源地址(本节课无案例):http://cookdata.cn/auditorium/course_room/10021/
往期的课程总结均已在开头处标明了视频源网址,相关案例在视频下方,相关案例若无法下拉查看可以通过F12(谷歌为例)在相应代码中找到网址。
下面进入正题
《机器学习十讲》——第十讲(强化学习)
回顾
机器学习方法:有监督学习,无监督学习,强化学习
有监督学习:有标签有目标
无监督学习:无标签,无目标
强化学习:过程模拟和观察进行学习。
强化学习

策略:在特定状态下应该怎么采取行动。
目标:找到最佳策略,即能够获得最大奖励的策略。
数学模型:马尔可夫决策过程(MDP)
强化学习方法形式化为MDP,MDP是序列决策算法的一般数学框架
通常将MDP表示为四元组(S,A,P,R):

S是离散状态;A可能是离散,也可能是连续的;P通常用来描述模型。
马尔可夫假设:状态不断转移,随着时间可以写成St→St+1→St+2,而在St+2这个时间段时若给定了St+1状态,那么它跟St及以前的状态是没有关系的。
策略:在马尔可夫决策过程中,最终需要求解一个策略,它是行动和状态之间的映射,分为确定性策略和随机性策略:
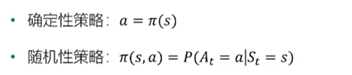
随机性:可能是一个概率取值。
确定性:非左即右。
目标:

多臂Tiger机问题(MAB):探索与利用的权衡
Tiger机有K个摇臂,每个摇臂以一定的概率吐出金币,投入硬币后只能选择其中一个摇臂,目的是通过一定的策略使自己的奖励最大,即得到更多的金币:

强化学习的方法分类

状态价值函数

实际操作更加复杂,策略下进行状态价值函数运算属于理想情况。
状态-行动价值函数

如何学习

此方法属于是抽样办法
Q-Learning

α是学习率
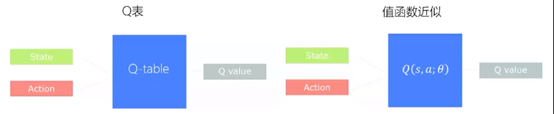
Q表:建立一个表格用来存储状态和行动对应的Q值即Q(s,a),个数与行动不宜太多。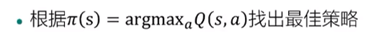
在Q-Learing的基础上提出了新的方法:
深度强化学习DQN
背景:在Q-Learning中,当状态和行动空间是离散且维数不高时,用Q-Table储存每个状态行动对的Q值可以实现行动决策。而当状态和行动空间是高维连续时,使用Q-Table是不现实的。
DQN:在DQN中卷积神经网络的输入为状态s,输出为s下每一个行动a对应的Q值
核心创新:经验回放和目标网络。
在Q-Learning中引入参数学习
Q表本质上是一种映射,把状态映射为行动
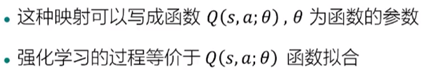
图示如下
基于策略的方法
典型代表是策略梯度算法

优化目标和方法:

Actor-Critic方法

强化学习的应用
新材料发现:通过已进行的实验结果进行训练模型,可以预测下一步用什么材料更好,从而减少实验次数,减少成本。
推荐系统:将推荐系统看作智能体(Agent),用户看作环境(Environment),推荐系统与用户的多轮交互过程可以建模为MDP,经过多轮交互之后,推荐系统学习到用户的习惯和偏好。
出租车派单:

智能交通:
图像修复
设计多种(12种)图像修复工具,DQN比现有图像修复模型复杂度低,修复能力更优异。
工具的选择视为马尔可夫决策过程(MDP)

机器学习/数据科学的知识体系
数学方面:微积分,概率论,优化方法,统计学
计算机方面:python,数据结构与算法,数据库
数据方面:数据采集,数据管理,数据清洗,数据可视化,分布平台(Hadoop,Spark,Flink)
行业认识:对涉及的领域要有一定的理解,并将其他知识融入进去
学习方法建议(初学者,重点)
