20189224 2018-2019-2 《密码与安全新技术专题》课程总结报告
课程:《密码与安全新技术专题》
班级: 1892
姓名: 史馨怡
学号:20189224
上课教师:王志强
必修/选修: 选修
1 课程学习内容总结
1.1 教师讲座
(1)Web应用安全——张健毅老师
- 常见的web漏洞的介绍:SQL注入,跨站脚本攻击漏洞,CSFR(跨站请求伪造),Web信息泄露,权限问题,逻辑漏洞,第三方程序漏洞,Web服务器解析漏洞,弱口令,SSRF
- 机器学习在Web安全相关应用的介绍:鱼叉(Spear Phishing,Catfishing)、水坑式攻击(Watering Holes)、内网漫游(Lateral Movement)、隐蔽信道检测(Covert Channel Detection)、注入攻击(Injection Attacks)、网页木马(Webshell)、凭证盗窃(Credential Theft)
(2)量子保密通信——孙莹老师
- 量子密码的研究背景:
对称密码体制(优点:加密速度快,适合批量加密数据;缺点:密钥分配、密钥管理、没有签名功能);
公钥密码体制(基于大数分解等数学难题,优点:可解决密钥分配、管理问题,可用于签名;缺点:加密速度慢);
混合密码体制(用公钥密码体制分发会话密钥,用对称密码体制加密数据);
安全性挑战(Shor算法:大数分解算法多项式时间内解决大数分解难题受影响密码体制;Grover算法:快速搜索算法可以加速搜索密钥受影响密码体制:DES,AES等对称密码) - 量子通信相关基本物理概念:
量子的概念(微观世界物理量相邻分立值的差称为该物理量的一个量子/具有特殊性质的微观粒子或光子);
量子态(经典信息:比特0或1,可用高低电压等表示);
量子信息(量子比特|0>,|1>量子比特还可以处在不同状态的叠加态上);
不可克隆定理(未知量子态不可克隆);
测不准原理(未知量子态不可准确测量) - 量子通信基本模型介绍:
信息传输(通常同时用到量子信道和经典信道,量子信道传输量子载体,经典信道传输经典消息);
纠错(随机选择部分量子载体,比较初末状态,对比较的协议来说,窃听必然干扰量子态,进而引入错误,一旦发现存在窃听则终止通信,丢弃相关数据);
窃听检测(纠正密钥中的错误);
保密增强(通过压缩密钥长度,将窃听者可能获得的部分密钥信息压缩至任意小,得到安全的密钥) - 量子通信研究现状
量子密钥分发、量子秘密共享、量子安全直接通信、量子身份认证、量子抛币、量子不经意传输;
提高性能、提高效率:可重用基、纠缠增强、双光子、双探测器
提高抗干扰能力:无消相干子空间、量子纠错码
提高实际系统抗攻击能力:诱骗态、设备无关
速率更高、距离更远、安全性更强
(3)基于深度学习的密码分析与设计初探——金鑫老师
- 密码分析与机器学习
机器学习模型:样本x--------------模型(函数fx)---------------标注y
密码分析模型:明文x--------------密钥(函数fx)---------------密文y
研究趋势发展:越来越多的密码分析方法开始使用机器学习技术 - 深度学习简介
深度学习:通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示
深度神经网络:卷积神经网络( CNN: Convolutional NeuralNetworks),循环神经网络( RNN: Recurrent Neural Networks),生成对抗网络( GAN: Generative Adversarial Networks)
深度学习应用实例:人体分割、姿势识别、人脸分割与自动上妆、视觉问答、阿法狗、攻陷Dota2、验证码破解、考试监控作弊行为发现、图像美感自动发现 - 深度学习与密码分析:基于卷积神经网络的侧信道攻击,基于循环神经网络的明文破译,基于生成对抗网络的口令破解,基于深度神经网络的密码基元识别
- 深度学习与密码设计
通信安全
计算安全 建立安全的开放融合网络环境 物联网环境下协作通信处理安全需求
存储安全-------------------------------------->云计算环境下协作通信处理安全需求
密钥建立和认证 量子计算技术发展对密码的安全
密码资源保护
(4)信息隐藏技术——夏超老师

(5)区块链技术——张健毅老师
- 区块链基本概念
区块:比特币网络中,数据以文件的形式被永久记录,称之为区块(Block)。记录交易单的数据单元叫做Block,一个Block上会记录很多交易单。
区块链:所有的Block以双向链表的方式链接起来,且每个Block都会保存其上一个Block的Hash值。只有一个Block无上一节点,即创世Block(第一个Block)。 - 区块链技术
点对点对等网络:区块链可以理解为是一个去中心化的分布式数据库。这个数据库不依赖任何机构和管理员,区块链的作用就是存储信息,数据库的数据由全网的节点共同维护,任何人都可以接入区块链网络,成为一个数据节点。如果向数据节点写入数据,这个节点会将写入的数据信息广播到相邻的节点,然后相邻的节点再广播到它们相邻的节点,最终会将信息广播给全网的所有节点,最后所有的节点会同步数据,保证一致性。
共识机制:POW、POS、DPOS
数据可验证性:PKI公钥体系、不可变数据
奖励合作的制度设计:非合作博弈、合作达到纳什均衡 - 区块链未来:货币、合约、治理交叉均衡
(6)漏洞挖掘技术——王志强老师
- 常见漏洞挖掘技术的介绍:
手工测试(由测试人员手工分析和测试被测目标发现漏洞的过程,是最原始漏洞挖掘方法);
补丁对比(一种通过对比补丁之间的差异来挖掘漏洞的技术);
程序分析(静态和动态);
二进制审核(源代码不可得,通过逆向获取二进制代码,在二进制代码层次进行安全评估);
模糊测试(通过向被测目标输入大量的畸形数据并监测其异常来发现漏洞) - 漏洞挖掘技术研究进展
发展方向:AI——机器学习——深度学习
1)二进制程序函数识别:现有的反汇编分析工具具有识别正确率低的缺陷;使用循环神经网络算法RNN进行二进制程序函数识别的模型训练。
2)测试用例生成:在软件漏洞挖掘中,构造代码覆盖率高或脆弱性导向型的测试输入能提高漏洞挖掘的效率和针对性。可以使用机器学习来指导生成更高质量的测试输入样本
3)测试用例筛选
4)路径约束求解:模糊测试侧重于筛选可以覆盖新路径的样本为种子文件,但对种子文件变异时并没有充分利用程序数据流等。具备路径约束求解能力是符号执行比模糊测试等漏洞挖掘技术更先进的体现。Angora采用污点追踪测试输入中影响条件分支的字节,然后使用梯度下降的方式对变异后生成的路径约束进行求解
漏洞挖掘示例 - 漏洞挖掘示例:路由器协议漏洞挖掘、NFC漏洞挖掘
1.2 同学报告
(1)第一小组(张宇翔、鲍政李):Finding Unknown Malice in 10 Seconds: Mass Vetting for New Threats at the Google-Play Scale
文章贡献:
- 开发了一种名为MassVet的新技术,可在无需了解恶意软件的外观和行为方式情况下对应用程序进行大规模审查,。
- 构建了“DiffCom”分析,该算法将应用程序的UI结构或方法的控制流图的显著特征映射到一个快速比较的值。
- 在流处理引擎上实施了MassVet,并评估了来自全球33个应用市场的近120万个应用程序,即Google Play的规模。
- 实验表明该技术可以在10秒内以低错误检测率审核应用程序且在检测覆盖率方面优于VirusTotal(NOD32,赛门铁克,迈克菲等)的所有54台扫描仪,捕获了超过10万个恶意应用程序,包括20多个可能的零日恶意软件和数百万次安装的恶意软件。
工作思路
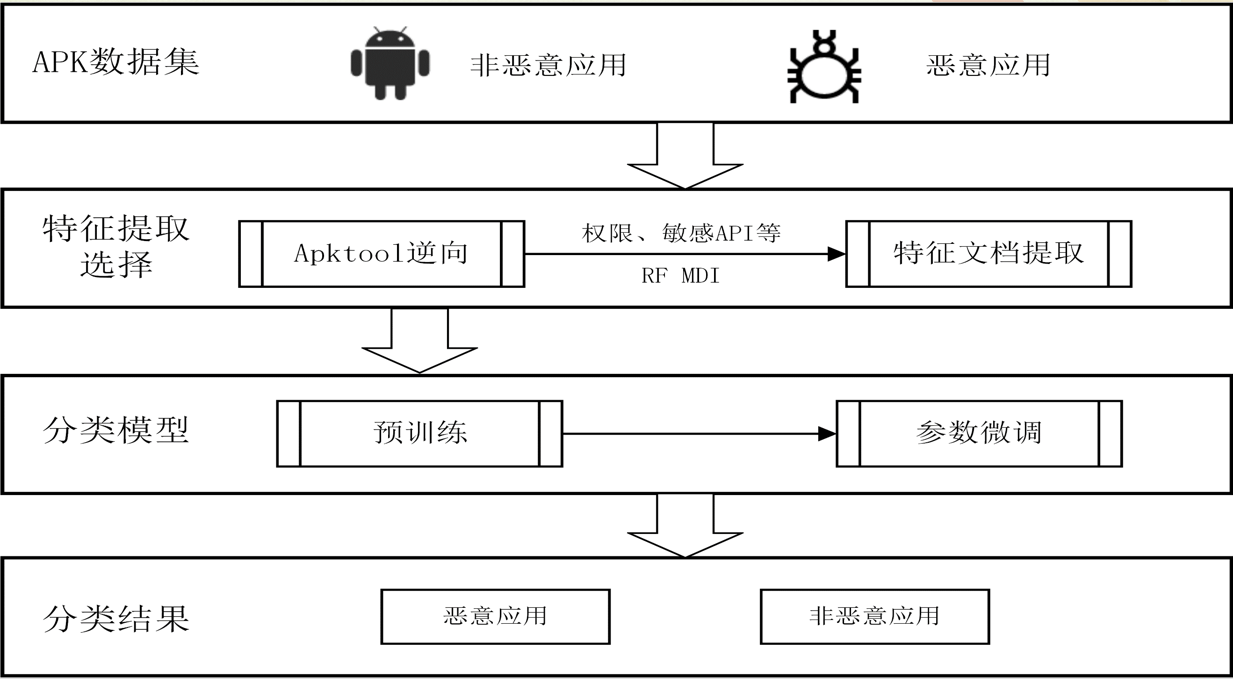
核心方法
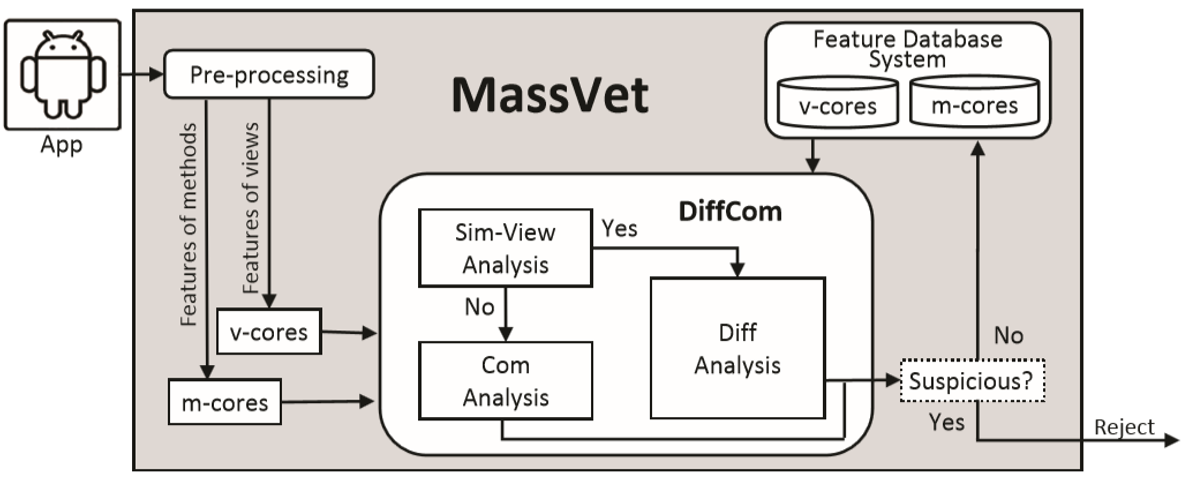
MassVet首先处理所有的应用程序,包括用于查看结构的数据库和用于数据库的数据库。两个数据库都经过排序以支持二进制搜索,并用于审核提交到市场的新应用程序。重新包装的AngryBird一旦上载到市场,首先在预处理阶段自动拆解成一个小型表示,从中可以识别其接口结构和方法。它们的功能通过计算映射到v核(视图中心)和m核(控制流的几何中心)。应用程序的v-cores首先用于通过二进制搜索查询数据库。一旦匹配满足,当存在具有类似的AngryBird用户界面结构的另一个应用程序时,将重新打包的应用程序与方法级别的市场上的应用程序进行比较以识别它们的差异。然后自动分析这些差异以确保它们不是广告库并且确实是可疑的,如果是,则向市场报。当没有任何东西时,MassVet继续寻找方法数据库中的AngryBird的m核心。
(2)第二小组(冯乾、李炀):Spectre Attacks: Exploiting Speculative Execution
论文内容总结:
-
Spectre Attacks(幽灵攻击):主要利用CPU的预测执行功能漏洞发起攻击,导致攻击发生时受害者毫无察觉。
-
Speculative Execution(预测执行):一些具有预测执行能力的新型处理器,可以估计即将执行的指令,采用预先计算的方法来加快整个处理过程。其设计理念是:加速大概率事件。
-
欺骗分支预测器:(一个代码示例)

进入if判断语句后,首先从高速缓存查询有无array1_size的值,如果没有则从低速存储器查询,按照我们的设计,高速缓存一直被擦除所以没有array1_size的值,总要去低速缓存查询。查询到后,该判断为真,于是先后从高速缓存查询array1[x]和array2[array1[x]256]的值,一般情况下是不会有的,于是从低速缓存加载到高速缓存。在执行过几次之后,if判断连续为真,在下一次需要从低速缓存加载array1_size时,为了不造成时钟周期的浪费,CPU的预测执行开始工作,此时它有理由判断if条件为真,因为之前均为真(加速大概率事件),于是直接执行下面的代码,也就是说此时即便x的值越界了,我们依然很有可能在高速缓存中查询到内存中array1[x]和array2[array1[x]256]的值,当CPU发现预测错误时我们已经得到了需要的信息。 -
攻击过程:

-
攻击结果:

(3)第三小组(余超、杨晨曦):All Your GPS Are Belong To Us: Towards Stealthy Manipulation of Road Navigation Systems
论文贡献:
- 为了证明该方法的可行性,我们首先通过实现便携式GPS欺骗器并在实际汽车上进行测试来进行受控测量。
- 设计了一种计算Th值的搜索算法,实时移动GPS偏移和受害者路线。
- 使用跟踪驱动的模拟(曼哈顿和波士顿的600个出租车线路)进行广泛的评估,然后通过RE验证完整的攻击AL-世界驾驶考试(攻击我们自己的汽车)。
- 对美国和中国的驾驶模拟器进行了欺骗性的用户研究。
- 探讨了对道路导航系统进行隐身操纵攻击的可行性。
研究思路:
- 四个组件:HackRF One-based前端,Raspberry Pi,便携式电源和天线,使用10000 mAh移动电源作为整个系统的电源
- 将组件连接到频率范围在700MHz至2700MHz之间的天线,覆盖民用GPS频段L1(1575.42兆赫)。
- Raspberry Pi 3B(四核1.2GHz Broad com BCM2837 64位CPU,1GB RAM)用作中央服务器。
- GPS卫星信号由一个Raspberry Pi上运行的无线攻击发射盒(WALB)生成。
- 通过控制Raspberry Pi,手动或使用脚本来获取实时GPS位置信息。
实验结果:
攻击取得了很高的成功率(95%)。在40人中,只有一名美国参与者和一名中国参与者认出了这次袭击。其余的38名参与者都完成了这四项NDS的驱动任务,并跟随导航到达错误的目的地。
研究局限性:
- 学习限制:攻击效果会在郊区降低、攻击并不适用于所有的人
- 用户研究局限性:实验只选择了一个欧洲城市、研究未达到一个大规模的规模、研究只测试了一条路线
(4)第四小组(张鸿羽、李熹桥):With Great Training Comes Great Vulnerability: Practical Attacks against Transfer Learning
论文贡献:
提出了一个新的针对迁移学习的对抗性攻击,即对教师模型白盒攻击,对学生模型黑盒攻击。攻击者知道教师模型的内部结构以及所有权重,但不知道学生模型的所有权值和训练数据集。
攻击思路:

- 将target图狗输入到教师模型中,捕获target图在教师模型第K层的输出向量。
- 对source图加入扰动,使得加过扰动的source图(即对抗样本)在输入教师模型后,在第K层产生非常相似的输出向量。
- 由于前馈网络每一层只观察它的前一层,所以如果我们的对抗样本在第K层的输出向量可以完美匹配到target图的相应的输出向量,那么无论第K层之后的层的权值如何变化,它都会被误分类到和target图相同的标签。
防御方法:
修改学生模型,更新层权值,确定一个新的局部最优值,在提供相当的或者更好的分类效果的前提下扩大它和教师模型之间的差异。
(5)第五小组(王子榛、史馨怡):safeinit:Comprehensive and Practical Mitigation of Uninitialized Read Vulnerabilities
文章成果:
- 提出了SafeInit,一种基于编译器的解决方案
- 通过确保栈和堆上的初始化来自动减轻未初始化的值读取。
- 提出的优化可以将解决方案的开销降低到最低水平(<5%),并且可以直接在现代编译器中实现基于clang和LLVM的SafeInit原型实现,并表明它可以应用于大多数真实的C / C++应用程序而无需任何额外的手动工作。
- 评估我们在CPU-intensiv占用CPU资源的操作、IO-intensive占用I/O设备的操作以及Linux内核方面的工作,并验证是否成功地减轻了现存的漏洞
LLVM架构
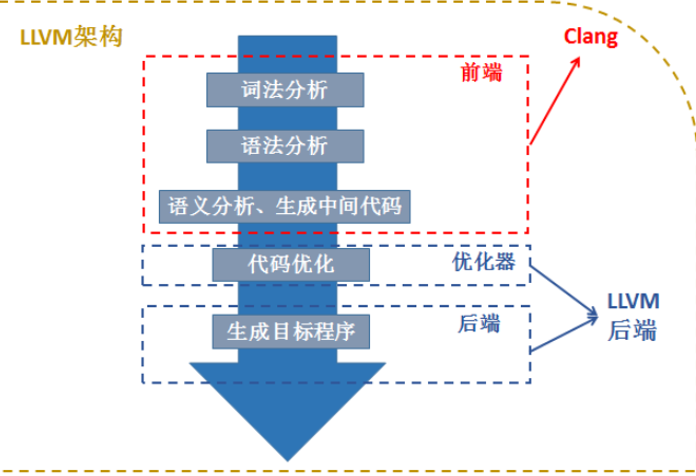
LLVM包括了一个狭义的LLVM和一个广义的LLVM。广义的LLVM其实就是指整个LLVM编译器架构,包括了前端、后端、优化器、众多的库函数以及很多的模块;而狭义的LLVM其实就是聚焦于编译器后端功能(代码生成、代码优化等)的一系列模块和库。Clang是一个C++编写、基于LLVM的C/C++/Objective-C/Objective-C++编译器。Clang是一个高度模块化开发的轻量级编译器,它的编译速度快、占用内存小、非常方便进行二次开发。上图是LLVM和Clang的关系:Clang其实大致上可以对应到编译器的前端,主要处理一些和具体机器无关的针对语言的分析操作;编译器的优化器部分和后端部分其实就是我们之前谈到的LLVM后端(狭义的LLVM);而整体的Compiler架构就是LLVM架构。
safeinit架构

如图编译器在获得C/C++文件后,编译器前端将源文件转换为中间语言(IR),通过初始化、代码优化结合现存编译器的优化器,之后通过无效数据消除、强化分配器最后获得二进制文件。Safeinit在整个过程中所添加的就是 初始化全部变量、优化以及强化分配器,来避免或缓解未初始化值。最后,SafeInit优化器提供了非侵入式转换和优化,它们与现有的编译器优化(必要时自行修改)以及最终组件(现有“死存储消除”优化的扩展)一起运行。这些构建在我们的初始化传递和分配器之上,执行更广泛的删除不必要的初始化代码,证明我们的解决方案的运行时开销可以最小化。
(6)第六小组(郭开世):Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning
论文成果:
- 对线性回归模型的中毒攻击及其对策进行了第一次系统研究。
- 提出了一个针对中毒攻击和快速统计攻击的新优化框架,该框架需要对培训过程的了解很少。
- 采用原则性方法设计一种新的鲁棒防御算法,该算法在很大程度上优于现有的稳健回归方法。
- 在医疗保健,贷款评估和房地产领域的几个数据集上广泛评估作者提出的攻击和防御算法。
- 在案例研究健康应用中证明了中毒攻击的真实含义。
系统架构:

(7)第七小组(杨静怡):Convolutional Neural Networks for Sentence Classification(卷积神经网络用于句子分类)
文章成果:
提出一种将文本转换为类似图像的矩阵,采用CNN来完成文本分类任务的方法,更多的利用到单词的顺序和语义特征。
模型介绍
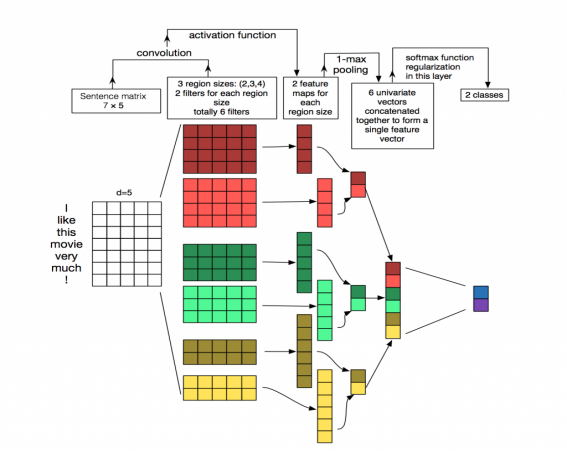
- 输入矩阵
CNN输入矩阵的大小取决于两个因素:A.句子长度(包含的单词的个数)B.每个字符的长度。假设输入X包含m个单词,而每个单词的字嵌入(Word Embedding)长度为d,那么此时的输入就是md的二维向量。对于I like this movie very much!来说,当字嵌入长度设为5时,输入即为75的二维向量。 - 卷积过程
假设输入X包含m个单词,而每个单词的字嵌入(Word Embedding)长度为d,那么此时的输入就是md的二维向量。对于I like this movie very much!来说,当字嵌入长度设为5时,输入即为75的二维向量。
A.filter_size代表卷积核纵向上包含单词个数,即认为相邻几个词之间有词序关系,代码里使用的是[3,4,5]。
B.embedding_size就是词向量的维数。每个卷积核计算完成之后我们就得到了1个列向量,代表着该卷积核从句子中提取出来的特征。有多少卷积核就能提取出多少种特征。 - 池化过程
文章使用MaxPooling的方法对Filter提取的特征进行降维操作,形成最终的特征。每个卷积的结果将变为一个特征值,最终生成一个特征向量。
实验结论
- CNN-rand:所有的word vector都是随机初始化的,同时当做训练过程中优化的参数;
- CNN-static:所有的wordvector直接使用无监督学习即Google的word2vector工具得到的结果,并且是固定不变的;
- CNN-non-static:所有的wordvector直接使用无监督学习即Google的word2vector工具得到的结果,但是会在训练过程中被微调;
- CNN-multichannel:CNN-static和CNN-non-static的混合版本,即两种类型的输入。
2 感想和体会
《密码与安全新技术专题》这门课程开拓了我的视野,让我了解到很多安全相关的技术和研究方向,通过这门课程我发现人工智能技术与安全技术的交叉融合的热度远远超出我的想象。老师们的讲解让我们对不同的领域有了更多的了解,王老师为我们作业中提出的建议也让我们对学习方法如何更好的学习有了新的认识,感谢各位老师的辛苦付出!老师安排的最后这个顶会论文阅读复现的任务也让我收获了很多,从选题到阅读文章到调试代码都有很大的收获,这次选的题目和编译器架构有关,在阅读过程中非常困难,通过查阅资料以及其他同学的帮助下我们理解了这篇文章,虽然最后没能成功复现,但是这个研究过程让我受益匪浅。
3 对本课程的建议和意见
- 课前可以收集一下同学们想了解的内容
- 课上可以多一些实践演示与互动