经验误差与过拟合
错误率:分类错误的样本数占总样本数的比例。(测试样本)
精度:1-错误率
训练误差(经验误差):学习模型在训练数据上的误差。
泛化误差:学习模型在新样本上的误差。
过拟合:学习模型将训练数据学习的太好,将训练样本的某些特征视为样本共有特征,导致泛化性能下降。(将没有锯齿的树叶识别为不是树叶)
欠拟合:学习样本特征不足。(将一棵树识别为树叶)
评估方法
留出法:直接将数据集划分为两个互斥的集合,一个用于训练,一个用于测试。将测试误差看做泛化误差。两个集合的类别比例差别不应太大,否则影响误差。使用留出法时,一般采用若干次随机划分,重复试验后,取平均值作为评价结果。通常2/3 - 4/5 的样本用于训练,剩余样本用于测试。
交叉验证法:将数据集划分成k个子集,每个子集的样本分类比例应大致相同。每次使用(k-1)个子集进行训练,剩余的子集进行测试,进行k次试验,最终取k个测试的结果的均值为评估结果。通常随机划分数据集为k份,重复p次,称为p次k折交叉验证。最终取p次的均值。
自助法:直接以自助采样法为基础,数据集D有m个样本,在D中随机抽取一个样本,放入E中,进行m次,将E作为训练样本,将D-E作为测试样本(未在E中出现的部分样本),一般当数据集较大时,只采用留出法和交叉验证法。
性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需要衡量模型泛化能力的评价标准,这就是性能度量。
回归任务常用的性能度量:均方误差
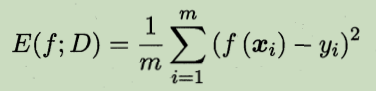
通常还需要查准率和查全率,两者关系成反相关。

查准率 = TP / ( TP + FP )
查全率 = TP / ( TP + FN )