前言
redis的pipeline可以一次性发送多个命令去执行,在执行大量命令时,可以减少网络通信次数提高效率。但是很可惜,redis的集群并不支持pipeline语法(只是不提供相应的方法而已)。不过只要稍稍看下jedis的源码,就可以发现虽然没有现成的轮子,但是却很好造。
一、简介
先说下redis集群的简单结构和数据的定位规则(见下图)。redis提供了16384个槽点,并为每个节点分配若干槽位,操作redis数据时会根据key进行hash,然后找到对应的节点进行操作,这也解释了为什么jedisCluster不支持pipeline。因为pipeline中若干个需要操作的key可能位于不同的分片,如果想要获取数据就必须进行一次请求的转发(可能这个词不标准,但是好理解,或者称之为漂移吧),这与pipeline为了减少网络通信次数的本意冲突。那我们只要根据key进行hash运算,然后再根据hash值获取连接,接着按照连接对所有的key进行分组,保证同一pipeline内所有的key都对应一个节点就好了,最后通过pipeline执行。试试吧,万一好使了呢

二、思路
既然知道了原因和流程,我们就试下能不能造轮子吧。首先我们需要hash算法以及根据hash结果获取JedisPool的方法,很不巧的是,jedis都提供了。
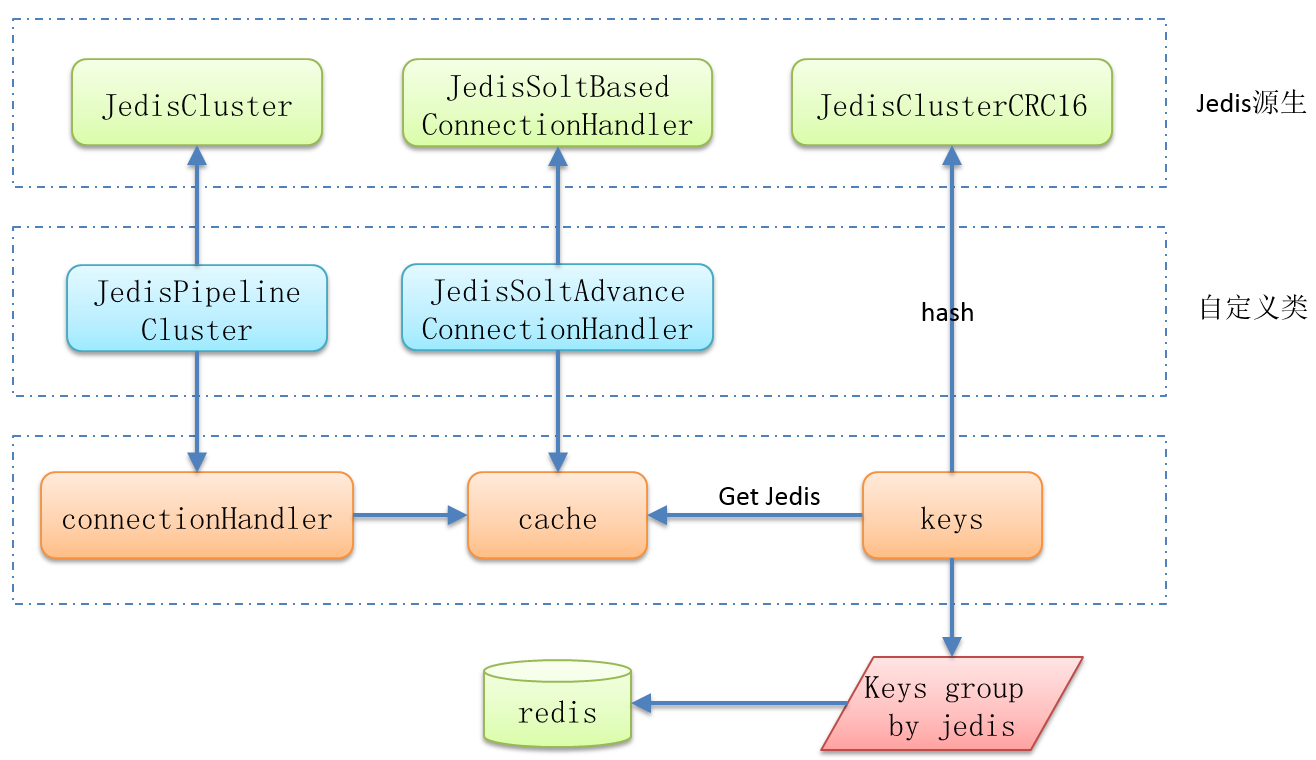
为了实现上面的功能,我们需要一个类和两个属性,类是JedisClusterCRC16(hash算法),两个属性分别是connectionHandler(用于获取cache)和cache(根据hash值获取连接)
有兴趣的同学可以看下JedisCluster的源码,它集成自BinaryJedisCluster,在BinaryJedisCluster有个connectionHandler属性,恰巧它又是protected修饰的,这不分明就是让你继承么。而cache属性在JedisClusterConnectionHandler中,注意这个类是抽象类,轻易的重写会导致整个功能都不能用了(如果内部实现不是很了解,继承往往优于重写,因为可以super嘛),我们发现它有一个实现类JedisSlotBasedConnectionHandler,那我们继承这个类就好了。详细的设计如下图:
三、实现
import lombok.extern.slf4j.Slf4j; import org.apache.commons.pool2.impl.GenericObjectPoolConfig; import redis.clients.jedis.*; import redis.clients.util.JedisClusterCRC16; /** * @author zhangyining on 18/12/1 001. */ @Slf4j public class JedisPipelineCluster extends JedisCluster { static { cluster = init(); } private static JedisPipelineCluster cluster; public static JedisPipelineCluster getCluster(){ return cluster; } private static JedisPipelineCluster init(){ //todo 连接代码省略... return jedisCluster; } public JedisPool getJedisPoolFromSlot(String redisKey) { return getConnectionHandler().getJedisPoolFromSlot(redisKey); } private JedisPipelineCluster(Set<HostAndPort> jedisClusterNode, int timeout, int maxAttempts,final GenericObjectPoolConfig poolConfig){ super(jedisClusterNode, timeout, maxAttempts, poolConfig); //继承可以添加个性化的方法,仔细看构造方法其实和父类是一样的 connectionHandler = new JedisSlotAdvancedConnectionHandler(jedisClusterNode, poolConfig, timeout, timeout); } private JedisSlotAdvancedConnectionHandler getConnectionHandler() { return (JedisSlotAdvancedConnectionHandler)this.connectionHandler; } private class JedisSlotAdvancedConnectionHandler extends JedisSlotBasedConnectionHandler { private JedisSlotAdvancedConnectionHandler(Set<HostAndPort> nodes, GenericObjectPoolConfig poolConfig, int connectionTimeout, int soTimeout) { super(nodes, poolConfig, connectionTimeout, soTimeout); } private JedisPool getJedisPoolFromSlot(String redisKey) { int slot = JedisClusterCRC16.getSlot(redisKey); JedisPool connectionPool = cache.getSlotPool(slot); if (connectionPool != null) { return connectionPool; } else { renewSlotCache(); connectionPool = cache.getSlotPool(slot); if (connectionPool != null) { return connectionPool; } else { throw new RuntimeException("No reachable node in cluster for slot " + slot); } } } } }
四、测试
import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.Pipeline; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; /** * @author zhangyining on 18/12/1 001. */ public class Test { public static void main(String[] args) { JedisPipelineCluster cluster = JedisPipelineCluster.getCluster(); String[] testKeys = {"USER_FEAT_10013425884935", "USER_FEAT_10006864229638", "USER_FEAT_10008005187846"}; Map<JedisPool, List<String>> poolKeys = new HashMap<>(); for (String key : testKeys) { JedisPool jedisPool = cluster.getJedisPoolFromSlot(key); if (poolKeys.keySet().contains(jedisPool)){ List<String> keys = poolKeys.get(jedisPool); keys.add(key); }else { List<String> keys = new ArrayList<>(); keys.add(key); poolKeys.put(jedisPool, keys); } } for (JedisPool jedisPool : poolKeys.keySet()) { Jedis jedis = jedisPool.getResource(); Pipeline pipeline = jedis.pipelined(); List<String> keys = poolKeys.get(jedisPool); keys.forEach(key ->pipeline.get(key)); List result = pipeline.syncAndReturnAll(); System.out.println(result); jedis.close(); } } }
五、总结
之前看到过有人通过反射来获取connectionHandler和cache属性的,个人觉得反射虽然强大,但是明明可以继承却反射,有点怪怪的,看个人习惯吧。总之不管是那种方式,重点是熟悉redis集群是怎么分配数据以及执行请求的,剩下的不过是用不同的地方话(不用方式的代码)说出来而已