关于下载网页源码再来解析,这是一套简单的java爬虫
这里简单说说网页的下载。
其实用很多方法,比较好用的有httpclient。但是原理都是从URLConnection这里衍生来的。所以这先讲讲URLConnection下载网页源码的方式。
这个下载其实方法不难,难的是如何寻找到合适的编码。如果编码不对的话,中文容易造成乱码的情况。那么,有什么方法?
方法一:
从http返回的响应头获取。在使用urlconnection链接后,会有一个响应头返回如连接 :https://www.w3school.com.cn/,这里的响应头没有给出编码集,

如果连接:https://i-beta.cnblogs.com,所以这是一种方法,

方法二:
第二种方法是从网页的源码中获取,毕竟编码不同的话不会影响英文显示的。
如:
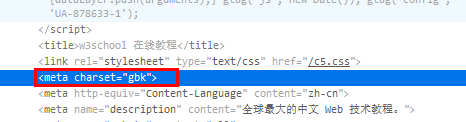
所以可以用这两种方式,一定要结合使用,先从http的响应头部获取,如果找到编码的话,那个一定是正确的。至于方法二目前使用状态是正确的。如果两种
方式都不能获取到,则只能使用默认的编码了。
代码如下:
1 package com.xu.download; 2 3 import java.io.BufferedReader; 4 import java.io.IOException; 5 import java.io.InputStream; 6 import java.io.InputStreamReader; 7 import java.net.MalformedURLException; 8 import java.net.URL; 9 import java.net.URLConnection; 10 import java.util.List; 11 import java.util.Map; 12 13 import javax.net.ssl.HttpsURLConnection; 14 15 /** 16 * @author 徐金仁 17 * 使用urlpconnection下载网页源码, --初级java爬虫 18 */ 19 public class Download { 20 //最困难的地方:编码 21 /* 22 * 网页都是不同的人制作的,他们的编码不会保持一致。我们如果用错了编码的话,如果网页中含有中文, 23 * 则会出现乱码 24 */ 25 26 27 /** 28 * 下载网页源码 29 * @param url 下载的地址 30 * @return 返回的是网页源码 31 * @throws Exception 32 */ 33 public String download(String url){ 34 StringBuffer htmlSource = new StringBuffer(); 35 URL url_ = null; 36 InputStream is = null; 37 38 BufferedReader reader = null; 39 try { 40 //定位资源 41 url_ = new URL(url); 42 //打开链接 43 URLConnection con = url_.openConnection(); 44 45 //获取正确的编码集 46 String charset = getCharset(url, "utf-8"); 47 48 System.out.println("charset = " + charset); 49 50 is = con.getInputStream(); 51 //使用正确的编码来编码流 52 reader = new BufferedReader(new InputStreamReader(is,charset)); 53 54 String line = null; 55 //读写 56 while((line = reader.readLine()) != null){ 57 htmlSource.append(" "); 58 htmlSource.append(line); 59 } 60 61 } catch (IOException e) { 62 e.printStackTrace(); 63 }finally{ 64 if(is != null){ 65 try { 66 is.close(); 67 } catch (IOException e) { 68 // TODO Auto-generated catch block 69 e.printStackTrace(); 70 } 71 } 72 73 if(reader != null){ 74 try { 75 reader.close(); 76 } catch (IOException e) { 77 // TODO Auto-generated catch block 78 e.printStackTrace(); 79 } 80 } 81 } 82 return htmlSource.toString(); 83 } 84 85 /** 86 * 获取正确的编码集 87 * 要从两个个地方下手 88 * 1.http链接的头部信息 89 * 2.html源码中显示表明的编码 90 * @param url 网页地址 91 * @param string 默认的编码集 92 * @return 93 * @throws IOException 94 */ 95 private String getCharset(String url, String defaultCharset) throws IOException { 96 String charset = null; 97 98 URL url_ = null; 99 //定位资源 100 url_ = new URL(url); 101 //打开链接 102 URLConnection con = url_.openConnection(); 103 //获取http响应回来的头部信息 104 Map<String, List<String>> headerField = con.getHeaderFields(); 105 System.out.println(headerField); 106 List<String> line = headerField.get("Content-Type"); 107 if(line == null){ 108 line = headerField.get("content-type"); 109 } 110 111 if(line != null){ 112 for(String st : line){ 113 if(st.contains("charset")){ 114 //说明找到了编码 115 charset = st.split(";")[1].split("=")[1].trim(); 116 break; 117 } 118 } 119 } 120 //说明没有找到,要到源码里面取寻找 121 if(charset == null){ 122 //获取流 123 InputStream is; 124 is = con.getInputStream(); 125 BufferedReader reader = new BufferedReader(new InputStreamReader(is)); 126 String line_str = null; 127 String cha = null; 128 //一行行读下去 129 while((line_str = reader.readLine()) != null){ 130 //去掉所有的空格 131 line_str = line_str.replaceAll(" ", ""); 132 //去掉引号 133 line_str = line_str.replaceAll(""", ""); 134 if(line_str.contains("meta")){ 135 if(line_str.contains("charset")){ 136 //将charset开始到最后的双引号为止截取,区间左开右闭 137 int index = line_str.indexOf("charset"); 138 cha = line_str.substring(index, line_str.indexOf("/", index)); 139 charset = cha.split("=")[1]; 140 System.out.println("c2:" + charset); 141 break; 142 } 143 } 144 145 } 146 //说明以上两种方法都没有用 147 if(charset ==null){ 148 //设置为默认的 149 charset = defaultCharset; 150 } 151 } 152 return charset; 153 } 154 155 /** 156 * 测试 157 * @param args 158 * @throws Exception 159 */ 160 public static void main(String[] args) throws Exception { 161 String htm = new Download().download("https://www.w3school.com.cn/"); 162 System.out.println("源码:" + htm); 163 } 164 }
结果如下:
