centos7安装spark(伪分布式)
spark是由scala语言开发的,首先需要安装scala.
Scala安装
下载scala-2.11.8,(与spark版本要对应)
命令:wget https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
解压到文件夹并配置环境变量
vim /etc/profile
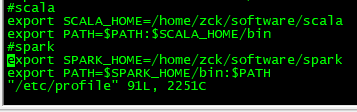
#scala
export SCALA_HOME=/home/zck/software/scala
export PATH=$PATH:$SCALA_HOME/bin
使配置文件生效

测试:scala -version

配置伪分布式spark;
解压到文件夹并配置环境变量
vim /etc/profile
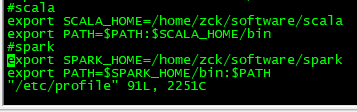
末尾添加以下内容
#spark
export SPARK_HOME=/home/zck/software/spark
export PATH=$SPARK_HOME/bin:$PATH测试
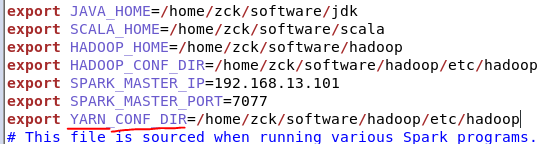
修改配置文件spark/conf/spark-env.sh
加入内容
export JAVA_HOME=/home/zck/software/jdk
export SCALA_HOME=/home/zck/software/scala
export HADOOP_HOME=/home/zck/software/hadoop
export HADOOP_CONF_DIR=/home/zck/software/hadoop/etc/hadoop
export SPARK_MASTER_IP=192.168.13.101
export SPARK_MASTER_PORT=7077
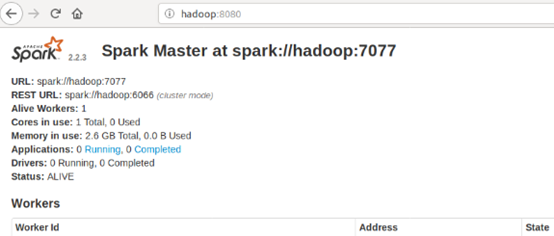
启动spark服务
进入spark文件夹,sbin/start-all.sh

然后再去浏览器看看
Spark yarn模式配置
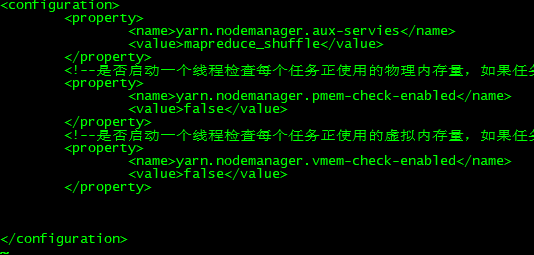
1、修改hadoop配置文件yarn-site.xml,添加如下内容:
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
2、修改spark-env.sh,添加如下配置:
export YARN_CONF_DIR=/opt/module/hadoop-2.7.2/etc/hadoop
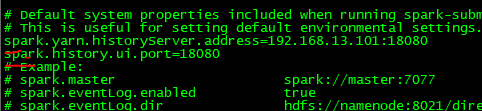
3、日志配置
修改配置文件spark-defaults.conf
添加如下内容:
spark.yarn.historyServer.address=hadoop102:18080
spark.history.ui.port=18080
4、重启spark历史服务
sbin/stop-history-server.sh
sbin/start-history-server.sh

Spark几种模式对比
|
模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
|
Local |
1 |
无 |
Spark |
|
Standalone |
3 |
Master及Worker |
Spark |
|
Yarn |
1 |
Yarn及HDFS |
Hadoop |