数组
数组的定义:
数组是具有固定长度并拥有零个或者多个相同数据类型元素的序列
定义一个数组的方法:
var 变量名[len] type
例子:
var a[5] int //3个整数的数组
var a[5]string //3个字符串的数组
像上面这种定义方法,我们是指定了数组的长度,但是还有如下定义方法:
var a=[...]int{1,2,3}
如果把数组的长度替换为...,那么数组的长度由初始化数组的元素个数决定
数组中的每个元素是通过索引来访问,索引是从0开始
例如 数组var a[5]int 获取第一个元素就是a[0],
获取数组的长度是通过len(a)
这里需要知道:数组的长度也是数组类型的一部分,所以要知道[3]int和[4]int是不同的数组类型
默认情况下一个新数组中的元素初始值为元素类型的零值
如一个证书类型的数组,默认值就是0
初始化数组:
有一下几种方法:
var a = [5] int{1,2,3,4,5}
var a = [5] int{1,2,3}
var a = [...]int{1,2,3,4}
var a = [5]string{1:"go",3:"python"}
关于数组的类型:
值类型
数组的遍历
数组的遍历方法:
var a = [3]int{1, 2, 3}
for i, v := range a {
fmt.Printf("%d %d
", i, v)
}
当然如果不需要索引也可以:
var a = [3]int{1, 2, 3}
for _, v := range a {
fmt.Printf("%d
", v)
}
二维数组
var a[3][2]
其实二维数组可以通过excel表格理解,就是几行几列的问题,像上面的这个例子就是一个3行2列的二维数组。
关于二维数组的遍历,创建一个二维数组并循环赋值,然后循环打印内容
var c [3][2]int
for i := 0; i < 3; i++ {
for j := 0; j < 2; j++ {
c[i][j] = rand.Intn(10)
}
}
for i := 0; i < 3; i++ {
for j := 0; j < 2; j++ {
fmt.Printf("%d ", c[i][j])
}
fmt.Println()
}
关于数组的比较
如果两个数组的元素类型相同是可以相互比较的,例如数组a:= [2]int{1,2}和数组b:=[2]int{3,4}
因为同样都是int类型,所以可以通过==来比较两个数组,看两边的元素是否完全相同,使用!= 比较看两边的元素是否不同
通过下面的例子演示更加清晰
a := [2]int{1, 2}
b := [...]int{1, 2}
c := [2]int{3, 2}
d := [3]int{1, 2}
fmt.Println(a == b, a == c, b == c)
fmt.Println(a == d)
上面的例子中第一个打印的结果是true,false,false,而当添加第二个打印的时候,就无法编译过去,因为两者是不能比较的
切片slice
定义
slice 表示一个拥有相同类型元素的可变长的序列
定义一个slice其实和定义一个数组非常类似
var 变量名[]type
var b = []int
和数组对比slice似乎就是一个没有长度的数组
slice的初始化
var a[5] int //这是定义一个数组
var b[]int = a[0,2]
var b[]int = a[0:5]
var b[]int = a[:]
var b[]int = a[:3]
var b[] int = []int{1,2,3,4}
同样遍历切片和数组是一模一样的
通过把数组和slice对比我们其实可以发现,两者其实非常类似,当然两者也确实有着紧密的关系
slice的底层实现就是一个数组,通常我们会叫做slice的底层数组。
slice具有三个属性:指针,长度和容量,如下图
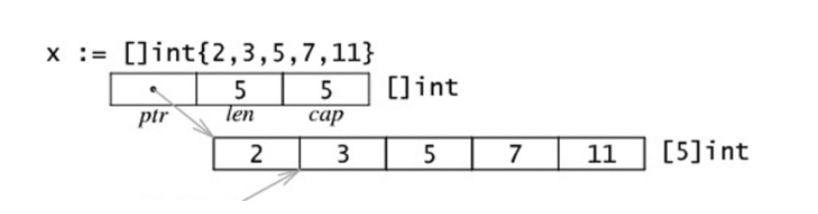
指针指向数组的第一个可以从slice中访问的元素,这个元素不一定是数组的第一个元素
长度是指slice中元素的个数,不能超过slice的容量
容量的大小是从slice的起始元素到底层数组的最后一个元素的个数
通过len和cap可以获取slice的长度和容量
通过下面例子理解:
var s = [5]int{1, 2, 3, 4, 5}
var b = s[2:3]
var c = s[0:4]
现在问b的长度以及容量,c的长度以及容量
对比上面的定义其实很好明白
s 就好比slice的底层数组
而对于b这个slice来说他是从数组的第三个元素开始切片,切片的时候是左闭右开原则
所以b的长度是1
对于b的容量根据定义我们知道是从数组的第三个元素到数组的最后
所以b的容量是3
这样我们也可以很容易得到c的长度是3,容量是5
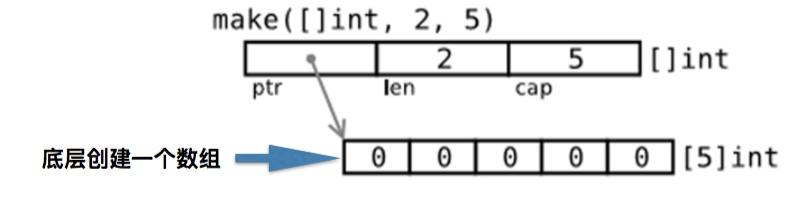
slice创建
内置函数make可以创建一个具有指定元素类型、长度和容量的slice,其中容量参数可以省略,这样默认slice的长度和容量就相等了
make([]type,len,cap)
make([]type,len)
现在说说关于:
make([]type,len)
make([]type,len,cap)
其实make创建了一个无名数组并返回了它的一个slice;这个数组仅可以通过slice来访问。
第一个:make([]type,len)返回的slice引用了整个数组。
第二个:make([]type,len,cap)slice只引用了数组的前len个元素,但是它的容量是数组的长度
通过下图理解切片的创建过程:
关于copy
该函数主要是切片(slice)的拷贝,不支持数组
将第二个slice里的元素拷贝到第一个slice里。如果加入的两个数组切片不一样大,就会按其中较小的那个数组切片的元素个数进行复制。
s1 := []int{1, 2, 3, 7, 8}
s2 := []int{4, 5, 6}
copy(s2, s1)
fmt.Printf("%#v
", s2)
这样打印s2的结果就是:[]int{1, 2, 3}
将代码更改为:
s1 := []int{1, 2, 3, 7, 8}
s2 := []int{4, 5, 6}
copy(s1, s2)
fmt.Printf("%#v
", s1)
这样打印s1的结果为:[]int{4, 5, 6, 7, 8}
这次拷贝就是把s2中的前三个元素拷贝到s1中的前三个,把s1中的前三个进行了覆盖
关于append
内置的函数append可以把元素追加到slice的后面
通过下面例子理解,把“hello go”每个字符循环添加到一个slice中
var runnes []rune for _, v := range "hello,go" { runnes = append(runnes, v) } fmt.Printf("%q ", runnes)
例子2直接在一个已经有元素的slice追加
s1 := []int{1, 2, 3}
s1 = append(s1, 4, 5)
fmt.Printf("%#v
", s1)
如果想要把另外一个slice也直接append到现在的slice中:
s1 := []int{1, 2, 3}
s2 := []int{4, 5}
s1 = append(s1, s2...)
fmt.Printf("%#v
", s1)
这里在s2后面通过...其实就是把s2中的元素给展开然后在append进s1中
其实append函数对于理解slice的工作原理是非常重要的,下面是一个为[]int数组slice定义的一个方法:
func appendInt(x []int, y int) []int {
var z []int
zlen := len(x) + 1
if zlen <= cap(x) {
//slice仍有增长空间扩展slice内容
z = x[:zlen]
} else {
//slice 已经没有空间,为他分配一个新的底层数组
//当然实际go底层扩展的时候的策略可能复杂的多,这里是通过扩展一倍为例子
zcap := zlen
if zcap < 2*len(x) {
zcap = 2 * len(x)
}
z = make([]int, zlen, zcap)
copy(z, x)
}
z[len(x)] = y
return z
从上面的这个方法可以看出:
每次appendInt的时候都会检查slice是否有足够的容量来存储数组中的新元素,如果slice容量足够,那么他会定义一个新的slice,注意这里仍然引用原始的底层数组,然后将新元素y复制到新的位置,并返回新的slice,这样我们传入的参数切片x和函数返回值切片z其实用的是相同的底层数组。
如果slice的容量不够容纳增长的元素,appendInt函数必须创建一个拥有足够容量的新的底层数组来存储新的元素,然后将元素从切片x复制到这个数组,再将新元素y追加到数组后面。这样返回的切片z将和传入的参数切片z引用不同的底层数组。
关于切片的比较
和数组不同的是,切片是无法比较的,因此不能通过==来比较两个切片是否拥有相同的元素
slice唯一允许的比较操作是和nill比较,切片的零值是nill
这里需要注意的是:值为nill的slice的长度和容量都是零,但是这不是决定的,因为存在非nill的slice的长度和容量是零所以想要检查一个slice是否为还是要使用len(s) == 0 而不是s == nill
下面是整理的练习切片使用的例子
如何修改一个字符串?
package main
import (
"fmt"
)
func changeString(str1 string) {
var runnes = []rune(str1)
runnes[0] = 'h'
res := string(runnes)
fmt.Println(res)
}
func main() {
changeString("Hello,Go")
}
这里是把开头的大写的h换成了小写
再看一个例子:
实现字符串的反转
func reverseStr(str1 string) {
var runes = []rune(str1)
var res string
for i := len(runes) - 1; i >= 0; i-- {
res += string(runes[i])
}
fmt.Println(res)
}
上面这个方法就可以实现对字符串的反转,当然方法不止一种,下面也是一种方法
func reverseStr2(str1 string) { var runes = []rune(str1) for i, j := 0, len(runes)-1; i < j; i, j = i+1, j-1 { runes[i], runes[j] = runes[j], runes[i] } res := string(runes) fmt.Println(res) }
上面的方法中我一直在用到rune,这个东西是什么东西呢?接着看
在Go当中的字符换string 底层是用byte数组存的,并且是不可改变的
当我们通过for key, value := range str这种方式循环一个字符串的时候,其实返回的每个value类型就是rune
而我们知道在go中双引号引起来的是字符串string,在go中表示字符串有两种方式:
一种是byte,代表utf-8字符串的单个字节的值;另外一个是rune,代表单个unicode字符串
关于rune官网中一段解释:
rune is an alias for int32 and is equivalent to int32 in all ways. It is
used, by convention, to distinguish character values from integer values.
var a = "我爱你go"
fmt.Println(len(a))
上面已经说了,字符串的底层是byte字节数组,所以我们通过len来计算长度的时候,其实就是获取的该数组的长度,而一个中文字符是占3个字节,所以上面的结果是11
可能很多人第一眼看的时候,尤其初学者可能会觉得长度应该是5,其实,如果想要转换成4只需要通过虾米那方式就可以:
var a = "我爱你go"
fmt.Println(len([]rune(a)))
时间和日期类型
当前时间:now:= time.Now()
time.Now().Day()
time.Now().Minute()
time.Now().Month()
time.Now().Year()
time.Duration用来表示纳秒
一些常用的时间常量
const (
Nanosecond Duration = 1
Microsecond =1000 * Nanosecond
Millisecond =1000 * Microsecond
Second =1000 * Millisecond
Minute =60 * Second
Hour =60 * Minute
)
注意:如果想要格式化时间的时候,要特别特别注意,只能通过如下方式格式化:
fmt.Println(time.Now().Format("2006-01-02 15:04:05"))
Format里面的时间是固定的,因为是go第一个程序的诞生时间,也不知道go的开发者怎么想的,估计是想让所有学习go的人记住这个伟大的时刻吧
切片处理补充
关于切片删除
package main
import "fmt"
func main() {
index := 2
var s = []int{10,15,8,20}
s = append(s[:index],s[index+1:]...)
fmt.Println(s)
}