1。
字符串输出函数 fputs 的函数原型为:
`int fputs (const char *str, FILE *fp);`
函数功能:把 str(str 可为字符数组名)所指向的字符串,输出到 fp 所指的文件中。
按格式化输入输出
文件操作中的格式化输入输出函数 fscanf 和 fprintf 一定意义上就是 scanf 和 printf 的文本版本。程序设计者可根据需要采用多种格式灵活处理各种类型的数据,如整型、字符型、浮点型、字符串、自定义类型等。
文件格式化输入函数 fscanf 的函数原型为:
`int fscanf (文件指针,格式控制串,输入地址表列);`
函数功能:从一个文件流中执行格式化输入,当遇到空格或者换行时结束。注意该函数遇到空格时也结束,这是其与 fgets 的区别,fgets 遇到空格不结束。
文件格式化输出函数 fprintf 的函数原型为:
`int fprintf (文件指针,格式控制串,输出表列);`
函数功能:把输出表列中的数据按照指定的格式输出到文件中。
按二进制方式读写数据块
按块读写数据的函数 fread 和 fwrite,这两个函数主要应用于对二进制文件的读写操作,不建议在文本文件中使用。书本介绍了 fread 读取二进制文件时,判断是否已经到达文件结尾的函数 feof。
数据块读取(输入)函数 fread 的函数原型为:
unsigned fread (void buf, unsigned size, unsigned count, FILE fp);
```
函数功能:从 fp 指向的文件中读取 count 个数据块,每个数据块的大小为 size。把读取到的数据块存放到 buf 指针指向的内存空间中。
函数参数:
- buf:指向存放数据块的内存空间,该内存可以是数组空间,也可以是动态分配的内存。void类型指针,故可存放各种类型的数据,包括基本类型及自定义类型等。
- size:每个数据块所占的字节数。
- count:预读取的数据块最大个数。
- fp:文件指针,指向所读取的文件。
在操作文件时,经常使用 feof 函数来判断是否到达文件结尾。
feof 函数的函数原型为: int feof (FILE * fp);
函数功能:检查 fp 所关联文件流中的结束标志是否被置位,如果该文件的结束标志已被置位,返回非 0 值;否则,返回 0。
需要注意的是:
- 在文本文件和二进制文件中,均可使用该函数判断是否到达文件结尾。
- 文件流中的结束标志,是最近一次调用输入等相关函数(如 fgetc、fgets、fread 及 fseek 等)时设置的。只有最近一次操作输入的是非有效数据时,文件结束标志才被置位;否则,均不置位。
最有收获的内容
书中主要介绍的基本都是文件的顺序读写操作,即每次只能从文件头开始,从前往后依次读写文件中的数据。在实际的程序设计中,经常需要从文件的某个指定位置处开始对文件进行选择性的读写操作,这时,首先要把文件的读写位置指针移动到指定处,然后再进行读写,这种读写方式称为对文件的随机读写操作。不过在书中这些函数没有被重点介绍,这里摘录了fseek这种函数,实际使用的过程中我觉得这一函数的实用性更强一些,因为很多时候我们需要随机读写而非顺序读写。
函数 fseek 的函数原型为:
int fseek(FI:LE *fp, long offset, int origin);
函数功能:把文件读写指针调整到从 origin 基点开始偏移 offset 处,即把文件读写指针移动到 origin+offset 处。
函数参数: - origin:文件读写指针移动的基准点(参考点)。基准位置 origin 有三种常量取值:SEEK_SET、SEEK_CUR 和 SEEK_END,取值依次为 0,1,2。
SEEK_SET:文件开头,即第一个有效数据的起始位置。
SEEK_CUR:当前位置。
SEEK_END:文件结尾,即最后一个有效数据之后的位置。注意:此处并不能读取到最后一个有效数据,必须前移一个数据块所占的字节数,使该文件流的读写指针到达最后一个有效数据块的起始位置处。 - offset:位置偏移量,为 long 型,当 offset 为正整数时,表示从基准 origin 向后移动 offset 个字节的偏移;若 offset 为负数,表示从基准 origin 向前移动 |offset| 个字节的偏移。
问题与解决思路
编写一个C语言程序,将文本文件中的字母由小写转换为大写
解决思路:开始想要将文本文件转换为ASC码,利用 ASCII 码中大写字母和小写字母之间的转换关系(差值为 32,x小写减大写等于32),可以将小写字母转换为大写字母,char ab可以直接和数字进行加减,代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main ()
{
FILE *fp;
char Filename[50], ch;
int a = 0;
printf("Enter PathName:");
scanf("%s", Filename);
if((fp = fopen(Filename, "r")) == NULL) //习惯性操作,检查文件打开是否为空
{
printf("File open failed!
");
exit(0);
}
while(!feof(fp)) //指针是否移动到文件结束标志EOF处
{
ch = fgetc(fp); //
if(ch != EOF)
{
if(ch >= 'a' && ch <= 'z')
{
ch -= 32;
}
if(ch == '
')
{
a++;
}
printf("%c", ch);
}
}
printf("%d
", a);
return 0;
}
发现在vim中进行编写较为麻烦,故选择在windows系统下先敲好代码,然后将文件复制到虚拟机当中,运用命令检验效果,截图如下:
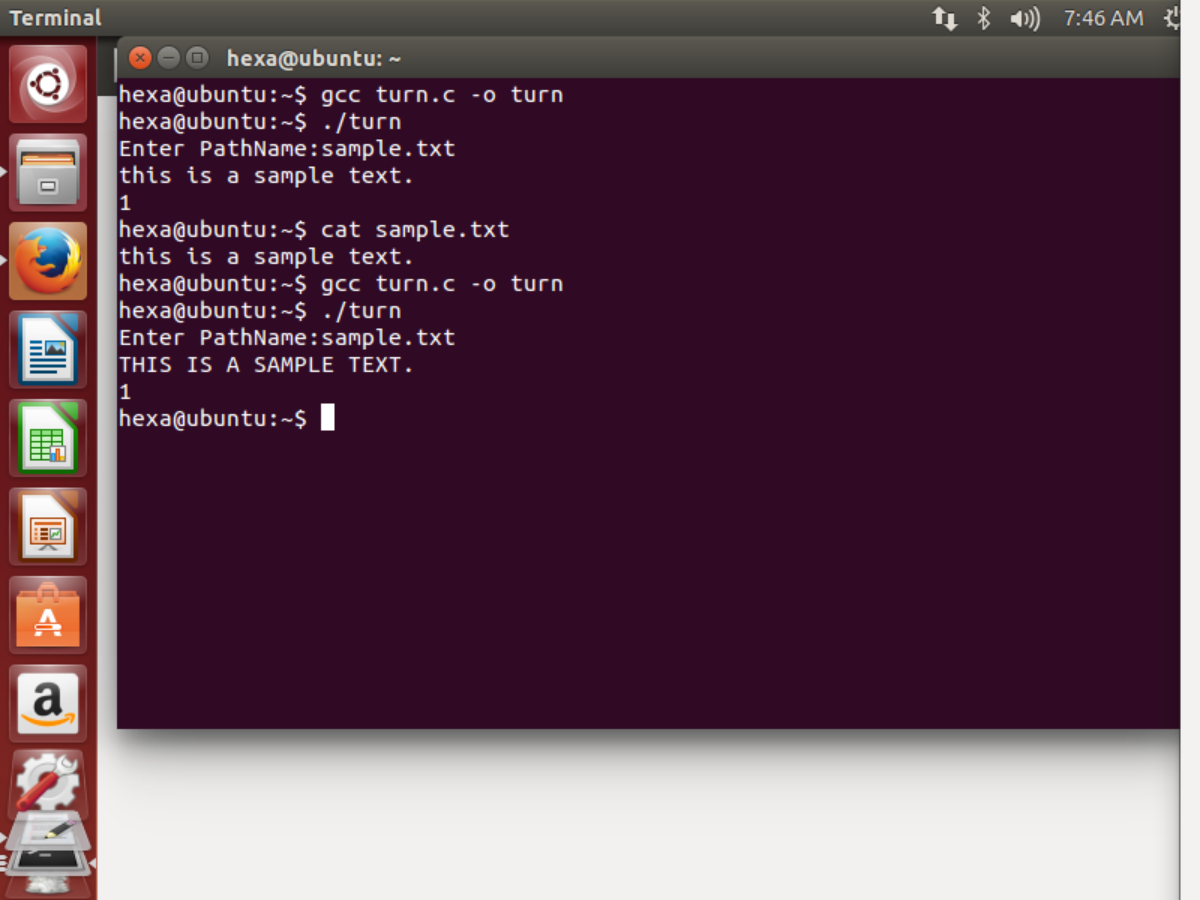
运用cat命令可知命令并没有实质改变文件的内容,但会文本文件进行大小写转换而后输出。