今日把运行环境完善了一些,hadoop分布式还没有做,之后就去学习tensorflow了。
我下载的tensorflow版本是2.3.0,老师下发的视频演示的是1.0版本的,因此在写代码时要注意方法的调用,我查了一些资料得知2.0版本的tensorflow较于1.0版本改了很多东西,因此在使用1.0版本的方法时需要写下如下代码:
import tensorflow as tf #此行代码不加会报TypeError错误,原因为已安装的tensorflow版本为2.3,下列实验代码对应的版本为1.几版本 tf.compat.v1.disable_eager_execution()
补上这个代码之后,后续的代码在使用方法时都需要补上【compat.v1.】如tf.Session()在1.0版本可用,而2.0版本已经没有这个方法了,因此在使用时应该这么写
tf.compat.v1.Session()
搞清楚版本差别之后,今日跟着视频学习了使用tensorflow实现简单的线性回归模型构造,下面给出代码和实现效果:
import numpy as np import tensorflow as tf import matplotlib.pyplot as plt #随机生成1000点,围绕直线:y=0.1x+0.3 tf.compat.v1.disable_eager_execution() num_points=1000 vectors_set=[] for i in range(num_points): x1=np.random.normal(0.0, 0.55) y1=x1*0.1+0.3+np.random.normal(0.0, 0.03) vectors_set.append([x1, y1]) #生成样本 x_data = [v[0] for v in vectors_set] y_data = [v[1] for v in vectors_set] plt.scatter(x_data,y_data,c='r')
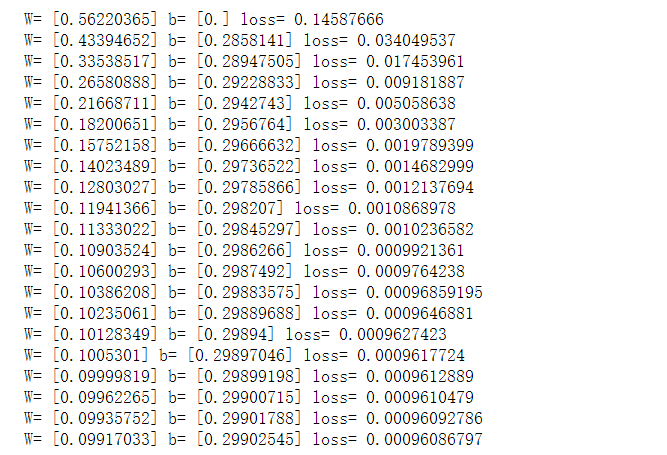
#生成1维的W矩阵,取值是[-1,1]之间的随机数 W=tf.Variable(tf.compat.v1.random_uniform([1], -1.0, 1.0), name='W') #生成1维的b矩阵,初始值是0 b=tf.Variable(tf.zeros([1]), name='b') #经过计算得出预估值y y = W*x_data+b #以预估值y和实际值y_data之间的均方误差作为损失 loss=tf.reduce_mean(tf.square(y - y_data), name='loss') #采用梯度下降法来优化参数 optimizer = tf.compat.v1.train.GradientDescentOptimizer(0.5) #训练的过程就是最小化这个误差值 train=optimizer.minimize(loss, name='train') sess=tf.compat.v1.Session() init=tf.compat.v1.global_variables_initializer() sess.run(init) #输出初始化的W,b print("W=", sess.run(W),"b=",sess.run(b),"loss=",sess.run(loss)) #执行20次训练 for step in range(20): sess.run(train) print("W=", sess.run(W),"b=",sess.run(b),"loss=",sess.run(loss))
plt.scatter(x_data,y_data,c='r') plt.plot(x_data,sess.run(W)*x_data+sess.run(b)) plt.show()
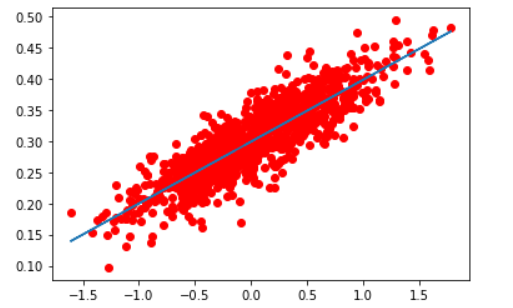
可见训练出来的W和b越来越接近0.1和0.3。
在学习tensorflow的过程中,有些函数的使用与numpy类似,因此比较容易理解,后续需要训练更复杂的模型,因此需要一定的数学基础。
此外今日还看了一些Spark的概念,由于它可以在Hadoop文件系统中并行运行,由于分布式hadoop未能完全搭建,因此没有进行实践。
最后就是今天的一些疑难点,与tensorflow和spark无关,主要是在安装idea的时候出现了问题,总是出错,前前后后尝试了7-8次,最后成功安装了2019.3.3版本,同时将maven库路径之类的调整了一下,大部分时间也都浪费在了这里。
明日目标:hadoop分布式搭建,Spark安装并实践,tensorflow学习。