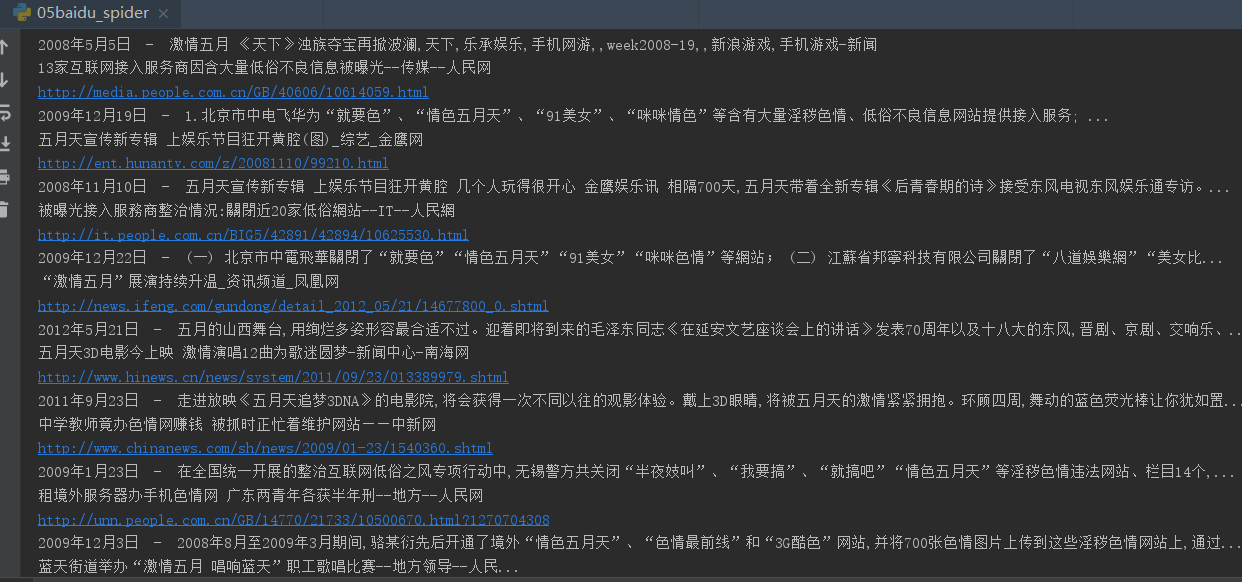
1、场景
爬虫练手代码
2、代码
Python2:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import requests
from lxml import etree
import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
def getfromBaidu(word):
list=[]
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, compress',
'Accept-Language': 'en-us;q=0.5,en;q=0.3',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
}
baiduurl = 'http://www.baidu.com'
url = 'http://www.baidu.com.cn/s?wd=' + word + '&cl=3'
html = requests.get(url=url,headers=headers)
path = etree.HTML(html.content)
#用k来控制爬取的页码范围
for k in range(1, 20):
# 取出内容
path = etree.HTML(requests.get(url, headers).content)
flag = 11
if k == 1:
flag = 10
for i in range(1, flag):
# 获取标题
sentence = ""
for j in path.xpath('//*[@id="%d"]/h3/a//text()'%((k-1)*10+i)):
sentence+=j
print sentence # 打印标题
# 获取真实URL
try:
url_href = path.xpath('//*[@id="%d"]/h3/a/@href'%((k-1)*10+i))
url_href = ''.join(url_href)
baidu_url = requests.get(url=url_href, headers=headers, allow_redirects=False)
real_url = baidu_url.headers['Location'] # 得到网页原始地址
print real_url # 打印URL
except:
print "error",sentence,url_href
# 获取描述
res_abstract = path.xpath('//*[@id="%d"]/div[@class="c-abstract"]'%((k-1)*10+i))
if res_abstract:
abstract = res_abstract[0].xpath('string(.)')
else:
res_abstract = path.xpath('//*[@id="%d"]/div/div[2]/div[@class="c-abstract"]' % ((k - 1) * 10 + i))
if res_abstract:
abstract = res_abstract[0].xpath('string(.)')
print abstract # 打印描述
url = baiduurl+path.xpath('//*[@id="page"]/a[%d]/@href'%flag)[0]
return
#主程序测试函数
if __name__ == '__main__':
print getfromBaidu('上网')
3、效果