第三章 程序的机器级表示
第一节 历史观点
Intel处理器系列:俗称x86,开始时是第一代单芯片、16位微处理器之一。
第一代是8086,也是汇编课程中学习的处理器型号。
每个后继处理器的设计都是后向兼容的,可以保证较早版本上编译的代码在较新的处理器上运行。
第二节 程序编码
回顾一下以下代码的含义:
gcc -01 -o p p1.c
- -01 表示使用第一级优化。优化的级别与编译时间和最终产生代码的形式都有关系,一般认为第二级优化-02 是较好的选择。
- -o 表示将p1.c编译后的可执行文件命名为p
GCC将源代码转化为可执行代码的步骤:
C预处理器——扩展源代码-生成.i文件
编译器——产生两个源代码的汇编代码-——生成.s文件
汇编器——将汇编代码转化成二进制目标代码——生成.o文件
链接器——产生可执行代码文件
一、机器级代码
1.机器级编程的两种抽象
(1)指令集结构ISA
是机器级程序的格式和行为,定义了处理器状态、指令的格式,以及每条指令对状态的影响。
(2)机器级程序使用的存储器地址是虚拟地址
看上去是一个非常大的字节数组,实际上是将多个硬件存储器和操作系统软件组合起来。
2.汇编代码的特点:
用可读性更好的文本格式来表示。
3.几个处理器:
- 程序计数器(CS:IP)
- 整数寄存器(AX,BX,CX,DX)
- 条件码寄存器(OF,SF,ZF,AF,PF,CF)
- 浮点寄存器
一条机器指令只执行一个非常基本的操作。
机器代码只是简单地将存储器看成一个很大的、按字节寻址的数组。具体内容参考上学期的汇编课程。
二、代码示例
书第107页的代码如下:
int accum = 0;
int sum(int x, int y)
{
int t = x + y;
accum += t;
return t;
}
这里需要注意的是反汇编器的使用:
objdump -d xxx.xx
即可反汇编-d后的文件,查看目标代码文件的内容。
二进制文件可以用od 命令查看,也可以用gdb的x命令查看。 有些输出内容过多,我们可以使用 more或less命令结合管道查看,也可以使用输出重定向来查看。
od code.o | more
od code.o > code.txt
在读取地址时要注意是不是小端法,小端法的正确读法是与自然方向相反,比如109页第六行中后四个字节18 a0 04 08的正确顺序其实是08 04 a0 18,去掉最高位的0后即为0x804a018。
机器代码和它的反汇编表示的一些特性:
- IA32指令长度从1到15个字节不等
- 设计指令格式的方式是,从某个给定位置开始,可以将字节唯一的解码成机器指令
- 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码,不需要访问程序的源代码或汇编代码
- 反汇编器使用的指令命名规则与GCC生成的汇编代码使用的有些差别
ATT和INTEL的汇编代码格式有所差别。
第三节 数据格式
1.Intel中:
8 位:字节
16位:字
32位:双字
64位:四字
2.c语言基本数据类型对应的IA32表示
char 字节 1字节
short 字 2字节
int 双字 4字节
long int 双字 4字节
long long int (不支持) 4字节
char * 双字 4字节
float 单精度 4字节
double 双精度 8字节
long double 扩展精度 10/12字节
3.数据传送指令的三个变种:
- movb 传送字节
- movw 传送字
- movl 传送双字
第四节 访问信息
Linux——平坦寻址方式:
ds,ss,cs等各段的段基地址都指向同一个地方,不管是数据段还是代码段,只要他们的偏移相等,那么他们就是寻址一样的物理内存,所以我们就只需指明偏移就能得到统一的寻址目标,不管这个目标是在代码段还是数据段或者堆栈段之中。
一、操作数指示符
操作数:指示出执行一个操作中要引用的源数据值,以及放置结果的目标位置。
1.操作数的三种类型
- 立即数
- 寄存器
- 存储器
2.结果存放的两种可能
- 寄存器中
- 存储器中
3.寻址方式
(1)立即数寻址方式
格式:$后加用标准c表示法表示的整数,如$0xAFF
(2)寄存器寻址方式
如%eax,与汇编中学过的AX寄存器类比。
(3)存储器寻址方式
- 直接寻址方式
- 寄存器间接寻址方式
- 寄存器相对寻址方式
- 基址变址寻址方式
- 相对基址变址寻址方式
二、数据传送指令
1.mov指令
(1)功能
把一个字节(字)操作数从源SRC传送至目的地DST
(2)格式
MOV DST,SRC
(3)操作数
MOV reg/mem, imm ;立即数寄存器或存储器
MOV reg/mem/seg, reg ;寄存器的值寄存器/内存/段寄存器
MOV reg/seg, mem ;内存单元的值寄存器/段寄存器
MOV reg/mem, seg ;段寄存器的值寄存器/内存单元
IA32的限制:两个操作数都不能指向存储器。
(4)变种
- movb 传送字节
- movw 传送字
- movl 传送双字
- movs 符号位扩展
- movz 零扩展
2.push&pop
(1)堆栈
需要注意两点:
1.后进先出
2.栈指针指向栈顶元素
3.栈朝低地址方向增长
(2)压栈push
指令格式——PUSH r16/m16/seg
指令功能
第一步:SP←SP-2 ;堆栈指针SP上移
第二步:(SS):(SP)←r16/m16/seg ;字操作数存入堆栈顶部
注意 堆栈操作必须至少以字为单位,这时栈顶指针-2
如果压入的是双字,栈顶指针-4
(3)出栈pop
指令格式——POP r16/m16/seg
指令功能
第一步:r16/m16/seg← (SS):(SP) ;栈顶的一个字传送到指定的目的操作数
第二步:SP←SP+2 ;堆栈指针SP下移,指向新的栈顶
栈顶指针变化同压栈。
三、数据传送示例
1.c操作符*执行指针的间接引用。
2.c语言中的指针其实就是地址,间接引用指针就是将该指针放在一个寄存器中,然后在存储器引用中使用这个寄存器
3.局部变量通常保存在寄存器中,而不是存储器
第五节 算术和逻辑操作
一、加载有效地址
加载有效地址指令——leal,是movl指令的变形,对比汇编中的LEA指令学习。
指令形式:从存储器读取数据到寄存器。
实际:将有效地址写入到目的操作数,而目的操作数必须是寄存器;并不真实引用存储器。
二、一元操作和二元操作
1.一元操作
只有一个操作数,既是源又是目的,可以是一个寄存器,或者存储器位置。
2.二元操作
源操作数 目的操作数
第一个操作数可以是立即数、寄存器或者存储器位置
第二个操作数可以是寄存器或者存储器位置
但是不能同时是存储器位置。
三、移位操作
SAL 算术左移
SHL 逻辑左移
SAR 算术右移(补符号位)
SHR 逻辑右移(补0)
源操作数:移位量——立即数或CL
目的操作数:要移位的数值——寄存器或存储器
四、特殊操作
1.乘法
(1)乘积截断
imull
双操作数,从两个32位操作数产生一个32位的乘积。
(2)乘积不截断
mull,无符号数乘法
imull,有符号数乘法
都要求一个参数必须在寄存器%eax中,另一个作为指令的源操作数给出。乘积的高32位在%edx中,低32位在%eax中。
2.除法
(1)有符号除法
idivl 操作数
将DX:AX中的64位数作为被除数,操作数中为除数,结果商在AX中,余数在DX中。
(2)无符号除法
divl指令
通常会事先设定寄存器%edx为0.
第六节 控制
一、条件码
CF:进位标志
ZF:零标志
SF:符号标志
OF:溢出标志
条件码的改变:
数据传送指令
MOV 不影响标志位
PUSH POP 不影响标志位
XCHG 交换指令 不影响标志位
XLAT 换码指令 不影响标志位
LEA 有效地址送寄存器指令 不影响标志位
PUSHF 标志进栈指令 不影响标志位
POPF 标志出栈指令 标志位由装入值决定
算术指令
ADD 加法指令 影响标志位
ADC 带进位加法指令 影响标志位
INC 加一指令 不影响CF,影响别的标志位
SUB 减法指令 影响标志位
SBB 带借位减法指令 影响标志位
DEC 减一指令 不影响CF,影响其他标志位
NEG 求补指令 影响标志位 只有操作数为0,例如字运算对-128求补,OF=1,其他时候OF=0
CMP 比较指令 做减法运算但不存储结果,根据结果设置条件标志位
MUL 无符号数乘法指令
IMUL 有符号数乘法指令 均对CF和OF位以外的条件码位无定义(即状态不定)
DIV 无符号数除法指令
IDIV 带符号数除法指令 除法指令对所有条件码位均无定义
位操作指令:
AND 逻辑与
OR 逻辑或
NOT 逻辑非 不影响标志位
XOR 异或
TEST 测试指令 除NOT外的四种,置CF、OF为0,AF无定义,SF,ZF,PF根据运算结果设置
移位指令:
SHL 逻辑左移指令
SHR 逻辑右移指令 移位指令根据结果设置SF,ZF,PF位
ROL 循环左移指令
ROR 循环右移指令 循环移位指令不影响除CF,OF之外的其他条件位
串处理指令:
MOVS 串传送指令
STOS 存入串指令
LODS 从串取指令 均不影响条件位
CMPS 串比较指令
SCAS 串扫描指令 均不保存结果,只根据结果设置条件码
控制转移指令:
JMP 无条件转移指令 不影响条件码
所有条件转移指令 都不影响条件码
循环指令:
不影响条件码
子程序相关:
CALL调用和RET返回 都不影响条件码
以上都是我上学期复习汇编的时候总结的……迁移过来对比学习吧。其实前面这几章基本都在重复上学期汇编的内容。
二、访问条件码
这个指的是SET指令,通过set与不同的条件码的组合,达到不同的跳转条件。具体参见课本第125页。
注意“同义名”的存在。
都适用的情况:执行比较指令,根据计算t=a-b设置条件码。
三、跳转指令及其编码
JUMP指令,同样是汇编中常用的指令,根据不同的条件和符号位进行不同的跳转动作,具体见书128页。
跳转指令有几种不同的编码,最常用的是PC(程序计数器)相关的。
需要注意的是,jump分为直接跳转和间接跳转:
直接跳转:后面跟标号作为跳转目标
间接跳转:*后面跟一个操作数指示符
当执行与PC相关的寻址时,程序计数器的值是跳转指令后面的那条指令的地址,而不是跳转指令本身的地址。
四、翻译条件分支
将条件表达式和语句从c语言翻译成机器语言,最常用的方式就是结合有条件和无条件跳转。
无条件跳转:例如 goto。书上的例子就是把if-else语句翻译成了goto形式,然后再由这个形式翻译成汇编语言。
五、循环
汇编中可以用条件测试和跳转组合起来实现循环的效果,但是大多数汇编器中都要先将其他形式的循环转换成do-while格式。
1.do-while循环
通用形式:
do
body-statement
while(test-expr);
循环体body-statement至少执行一次。
可以翻译成:
loop:
body-statement
t = test-expr;
if(t)
goto loop;
即先执行循环体语句,再执行判断。
2.while循环
通用形式:
while (test-expr)
body-statement
GCC的方法是,使用条件分支,表示省略循环体的第一次执行:
if(!test-expr)
goto done;
do
body-statement
while(test-expr);
done:
接下来:
t = test-expr;
if(!t)
goto done:
loop:
body-statement
t = test-expr;
if(t)
goto loop;
done:
归根究底,还是要把循环改成do-while的样子,然后用goto翻译。
3.for循环
for循环可以轻易的改成while循环,所以再依照上面的方法改成do-while再翻译即可。
六、条件传送指令
这一节主要是书上举得例子,同时看概念的时候要去分清控制的条件转移和数据 的条件转移,前者是条件操作的传统方法,后者是指先计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个。在有限的可行情况下,就可以用过简单的条件传送指令实现后者。
※基于条件数据传送的代码比基于条件控制转移的代码性能好。
七、Switch语句
Switch语句是多重分支的典型,而且使用的是跳转表这种数据类型,是的搜索的更快更高效。
所以这里的关键就是要领会使用跳转表是一种非常有效的实现多重分支的方法。
这里更多的数据定义等书上都有,就不费劲打上来了,145和146页的代码要看懂。
第七节 过程
过程调用:
进入,为过程的局部变量分配空间
将数据(以过程参数和返回值的形式)和控制从代码的一部分传递到另一部分。
退出,释放这些空间。
一、栈帧结构
栈用来传递参数、存储返回信息、保存寄存器,以及本地存储。
1.栈帧
为单个过程分配的那部分栈称为栈帧,通用结构见149页
所以本质上栈帧还是栈。
2.两个指针
最顶端的栈帧以两个指针界定:
寄存器%ebp-帧指针
寄存器%esp-栈指针
栈指针可移动,所以信息访问多相对于帧指针。
3.调用的过程
课本150页过程P调用过程Q的示例。
调用者的帧应该在被调用者的下面,并且调用者返回地址是它的栈帧末尾,这样可以保证被调用者执行完毕全都出栈后,程序能够继续向下执行。
关于被调用者Q用栈的几个用处:
1.保存不能存放在寄存器中的局部变量。
当要对一个局部变量使用地址操作符&的时候,就必须要为它生成一个地址,所以要入栈。这个用法!以前没见过!
2.存放它调用的其他过程的参数。
二、转移控制
这里用到的主要就是CALL和RET这一对指令。
1.call
call指令和转移指令相似,同样分直接和间接,直接调用的目标是标号,间接调用的目标是*后面跟一个操作数指示符,和JMP一样。
CALL指令的效果是将返回地址入栈,并跳转到被调用过程的起始处。返回地址是还在程序中紧跟在call后面的那条指令的地址。
然后就会用到ret了。
2.ret
ret指从栈中弹出地址,并跳转到这个位置。
在上学期的汇编语言学习中,call和ret常被用来进行子函数、子模块的调用。
3.leave
这个指令可以使栈做好返回的准备,等价于:
movl %ebp,%esp
popl %ebp
说到这里,这本书里的汇编语言很多与上学期学的8086有些许的区别,毕竟一直在不断的升级,但原理还是通用的。
三、寄存器使用惯例
程序寄存器组是唯一能被所有过程共享的资源。
这个惯例是为了防止一个过程P调用另一个过程Q时寄存器中的值被覆盖。惯例如下:
%eax,%edx,%ecx 调用者保存寄存器(Q可覆盖,P的数据不会被破坏)
%ebx,%esi,%edi 被调用者保存寄存器(Q在覆盖这些值前必须压入栈并在返回前回复他们)
%ebp,%esp 惯例保持
%eax用来保存返回值
也就是说,当我们想嗷保存一个值以待以后运算可用的时候,有两种选择:
1.由调用者保存。在调用之前就压进栈。
2.由被调用者保存,在刚被调用的时候就压进栈,并在返回之前恢复。
四、查看函数调用栈信息的GDB命令
backtrace/bt n
n是一个正整数,表示只打印栈顶上n层的栈信息。
-n表一个负整数,表示只打印栈底下n层的栈信息。
frame n
n是一个从0开始的整数,是栈中的层编号。比如:frame 0,表示栈顶,frame 1,表示栈的第二层。
这个指令的意思是移动到n指定的栈帧中去,并打印选中的栈的信息。如果没有n,则打印当前帧的信息。
up n
表示向栈的上面移动n层,可以不打n,表示向上移动一层。
down n
表示向栈的下面移动n层,可以不打n,表示向下移动一层。
作业:
如图所示,这是我输入的源代码。
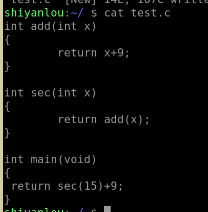
执行了
之后
得到的结果,去掉.开头的句子之后:
add:
pushl %ebp ;将%ebp入栈,为帧指针
movl %esp, %ebp
movl 8(%ebp), %eax
addl $9, %eax
popl %ebp ;%ebp出栈
ret
sec:
pushl %ebp ;将%ebp入栈,为帧指针
movl %esp, %ebp
subl $4, %esp
movl 8(%ebp), %eax
movl %eax, (%esp)
call add ;调用add函数
leave ;为返回准备栈,相当于%ebp出栈
add:
pushl %ebp ;将%ebp入栈,为帧指针
movl %esp, %ebp
movl 8(%ebp), %eax
addl $9, %eax
popl %ebp ;%ebp出栈
ret
sec:
pushl %ebp ;%ebp入栈
这个程序的流程其实是sec的过程调用了add的过程,所以sec先把它的%ebp寄存器压入栈作为帧指针,然后压入被保存的寄存器、本地变量和临时变量,最上面是参数构造区域。然后再用call调用add,这时又把返回地址压入栈。
add被调用后,把它的帧指针%ebp压入栈,然后压入寄存器、本地变量、临时变量,最上面是参数构造区域。
add运算结束前,add会把%ebp弹出栈,然后ret指令弹出并跳转到之前call压入的地址,返回到sec过程,最后因为leave,%ebp出栈。

这次的很多内容都是在上学期的汇编的基础上进行的,讲的更为深入,有些地方理解起来还是有些困难,但是与之前的学习内容对比着学习,相对比较轻松。