1. 问题描述:
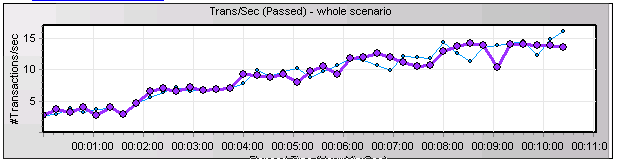
客户新上的一个关键业务系统,在做上线前的压力测试时,应用的并发无法达到上线前的并发指标和响应时间指标要求。压测时TPS的曲线很不稳定,如下所示:
2. 分析过程:
从上述知识点可以知道:
ORACLE中LGWR进程只有一个,由于所有进程在commit前都需要通知lgwr进程帮忙把之前在log buffer中生成的修改过程记录(改变向量)写到磁盘中。
当大量进程要同时请lgwr进程帮忙写时,就出现排队的情况。
在高并发的联机交易OLTP系统中,单进程的lgwr进程有可能成为一个大瓶颈,特别是在无法在线日志IO写性能出现问题的情况下。
因此,我们需要检查lgwr进程的状态。
通过gv$session观察RAC两个节点lgwr进程写日志的情况,结果如下图所示:
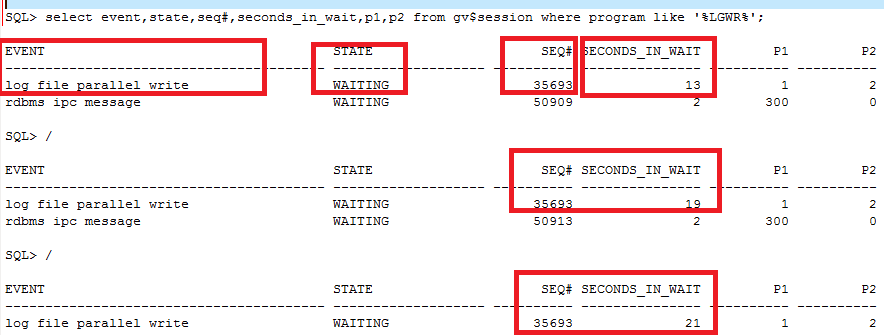
可以看到:
Ø RAC(数据库集群)两个节点中,只有1个节点出现log file parallel write的等待,该等待表示lgwr进程正在对磁盘的在线日志文件进行写操作。
Ø 在state是waiting的情况下,节点1 log file parallel等待的seq#都是35693,但是seconds_in_wait达到了21秒。简单来说,就是lgwr进程写一个IO需要21秒!
这意味着,压测时所有并发进程必须要发生等待,等lgwr进程完成这个的IO,才可以继续通知LGWR进程帮忙刷log buffer的改变向量,因此从压测的TPS曲线来看,就是不稳定,出现了大幅衰减。
至此,我们可以肯定,IO子系统有问题
需要重点排查IO路径下的光纤线、SAN交换机、存储的报错和性能情况。、
考虑到客户那边管存储的团队/部门可能不承认数据库的IO慢的证据,同时为了让对方增加排查力度,远邦让客户发出以下命令,查看多路径软件的IO情况,结果如下图所示:
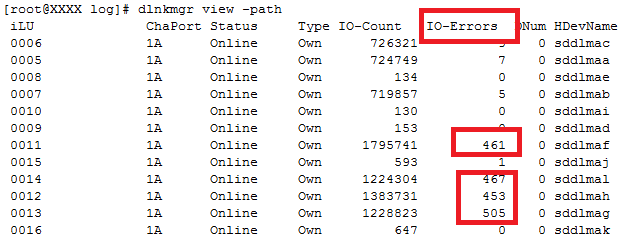
节点1上出现明显的IO ERROR,并且在持续增加!
继续检查节点2,发现节点2上没有任何IO ERROR!
这个与gv$session仅有一个进程在等log file parallel write写完是完全吻合的。
3. 原因
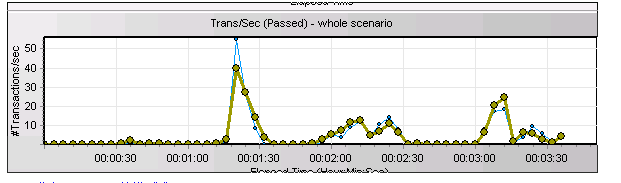
在铁的证据面前,客户的存储团队没有再挣扎,而是开始认认真真逐个在排查,最终在更换了光纤线后问题得到圆满解决。以下是更换光纤线后再次压测的等待事件!
4. 问题得到解决
压测的TPS曲线从原来的波浪形
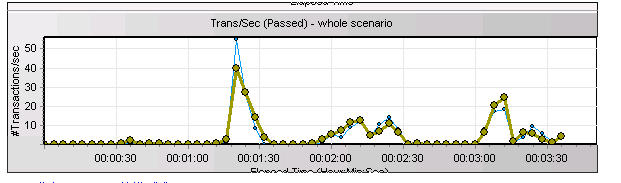
变成了如下的良好曲线