OO第一单元总结
一、程序结构分析
首先让我们忽略所有具体的数据存储结构,从宏观算法拆分的层级来审视一下三次作业下来我的成长与不足。
第一次作业——多项式求导
1.结构
第一次作业于我来说可谓对面向对象编程的初识,在本次作业的过程中我完成了从一Main到底到面向对象的转变,两者间的优劣差距由以下分析一眼可知。
涉及到核心功能的UML类图如下:
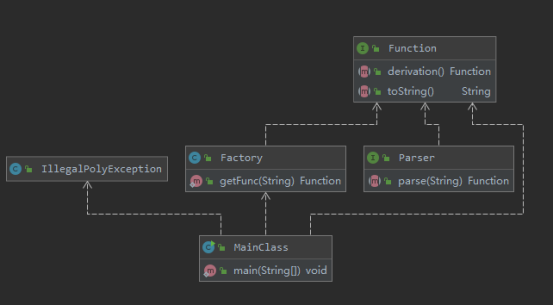
当面对第一次作业这类功能单一、情况简单的问题时,与最极端的过程式设计(一Main到底)的鲜明对比之下,面向对象编程最大的两个优点暴露的最为明显,而这也是我们学习面向对象设计的原因所在。
以上两个UML图形象直观的为我们揭露了面向对象设计的第一个优点——可扩展性潜能与扩展复杂度的降低。
前者对与新功能的扩展,前者从存储结构的更改、新增方法的分析到方法嵌入的全局设计,步步皆繁琐、易疏漏、易犯错,并且随扩展规模的增大,错误率与复杂度的增长幅度愈发令我们难以接受。
反观后者,每一新功能的实现被拆分为相关接口下类及方法的补充,在已有的框架模式下,我们往往只需关注新功能无法在次基础上实现的部分
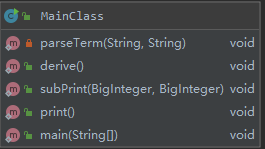
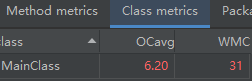
2.复杂度分析(度量)
一Main到底:
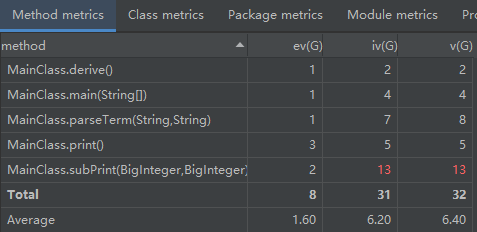
面向对象:
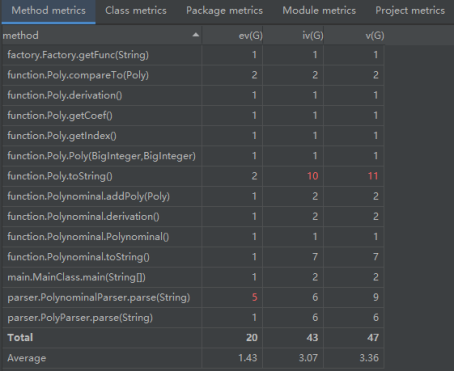
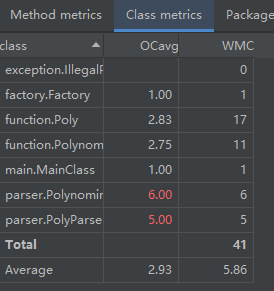
借助Metrics的分析,面向对象设计的第二大优点也浮出水面——错误类型的拆分与错误率的消减。
尽管第一次作业的问题规模如此之小,在一Main到底设计中,方法的三种平均复杂度已比面向对象设计明显升高。也就是说,前者在每一个方法中发生错误的概率都要比后者高出许多,不难想象,在问题规模不断扩大的过程中,这一差距更将以爆炸性的速度增长,成为我们工程化设计中无法接受的弊病。
从类的分析来看,集成了所有设计的MainClass类所埋下可能发生错误的“地雷”数量要远多于面向对象设计中的任何一个类。无论“地雷”的数量多出多少,“拆雷”的过程都并不可怕,真正可怕的是“寻雷”的过程以及“雷越拆越多”的致命隐患。
面向对象设计对于错误类型的拆分远远不止分类这么简单,其所带来的秩序化结构与模块化拆分可以使错误率大大下降,也可以使寻错debug的过程大大简化。
第二次作业——三角函数的扩展
在面向对象设计所构筑好的架构之下,新函数类的增添成了水到渠成之事,而这次作业为我们却为我们暴露出架构扩展两大最大的问题——输入处理与输出优化。
1.结构
涉及到核心功能的UML类图如下:
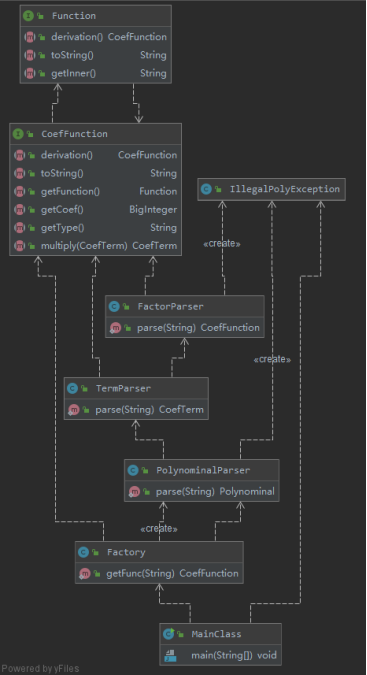

以上两UML图中,第一章UML图为顶层涉及架构,第二层UML图则反映了函数求导递归算法的调用机制。
通过以上两图不难看出,对于新函数的增添很好的被我们涵盖在了顶层设计框架的扩展性接口之下,我们需要完成的工作只是将新的函数类与已有类之间链接起来而已。
2.复杂度分析(度量)
高复杂度方法与类:

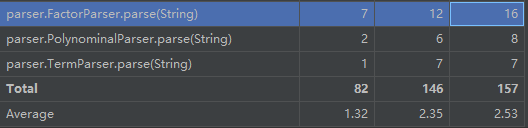
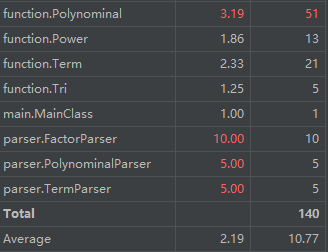
正如前文所言,程序的复杂度集中出现在了输入解析与输出优化部分,这也显示出我们程序bug的高发区域,合理选择输入解析方式、合理设计优化算法成为我们不可避免的重要任务。
第三次作业——增加嵌套因子和表达式因子
本次作业难点有二,一为对输入处理的挑战,二为函数类之间的耦合设计。
1.结构
涉及到核心功能的UML类图如下:
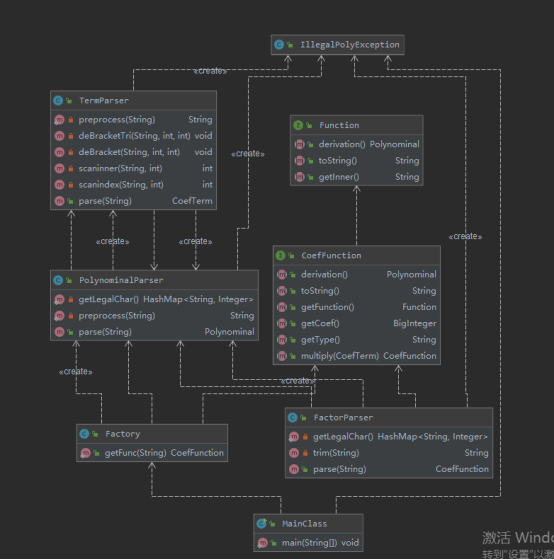
顶层设计的架构与第二次作业没有区别,可见面向对象设计可扩展性之强大,不同之处在于解析类中多出的许多方法,而这些源于我在这次作业中对于输入处理策略的重构,后文中将展开叙述。
2.复杂度分析(度量)
高复杂度方法与类:
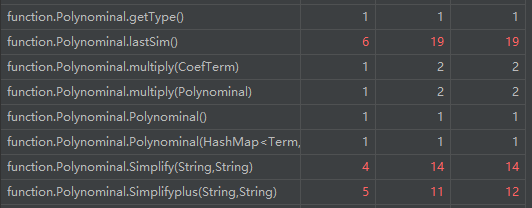
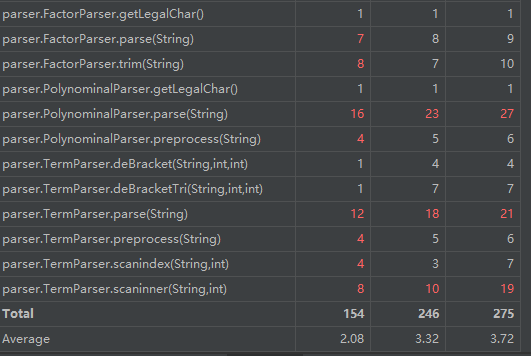
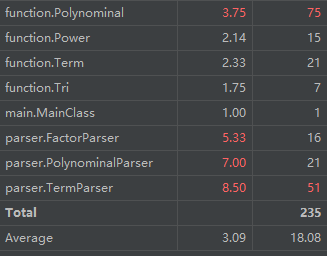
这部分与第二次作业复杂度分析宏观部分基本一致(输入处理与输出优化复杂度高),微观复杂度分配有细微差异。
通过第三次作业的程序架构分析我有很多收获与体会,将在第五部分对比和心得体会处展开讲解。
二、BUG分析
在第二次作业中出现1个BUG,原因是优化sin(x)**4-cos(x)**4情况过程中,将缩短结果加入原多项式时未合并同类项。
在第三次作业中出现1个BUG,原因是为程序运行时间,检查内层函数不含变量时之间中断递归求导,却忘记对内部常数进行格式检查。
两次bug的出现都是优化部分的一个很难察觉的细节,为杜绝这种现象再次发生,更具针对性的测试样例设计以及优化设计时的再三小心是最好的办法。
三、测试样例构建
自动比对评测机是这次作业中我习得的,在以后每一次作业中都将节省大量时间精力的高效测试工具。
而对于测试样例的构建,我个人有两种策略,随机的测试数据自动生成以及手动构建覆盖性测试样例。
对于手动构建覆盖性测试样例我个人认为比较高效的方法是在进行输入解析设计的过程中同步构建,每一种设计的分支都记录下与之匹配的设计样例,既无需在代码完成后回头设计测试样例,又可以对每一步设计进行较充分的样例检查。
四、应用对象创建模式来重构
在第一次作业的重构过程中,我便深刻体会到了对象创建模式的简洁与高效,于是在之后扩展的每一步都基于类似的思想完成,设计了如下UML图所示的对象创建结构:
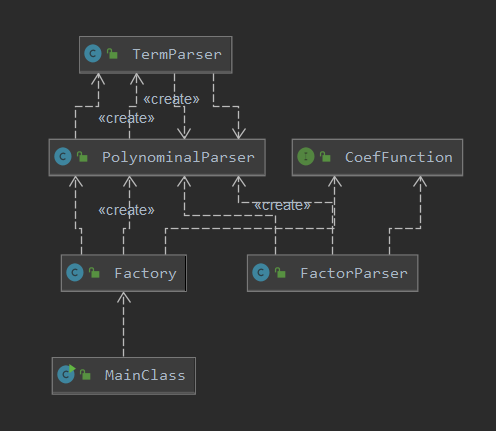
但是我目前所设计的对象创建模式还比较单一简单,需要学习的相关知识还有很多。
五、对比和心得体会
这个单元的作业带给了我满满的收获,我从中总结出以下几部分在后续的开发中都可以拓展应用的设计。
1.从大正则到自动机——输入处理
前两次作业为了偷懒并减少错误,我均采用了大正则的输入处理方式,但是在第三次作业中,这种方式的延展性终于走到了尽头,于是我进行了重构,采用了有限状态机的方法,该方法的具体实现因问题输入形式而异,但其只需一趟扫描所带来的性能上的优势以及一些通用的技巧方法却是值得整理总结的。
如对于输入的层次化解析(多个状态机的嵌套使用),在输入部分通过递归调用完成一部分化简优化,以及与工厂模式结合的对象创建流程。
在研讨课上听过张家树同学的总结之后,我对于这一方法也产生了更为深刻的理解。
2.基于多态的递归算法使用——优化与求导
在本单元作业的求导与优化部分,依赖于JAVA语言中多态的特性,使用递归算法均可用较少的代码量、较低的复杂度实现高效的处理。
而当递归和输入处理有机结合,又可以产生在解析数据阶段就实现一部分化简的高效功能。
3.层次化的设计模式
从初始面向对象设计到初识设计模式,可谓是这个单元给我带来的最大的收获,使我的代码有了“赏心悦目”的架构。
当然,由程序结构分析部分可见,在我第三次作业最终版的代码中,仍存在着许多设计上的不足。比如我将优化算法集成在多项式类内部,造成了该类的过度繁杂;对于CoefFunction和Function的理解不够透彻,开始设计时完全可以省略Function这一冗余接口;将函数间的组合规则单独维护成一个类,也是更好的一种选择。研读过推荐的优秀代码之后,我对于这些问题都有了深刻的认识。