20162327WJH第一次实验——线性结构
实 验 报 告
实 验 报 告
课程:程序设计与数据结构
班级: 1623
姓名: 王旌含
学号:20162327
成绩:
指导教师:娄嘉鹏 王志强
实验日期:10月7日
实验密级: 非密级
预习程度: 已预习
实验时间:15:25-17:15
必修/选修: 必修
实验序号: cs_23
实验内容
实验一
1、实验内容
- 完成链树LinkedBinaryTree的实现(getRight,contains,toString,preorder,postorder)
2、实验过程
- 方法的补全
LinkedBinaryTree方法补全
public LinkedBinaryTree<T> getRight() throws Exception {
if (root == null)
throw new Exception ("Get Right operation "
+ "failed. The tree is empty.");
LinkedBinaryTree<T> result = new LinkedBinaryTree<T>();
result.root = root.getRight();
return result;
}
public boolean contains (T target) throws Exception {
BTNode<T> node = null;
boolean result = true;
if (root != null)
node = root.find(target);
if(node == null)
result = false;
return result;
}
public boolean isEmpty() {
return (root.count()==0);
}
public String toString() {
ArrayIterator<T> list = (ArrayIterator<T>) inorder();
String result = "<top of Tree>
";
for(T i : list){
result += i + " ";
}
return result + "<bottom of Tree>";
}
public Iterator<T> preorder() {
ArrayIterator<T> list = new ArrayIterator<>();
if(root!=null)
root.preorder(list);
return list;
}
public Iterator<T> postorder() {
ArrayIterator<T> list = new ArrayIterator<>();
if(root!=null)
root.postorder(list);
return list;
}
BTNode类的方法补全:
public void inorder ( ArrayIterator<T> iter)
{
if (left != null)
left.inorder (iter);
iter.add (element);
if (right != null)
right.inorder (iter);
}
public void preorder ( ArrayIterator<T> iter) {
iter.add(element);
if(left!=null)
left.preorder(iter);
if (right != null)
right.preorder(iter);
}
public void postorder ( ArrayIterator<T> iter) {
if(left != null)
left.postorder(iter);
if(right != null)
right.postorder(iter);
iter.add(element);
}
- 测试代码测试截图
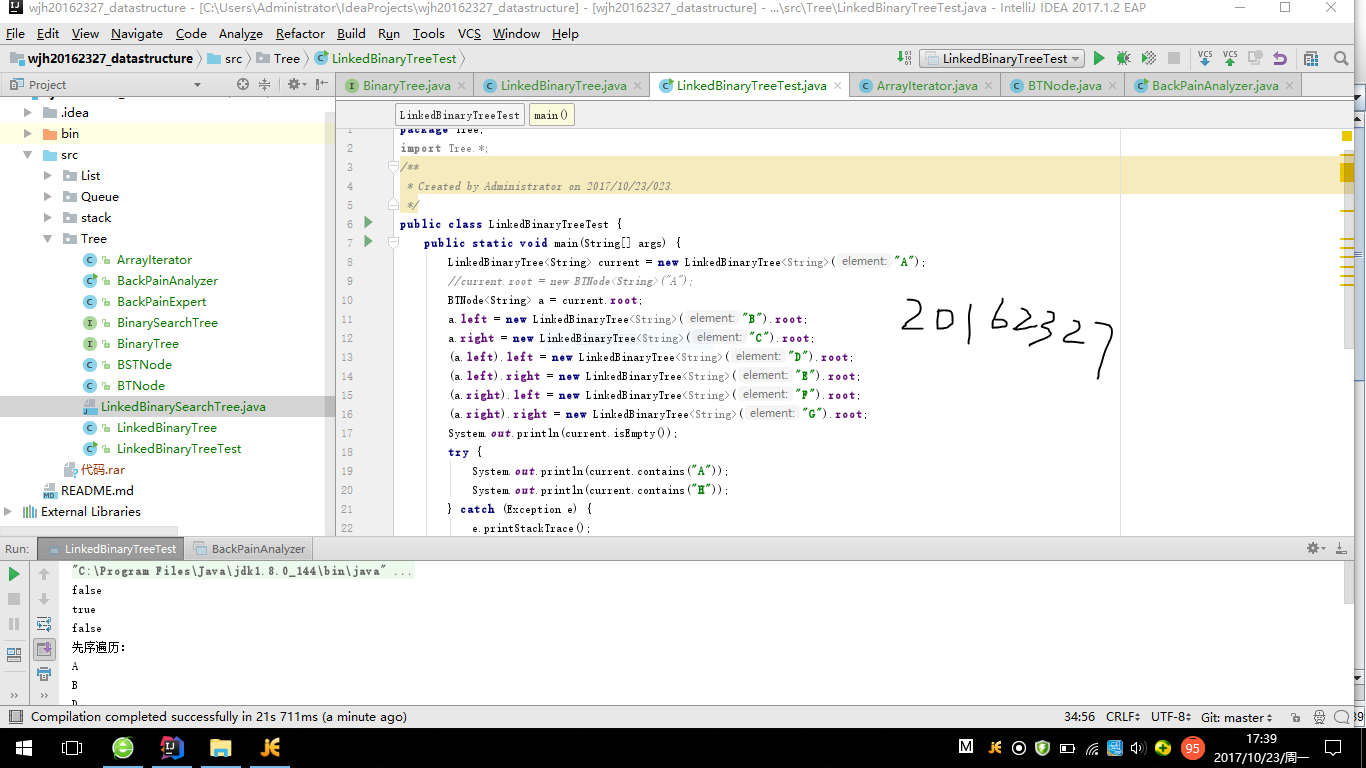
3、实验分析
- getRight()方法根据书上的getLeft()方法可以写出,contains方法是调用BTNode类中的find()方法,用于寻找确定的目标;preorder() 方法和postorder() 方法可以根据inordor()方法写出,结构都是一样的,只是遍历的顺序不一样,即 iter.add(element);所处的位置不一样; isEmpty()方法和toString()方法类似于栈的有关方法,即令size=0并且根据遍历的方法字符化元素。
实验二
1、实验内容
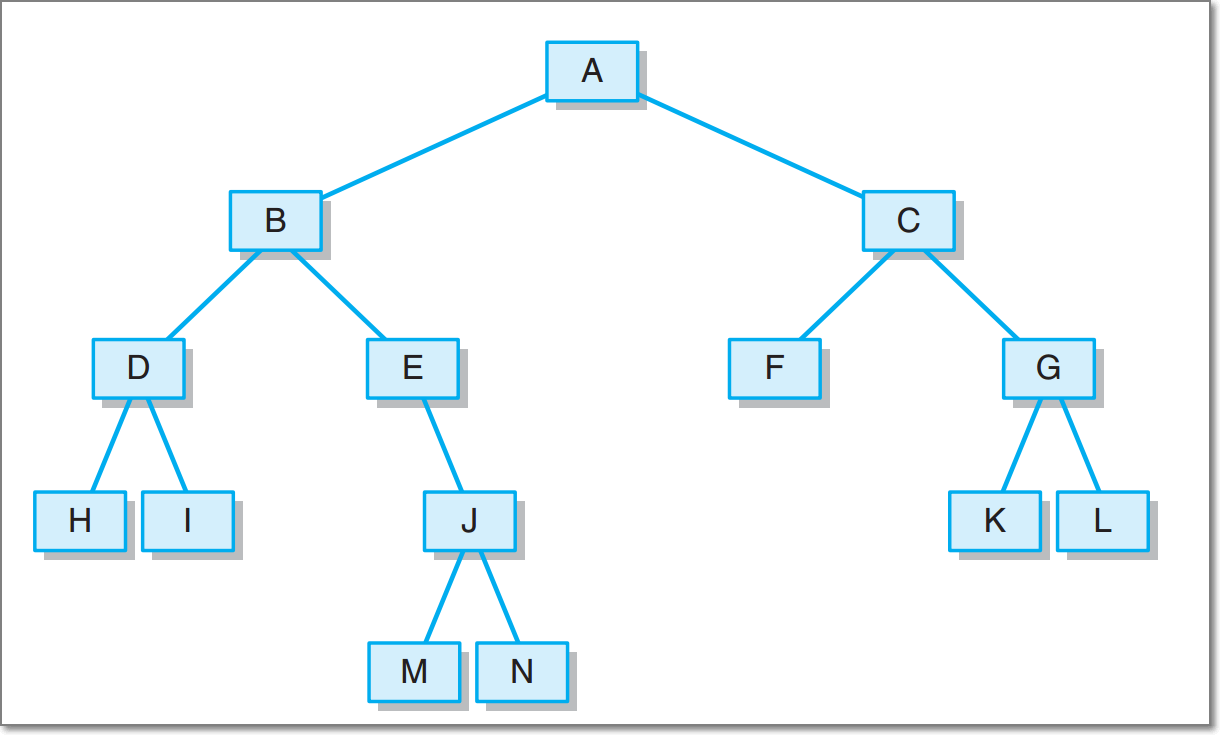
- 基于LinkedBinaryTree,实现基于(中序,先序)序列构造唯一一棵二㕚树的功能,比如教材P372,给出HDIBEMJNAFCKGL和ABDHIEJMNCFGKL,构造出附图中的树
2、实验过程
- 测试截图
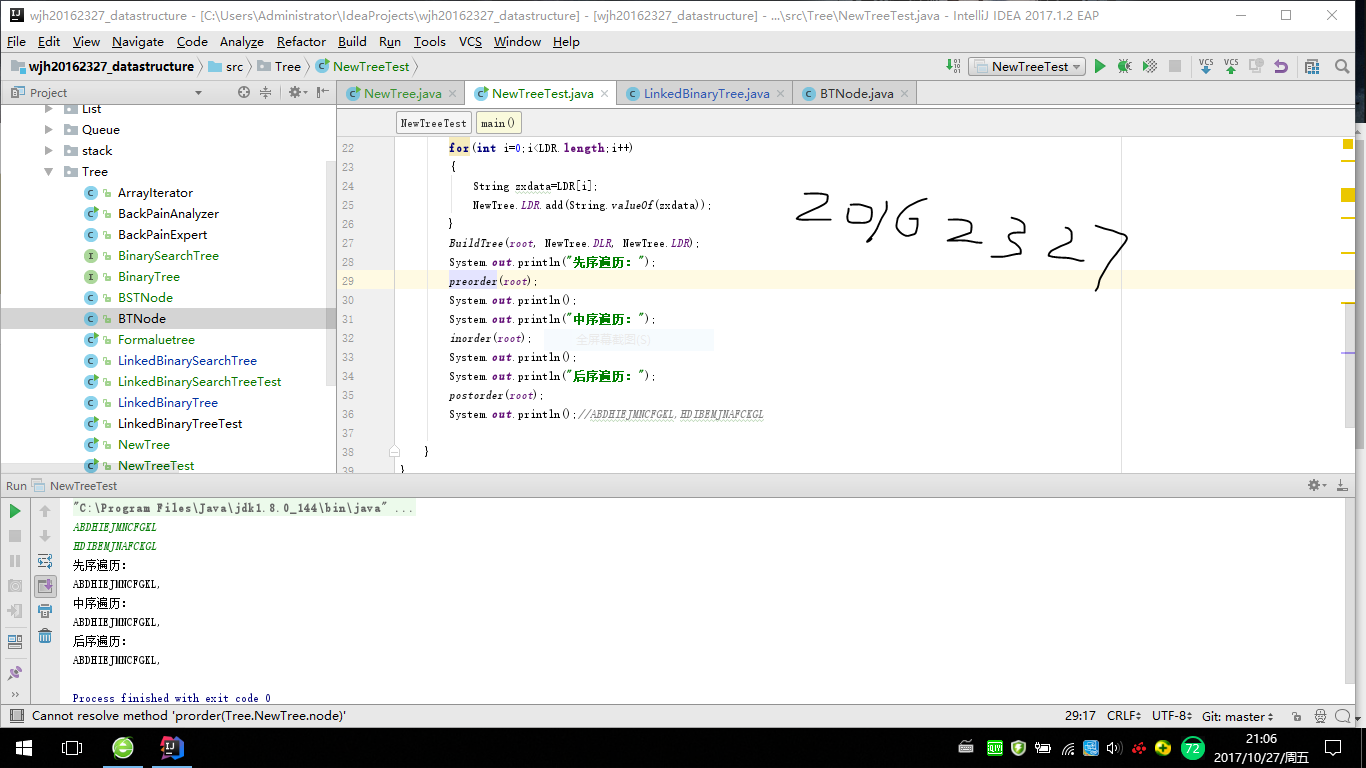
3、实验分析
实验三
1、实验内容
- 完成PP16.6,构造一棵决策树
2、实验过程
- 测试截图
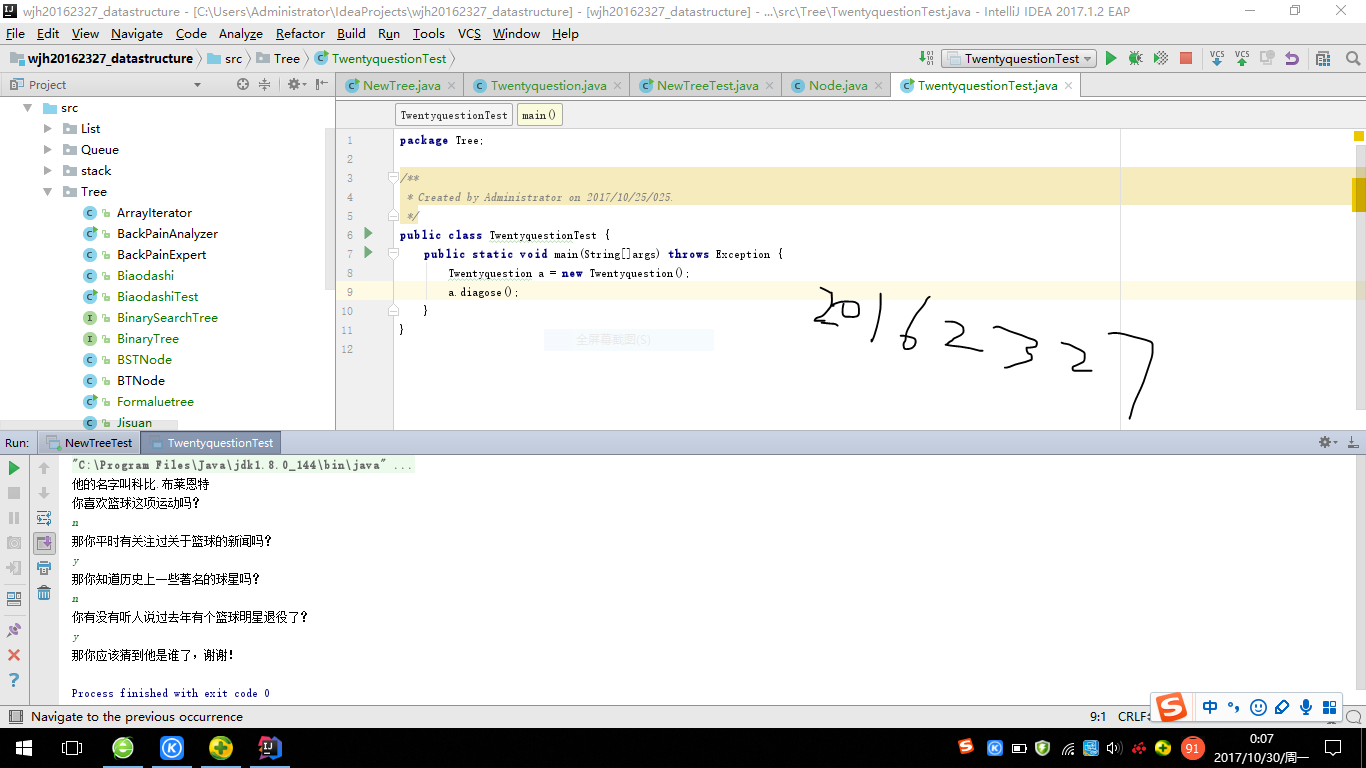
- 先设计好自己的问题用String 1,2,3等表示出来,根据决策树的特点,左子结点表示的答案全部为否,右子结点表示的答案全部为是。然后根据LinkedBinaryTree的两种构造方法将这些问题按照二叉树的结构连接起来,diagnose()方法使用变量current表示正在处理的树中的当前节点,从根开始处理。执行while循环直至遇到右结点。
实验四
1、实验内容
- 完成PP16.8,用树构建表达式树
2、实验过程
3、实验分析
实验五
- 完成PP17.1完成LinkedBinarySearchTree类的实现,特别实现findMin和findMax
2、实验过程
- LinkedBinarySearchTree类的findMin和findMax方法
public T findMin() {
BTNode<T> node = root;
while (node.getLeft() != null)
node = node.getLeft();
T Element = node.getElement();
return Element;
}
public T findMax() {
BTNode<T> node = root;
while (node.getRight() != null)
node = node.getRight();
T Element = node.getElement();
return Element;
}
- 测试截图
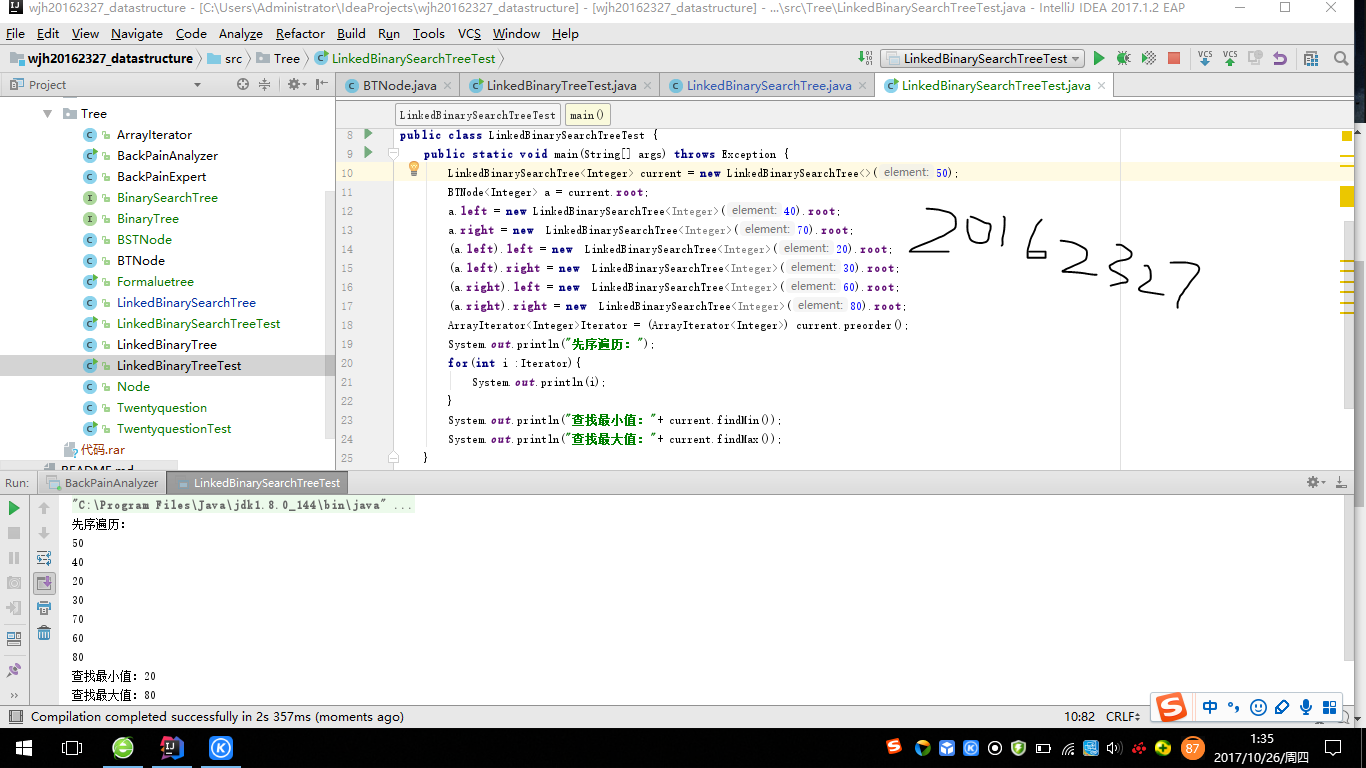
3、实验分析
- 根据二叉查找树的特点,对于每个结点,结点的左子树中包括的元素都小于结点中的元素,结点的的右子树中包含的元素都大于结点中的元素。所以一个二叉查找树的最大值就是所有结点中最右边的叶子结点,反之,最小值就是所有结点中最左边的叶子结点。
实验六
1、实验内容
- 对Java中的红黑树(TreeMap,HashMap)进行源码分析
2、分析
TreeMap类
①、红黑树的本质:
Ⅰ. 红黑树本质上是一个二叉查找树(BST),但是它从根到最远叶子的长度不会超过到最近叶子长度的两倍,因此是近似平衡的。
Ⅱ. 红黑树的节点不是黑的就是红的,不会有第三种颜色。
Ⅲ. 树根必须是黑色。
Ⅳ. 叶子所指的空节点必须是黑色。
Ⅴ. 如果某个节点是红色,那么它的两个儿子必须都是黑色。
Ⅵ. 从任意节点出发的所有向下的路径上包含相同个数的黑节点。这个个数我们称为黑高度Bh。
②、 TreeMap:从API文档中查到:基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap的几个重要特点:
Ⅰ.TreeMap内部是使用红黑树结构存储的。
Ⅱ. 一个对象想要成为TreeMap中的key,那么该对象所属的类必须实现Comparable接口,否则抛异常,因为key的寻找是依赖于比较器的实现。
Ⅲ.TreeMap中允许null值作为value,但是不允许null成为key。
TreeMap中于红黑树相关的主要函数有:
红黑树的节点颜色--红色
private static final boolean RED = false;
红黑树的节点颜色--黑色
private static final boolean BLACK = true;
红黑树的节点”对应的类。
static final class Entry<K,V> implements Map.Entry<K,V> { ... }
Entry包含了6个部分内容:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)
Entry节点根据key进行排序,Entry节点包含的内容为value。
private void rotateLeft(Entry<K,V> p) { ... }//左旋
private void rotateRight(Entry<K,V> p) { ... }//右旋
public V put(K key, V value) { ... }//插入操作
红黑树执行插入操作之后,要执行“插入修正操作”。
目的是:保红黑树在进行插入节点之后,仍然是一颗红黑树
private void fixAfterInsertion(Entry<K,V> x) { ... }//插入修正操作
private void deleteEntry(Entry<K,V> p) { ... }//删除操作
红黑树执行删除之后,要执行“删除修正操作”。
目的是保证:红黑树删除节点之后,仍然是一颗红黑树//删除修正操作
private void fixAfterDeletion(Entry<K,V> x) { ... }//删除修正操作
HashMap类
①.HashMap类的TreeNode结点
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
}
其中包括红黑树节点,有父亲、左右孩子、前一个元素的节点,还有个颜色值。
②.另外由于它继承自 LinkedHashMap.Entry ,而 LinkedHashMap.Entry 继承自 HashMap.Node ,因此还有额外的 6 个属性:
//继承 LinkedHashMap.Entry 的
Entry<K,V> before, after;
//HashMap.Node 的
final int hash;
final K key;
V value;
Node<K,V> next;
HashMap 中有三个关于红黑树的关键参数:
TREEIFY_THRESHOLD
UNTREEIFY_THRESHOLD
MIN_TREEIFY_CAPACITY
//一个桶的树化阈值
//当桶中元素个数超过这个值时,需要使用红黑树节点替换链表节点
//这个值必须为 8,要不然频繁转换效率也不高
static final int TREEIFY_THRESHOLD = 8;
//一个树的链表还原阈值
//当扩容时,桶中元素个数小于这个值,就会把树形的桶元素 还原(切分)为链表结构
//这个值应该比上面那个小,至少为 6,避免频繁转换
static final int UNTREEIFY_THRESHOLD = 6;
//哈希表的最小树形化容量
//当哈希表中的容量大于这个值时,表中的桶才能进行树形化
//否则桶内元素太多时会扩容,而不是树形化
//为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;