在进行网页爬取的过程中很多网站都会有账户密码,信息只对注册的用户开放,所以在爬取过程中必须的模拟浏览器进行登录
就以我今天爬取的药智库为例,如果没有登录,显示的信息会是这样的,会找不到详细信息,

所以在爬取过程中需要用到模拟登录
首先要审查网页的元素,查看他的network

然后进行登录,点击上方的文件,查看抓取到的值,我们主要看的就是Request Headers中的Cookie(包含登录过程中的信息)和他的User-Agent(浏览器的类型)的值
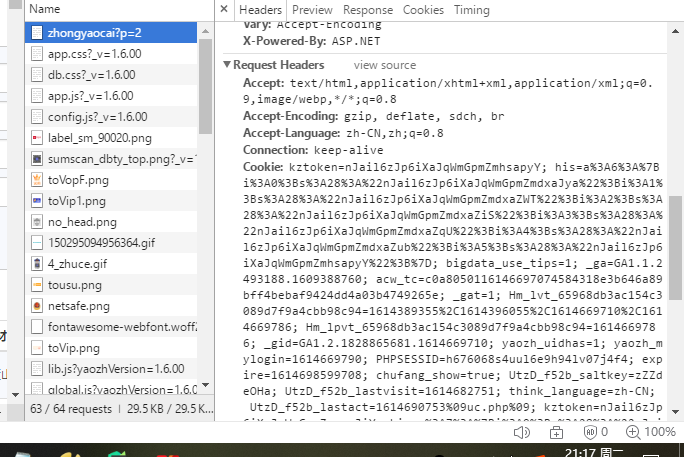
在爬取时使用
headers = { # 假装自己是浏览器
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
# 把你刚刚拿到的Cookie塞进来
'Cookie': 'PHPSESSID=dvd01ugqam4qoi844aon8fg7j1; kztoken=nJail6zJp6iXaJqWmGpmZmhwYZaU; his=a%3A1%3A%7Bi%3A0%3Bs%3A28%3A%22nJail6zJp6iXaJqWmGpmZmhwYZaU%22%3B%7D; _ga=GA1.2.1664791796.1614678034; _gid=GA1.2.858523531.1614678034; _gat=1; yaozh_logintime=1614684892; yaozh_user=1026728%09%E4%B8%80%E5%BE%80%E6%97%A0%E5%89%8Dgy; yaozh_jobstatus=kptta67UcJieW6zKnFSe2JyYnoaSZ5drnJadg26qb21rg66flM6bh5%2BscZJsbIVJGuFJIuEd%2FNVK7fLIrFlwq2uac1OfwqnZw62gzp1Unti26ce8e0B3007e713c7aA67F67A74ee0CckpSeg2ibZpmam5pqb2labNRzZW2Dqs7Rnlmcq2yUmJyDlZqSa5ttmZyelmxralps3g%3D%3D67af241bbc1d71ba798ab73645de5e62; Hm_lvt_65968db3ac154c3089d7f9a4cbb98c94=1614678033,1614684897; Hm_lpvt_65968db3ac154c3089d7f9a4cbb98c94=1614684897', }
session = requests.Session()
response = session.get(url, headers=headers)
response.encoding = 'utf-8'
html = response.text # 将网页内容以html返回
soup = BeautifulSoup(html, 'lxml') # 解析网页的一种方法
这样就可以成功的登录,并爬取相关的值了