插入排序:适合于序列基本有序的情况
1:直接插入排序:o^2
就是从第一个开始,代排序的数字插入到已经排序好的数列中。
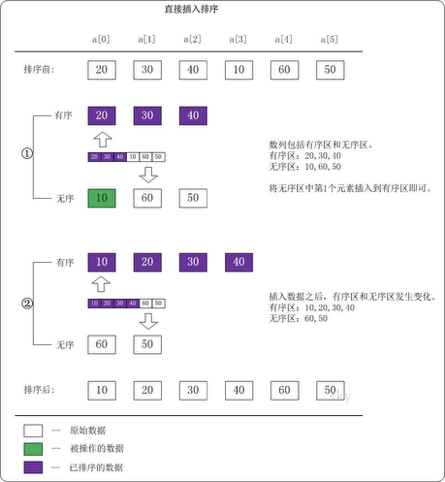
void insertsort(int arr[],int n) { for(int i=1;i<n;i++) { int j=i-1; int temp=arr[i]; while(j>=0&&arr[j]>temp) { arr[j+1]=arr[j]; j--; } arr[j+1]=temp; } }
在之前的直接插入排序加一个优化,本来我们插入的时候我们是从尾向前或者从头向前,也就是相当于找一个适合他的位子,用二分查找,找到他的合适位子。查找的时间复杂度从n变到了nlogn,但是移动的次数没变,时间复杂度仍n^2。
希尔排序本质上是插入排序,而插入适合于序列基本有序的情况。希尔排序就是多次缩小增量;
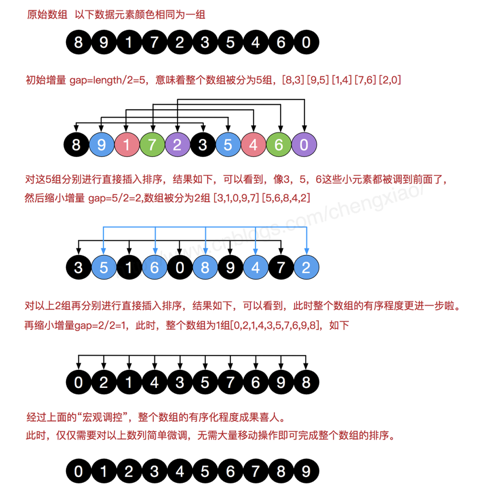
希尔自己:每次讲增量/2并向下取整 n^2;
帕佩尔诺夫和斯塔舍维奇:2^k+1 ……65,33,17,9,5,3,1
n^1.5
交换类排排序
1.冒泡排序:就是像气泡一样浮上来,也就是每一轮出来一个最大之值。每次遍历时,它都会从前往后依次的比较相邻两个数的大小;如果前者比后者大,则交换它们的位置
void bubblesort(int arr[],int n) { for(int i=n-1;i>0;i--) { int flag=0; for(int j=0;j<i;j++)//i后面已经有序了 { if(arr[j]>arr[j+1]) { int temp=arr[j]; arr[j]=arr[j+1]; arr[j+1]=temp; flag=1; } } if(flag==0)//说明已经有序了 return; } }
2,快速排序:越无序效率越高,越有序效率越低
思路分析:快速排序采用双向查找的策略,每一趟选择当前所有子序列中的一个关键字作为枢纽轴,将子序列中比枢纽轴小的前移,比枢纽轴大的后移,当本趟所有子序列都被枢轴按上述规则划分完毕后将会得到新的一组更短的子序列,他们将成为下趟划分的初始序列集。
时间复杂度:最好情况(待排序列接近无序)时间复杂度为O(nlog2n),最坏情况(待排序列接近有序)时间复杂度为O(n2),空间复杂度为O(log2n).
我用自己的语言来描述一下这个算法的过程,首先从第一个数开始(一般),让他做到什么样呢?这个数的左边都比他小,右边都比他大,在左右2边分别的进行快排是不是就解决了。
怎么做到左边比他小,右边比他大,2个指针。一个指向头,一个指向尾。开始遍历,j—-
找到一个比 i所指位子来的小的。那么他是不是错了,我们要求比他小的在左边,他在1右边,那么我们就交换着2个数。
交换完之后,我们发现我们i指的数变成j指的数了。我们要求这个数的左边比他小,右边比他大,这个就要动i指针了。然后发现比他大了就交换要在他右边。之后i又指向了枢纽数,那么又要动j指针了。
这是为了方便理解其实你没必要交换。有一个指针永远指的是枢纽的值,所以直接覆盖就完事。

void quicksort(int arr[],int low,int high) { int i,j; i=low; j=high; int temp=arr[low]; while(i<j)//第一次是j动,i所指 { while(j>i&&arr[j]>=temp) j--; if(i<j) { arr[i]=arr[j]; i++; } while(j>i&&temp>arr[i])//不动的是被覆盖的 { i++; } if(i<j) { arr[j]=arr[i]; j--; } } arr[i]=temp; quicksort(arr,low,i-1); quicksort(arr,i+1,high); }
堆排序: 优先队列就是一个堆排序。之前我写的最短路径的优化也就是在排序的时候用一个堆排序来排,他达到了我们排序的最快速度:nlog2n;
堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。首先简单了解下堆结构。
堆
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。如下图:
我们要一个最从小到大的排序数列:我们就构造一个最大堆,为什么要构造一个最大堆。出来一个最大数房子最后一个叶子结点,然后吧叶子结点调上去,在堆顶点进行修改操作。
堆排序的基本思想是:将待排序序列构造成一个大顶堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个堆,这样会得到n个元素的次小值。如此反复执行,便能得到一个有序序列了
步骤一 构造初始堆。将给定无序序列构造成一个大顶堆(一般升序采用大顶堆,降序采用小顶堆)。
a.假设给定无序序列结构如下
2.此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。
4.找到第二个非叶节点4,由于[4,9,8]中9元素最大,4和9交换。
这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
此时,我们就将一个无需序列构造成了一个大顶堆。
步骤二 将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。
a.将堆顶元素9和末尾元素4进行交换
b.重新调整结构,使其继续满足堆定义
c.再将堆顶元素8与末尾元素5进行交换,得到第二大元素8.
后续过程,继续进行调整,交换,如此反复进行,最终使得整个序列有序
再简单总结下堆排序的基本思路:
a.将无需序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
b.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
c.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
建树的过程是从第一个非叶子结点网上,调整是当前节点到最后一个节点。
void sift(int R[],int low,int high)//low是调整开始位,high表示结束位。
{
int i=low;
int j=2*i+1;
int temp=R[i];
while(j<=high)
{
if(j<high&&R[j]<R[j+1])
j++;
if(R[j]>temp)
{
R[i]=R[j];
i=j;
j=i*2+1;
}
else
break;//排好了
}
R[i]=temp;
}
void headsort(int R[],int n)
//我们从0开始,用数组存。左结点是父亲节点的2倍+1;第一个非叶子结点是n/2向下取整-1
{
for(int i=n/2-1;i>=0;i--)
{
sift(R,i,n-1);
}//建树;
for(int i=n-1;i>0;i--)
{
int temp=R[0];
R[0]=R[i];
R[i]=temp;
sift(R,0,i-1);
}
}
归并:将两个或两个以上的有序表组合成一个新的有序表。
内部排序中,通常采用的是 2-路归并排序。即:将两个位置相邻的记录有序子序列归并为一个记录有序的序列。归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
图解如下
看成是 n 个有序的子序列(长度为 1),然后两两归并。
得到 n/2 个长度为2 或 1 的有序子序列。继续亮亮归并
最后一趟
void merge(int arr[],int low,int mid,int high) { int n1=mid-low+1; int n2=high-mid; int l[n1],r[n2]; for(int i=0;i<n1;i++) { l[i]=arr[low+i]; } for(int j=0;j<n2;j++) { l[j]=arr[mid+j+1]; } int i=0,j=0; int temp=0; while(i<n1&&j<n2) { if(r[j]<l[i]) { arr[temp++]=r[j]; j++; } if(r[j]>=l[i]) { arr[temp++]=l[i]; i++; } } while(i<n1) { arr[temp++]=l[i]; i++; } while(j<n2) { arr[temp++]=r[j]; j++; } } void mergesort(int arr[],int low,int high) { if(low<high) { int mid=(low+high)/2; mergesort(arr,low,mid ); mergesort(arr,mid+1,high); merge(arr,low,mid,high); } }
基数排序
下方的基数排序算法的实现是利用“桶”来实现的,首先我们创建10个桶,然后按照基数入桶,基数的取值是从数字的低位到高位以此取值。我们还是以[62, 88, 58, 47, 62, 35, 73, 51, 99, 37, 93]这个序列为例,使用基数排序的方式对该序列进行升序排列。
下方截图就是上述序列基数排序的具体过程,在排序之前我们先得创建10个空桶,并进行0-9的编号。这10个空桶会在基数排序的过程中存储我们要排序的数值。下方就是对基数排序步骤的详细介绍:
- (1)、以无序序列数值的个数为基数,将无序序列中的值进入到基数对应的桶中。以51为例,如果取个位数为基数的话,51的基数就为1,那么51就进入如编号为1的桶中。以此类推,62在本轮入桶过程中就进入编号为2的桶中。以个位数为基数入桶的结果如下所示。
- (2)、个位数为基数入桶完毕后,在安装编号从小到大将桶中的数据以此取出,在存入我们之前的数组中。如下所示。
- (3)、在第二步生成的数组的基础上再以十位数为基数入桶。入桶完毕后,再次按照桶的编号顺序将数值取出。
- (4)、因为在下方无序的数据中,最大值不超过两位,所以以十位为基数入桶出桶后就已经是有序的了。如果最大值是十万,那么我们一直取基数入桶到十万位为止。也就是排序的数值越大,我们入桶出桶的次数就越多,所以随着位数的增大,排序效率会下降。
复杂度和稳定性
简单选择排序的稳定性是不一定的。插入类的是稳定的,交换类的是不稳定的。插入类是用于链表,交换是数组。
不稳定的:快些选一堆朋友聊天吧。快:快排,些:希尔排序,选:简单选择排序,堆:堆排序。