课程:《密码与安全新技术》
班级: 1792
姓名: 李鹏举
学号:20179203
上课教师:谢四江
上课日期:2018年5月24日
必修/选修: 必修
一、课堂内容总结
这节课是由赵旭营老师为我们讲解的关于模式识别方面的知识。
1.1 模式识别的概念
1.1.1 模式识别是什么?
两个常见的例子:
幼儿认动物
图书归类
用各种数学方法让计算机(软件与硬件)来实现人的模式识别能力,即用计算机实现人对各种事物或现象的分析、描述、判断、识别。
1.1.2 模式识别具体解释
- 模式或者模式类:
可以是研究对象的组成成分或影响因素之间存在的规律性关系,因素之间存在确定性或随机性规律的对象、过程或者事件的集合 - 识别:
对以前见过的对象的再认识(Re-cognition) - 模式识别:
对模式的区分与认识,将待识别的对象根据其特征归并到若干类别中某一类
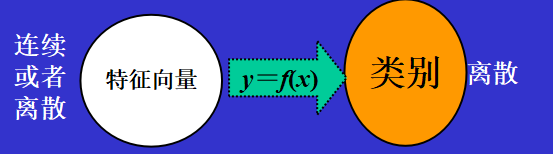
1.2 模式识别主要方法
1.2.1 根据问题的描述方式
- 1)基于知识的模式识别方法:以专家系统为代表,根据人们已知的(从专家那里收集整理得到的)知识,整理出若干描述特征与类别间关系的准则,建立一定的计算机推理系统,再对未知样本决策其类别。
- 2)基于数据的模式识别方法:制定描述研究对象的描述特征,收集一定数量的已知样本作为训练集训练一个模式识别机器,再对未知样本预测其类别(主要研究内容)
1.2.2 根据问题的划分
- 1)监督模式识别:先有一批已知样本作为训练集设计分类器,再判断新的样本类别(分类)
- 2)非监督模式识别:只有一批样本,根据样本之间的相似性直接将样本集划分成若干类别(聚类)
1.2.3 根据理论基础的划分
- 1)统计模式识别:概率论与数理统计
- 2)模糊模式识别:模糊逻辑
- 3)人工神经网络:神经科学、最优化、概率论与数理统计
- 4)结构模式识别:形式语言
1.2.4 根据应用领域的划分
- 1)图像识别
- 2)文字识别
- 3)人脸识别
- 4)指纹识别
- 5)虹膜识别
- 6)掌纹识别
- 7)语音识别
1.3 模式识别系统
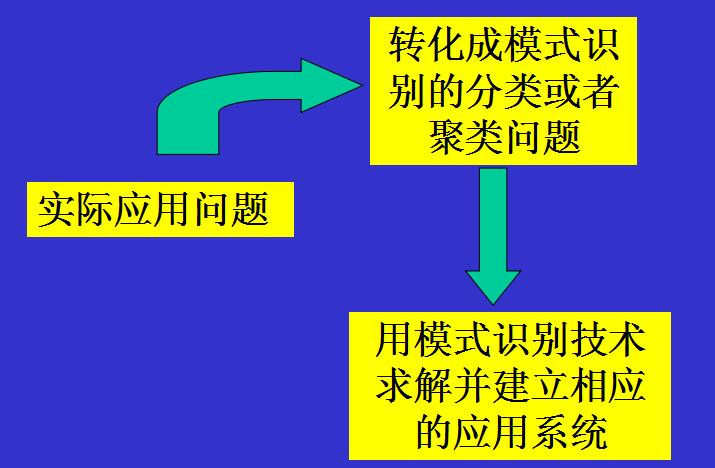
模式识别系统的四个主要组成部分:
- 1.原始数据获取与预处理
- 2.特征提取和选择
- 3.分类或者聚类
- 4.后处理
1.4 线性分类器
- 1.Fisher准则(线性判别)
- 2.感知器学习算法(Perceptron Learning Algorithm )
- 3.Fisher线性判别分析(1936)的基本思想:
通过寻找一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,并且要求变换后的一维数据具有性质:同类样本尽可能聚集在一起,不同类样本尽可能地远
算法的步骤:
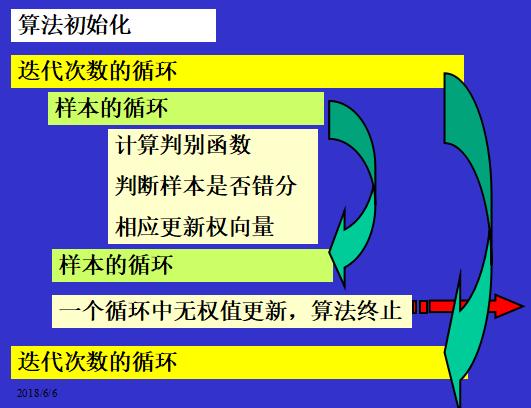
- 4.感知器收敛定理
如果训练样本集是线性可分的,则,从任意的初始权向量出发,总可以在有限步迭代内找到一个权向量,使所有的样本正确分类
1.5 非线性分类器
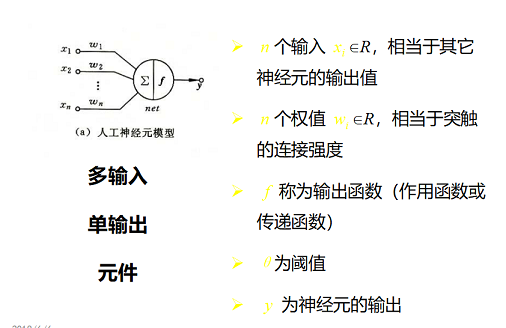
- 1.神经网络:
生物神经元结构
胞体:是神经细胞的本体,内有细胞核和细胞质,完成普通细胞的生存功能
树突:具有多达 103 数量级个的分枝,其长度较短,通常不超过一毫米,用以接受来自其他神经元的信号(输入端)
轴突:用以输出信号,轴突远端有分枝,可与多个神经元连接(输出端)
突触:轴突的末端与树突进行信号传递的界面(两个神经元的接口)
二、学习后思考与总结
2.1 贝叶斯决策理论
为了最小化总风险,对所有的i=1,...,a计算条件风险R(ai|x),并选择行为ai使R(ai|x)最小化。最小化后的总风险值称为贝叶斯风险,记为R*,它是可获得的最优风险。那么,为什么贝叶斯决策规则所得出的风险是最小的呢?
假设判决规则为函数a(x),它用来说明对于特征值x应采取哪种行为(即,a1,...,aa中选择哪个行为)。如果有一种规则,使得损失函数R(ai|x)对每个特征值x都尽可能的小,那么对所有可能出现的特征值x,总风险将会降到最小。
而这一理想的规则就是贝叶斯决策:
“对所有的i=1,...,a计算条件风险R(ai|x),并选择行为ai使R(ai|x)最小化”
通俗的说,就是对特征值x,计算所有行为所导致的损失们(即把R(a1|x),...,R(aa|x)都算出来),然后从中选择损失最小的一个ak作为结果,这样对于每个样本,都可以做的损失最小。假设有一批样本,其中的每一个都做到损失最小的话,对这一批样本而言,总体的损失就是最小的了。
为什么突然对这个理论感兴趣最主要的原因就是,贝叶斯决策理论是最小风险的理论,所以对于贝叶斯决策理论最先想到的就是无人驾驶,这个行为模式是极其需要将风险降到最低的,想起前一段时间看到的一篇文章,国内的无人驾驶程序进行实地无人驾驶,导致80%的事故率,50%的致死率;而谷歌的无人驾驶仅仅只有5.6%的事故率,1.2%的致死率,由此可以看出我们在这方面的缺陷有多么的严重。
2.2 模式识别的重要
举个例子,我们过去如何去评判一个人?你是列举大量事实然后进行条理归纳派?还是简单对号入座派?比如有的人是依赖星座模型,有的人用的是恰当的模式,而且经历了快速思考看起来没有花时间思考一样?
如果你认识一个人,把交往细节一条条分析下来,你会出现信息爆炸,如果不是很熟,这样维护关系大脑很累,注意力很容易陷入不重要的细节。
而我会简单记住一个人的特质——比如某人是中年女却有一颗少女心,性格表面很温柔但内在控制欲极强。这种女人双面性格,长处相处会很矛盾纠结。我不会记忆太多信息,只需要记住这些特征关键词,我就大概知道如何和别人相处刚刚好。
这样我就可以依据我的女性识别模式,得出不同的行动判断,然后在沟通交往中会观察这个模型的有效性,如果是好模型,我就会反复强化和迭代,直到遇到超出我理解的人。
这就是模式识别,也可以看出模式识别对于各领域的记录与运算的重要性。
2.3 模式识别常见算法
2.3.1 K-Nearest Neighbor
简单来说,K-NN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。一个比较好的介绍k-NN的课件可以见下面链接,图文并茂,我当时一看就懂了
http://courses.cs.tamu.edu/rgutier/cs790_w02/l8.pdf
实际上K-NN本身的运算量是相当大的,因为数据的维数往往不止2维,而且训练数据库越大,所求的样本间距离就越多。就拿我们course project的人脸检测来说,输入向量的维数是1024维(32x32的图,当然我觉得这种方法比较silly),训练数据有上千个,所以每次求距离(这里用的是欧式距离,就是我们最常用的平方和开根号求距法) 这样每个点的归类都要花上上百万次的计算。所以现在比较常用的一种方法就是kd-tree。也就是把整个输入空间划分成很多很多小子区域,然后根据临近的原则把它们组织为树形结构。然后搜索最近K个点的时候就不用全盘比较而只要比较临近几个子区域的训练数据就行了。
2.3.2 Linear Discriminant Analysis
LDA,基本和PCA是一对双生子,它们之间的区别就是PCA是一种unsupervised的映射方法而LDA是一种supervised映射方法,这一点可以从下图中一个2D的例子简单看出

图的左边是PCA,它所作的只是将整组数据整体映射到最方便表示这组数据的坐标轴上,映射时没有利用任何数据内部的分类信息。因此,虽然做了PCA后,整组数据在表示上更加方便(降低了维数并将信息损失降到最低),但在分类上也许会变得更加困难;图的右边是LDA,可以明显看出,在增加了分类信息之后,两组输入映射到了另外一个坐标轴上,有了这样一个映射,两组数据之间的就变得更易区分了(在低维上就可以区分,减少了很大的运算量)。