1.选一个自己感兴趣的主题。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
在本次作业,我决定爬取网易新闻科技频道的IT专题,首先这是新闻频道的首页。
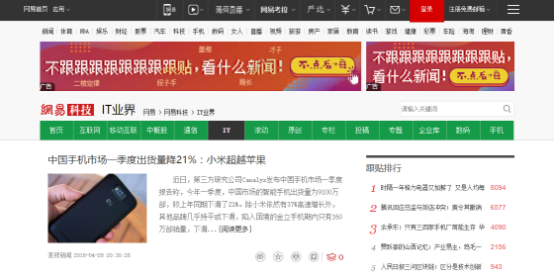
首先我们打开浏览器的开发者工具,快捷键为F12会Ctrl+Shift+I,找到我们要爬取新闻的新闻内容列表结构。
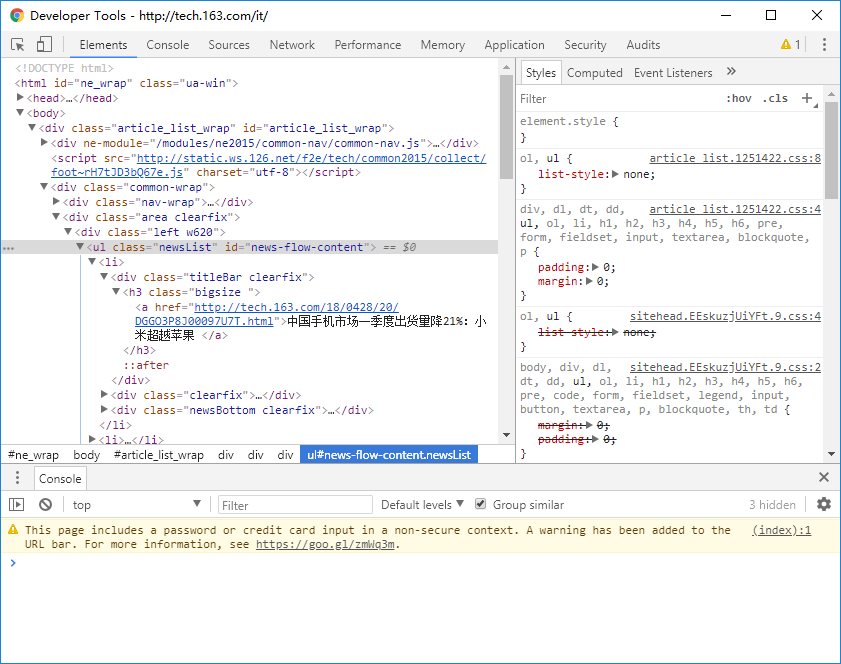
所以我们可以发现新闻列表都存储在类为 .newsList 的标签里,新闻链接存储在类为 .titleBar 的标签里的 <a> 标签内。
然后问我们打开一个新闻页,分析它的结构。依然打开开发者工具,分析其结构
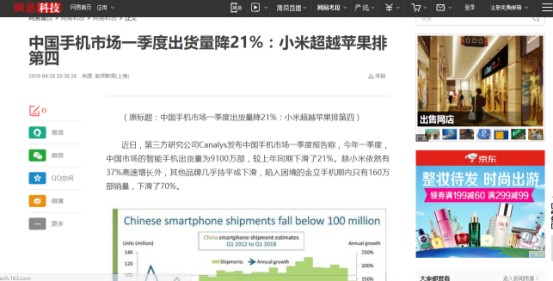
新闻详情页
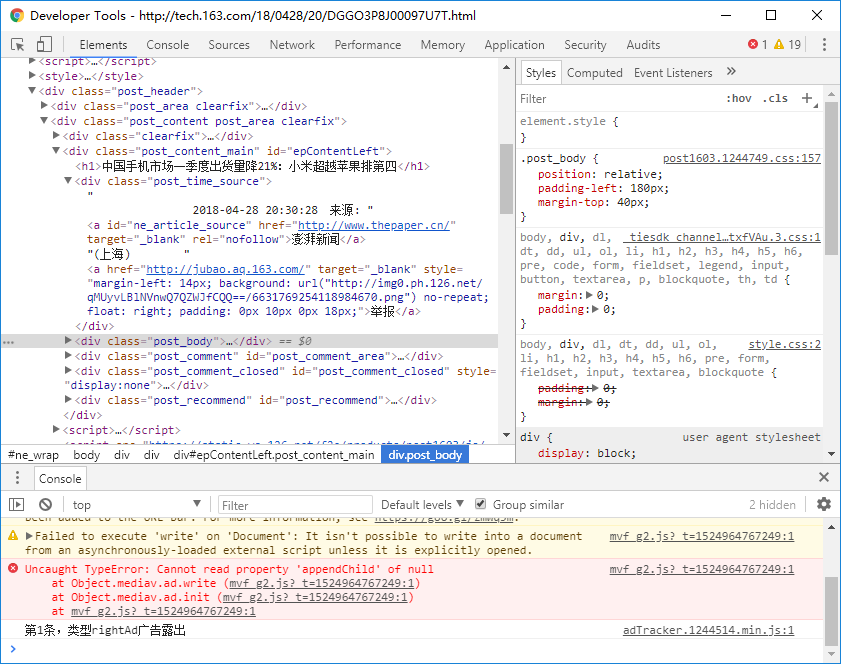
新闻结构
所以我们发现新闻内容都存储在类为 .post_content_main 的标签里,其中新闻信息存储在类为 .post_time_source 的标签里,标题存储在 <h1> 标签里。
详细代码如下:
import requests, re, jieba, pandas from bs4 import BeautifulSoup from datetime import datetime from wordcloud import WordCloud import matplotlib.pyplot as plt # 获取新闻细节 def getNewsDetail(newsUrl): res = requests.get(newsUrl) res.encoding = 'gb2312' soupd = BeautifulSoup(res.text, 'html.parser') detail = {'title': soupd.select('#epContentLeft')[0].h1.text, 'newsUrl': newsUrl, 'time': datetime.strptime( re.search('(d{4}.d{2}.d{2}sd{2}.d{2}.d{2})', soupd.select('.post_time_source')[0].text).group(1), '%Y-%m-%d %H:%M:%S'), 'source': re.search('来源:(.*)', soupd.select('.post_time_source')[0].text).group(1), 'content': soupd.select('#endText')[0].text} return detail # 通过jieba分词,获取新闻词云 def getKeyWords(): content = open('news.txt', 'r', encoding='utf-8').read() wordSet = set(jieba._lcut(''.join(re.findall('[u4e00-u9fa5]', content)))) # 通过正则表达式选取中文字符数组,拼接为无标点字符内容,再转换为字符集合 wordDict = {} deleteList, keyWords = [], [] for i in wordSet: wordDict[i] = content.count(i) # 生成词云字典 for i in wordDict.keys(): if len(i) < 2: deleteList.append(i) # 生成单字无意义字符列表 for i in deleteList: del wordDict[i] # 在词云字典中删除无意义字符 dictList = list(wordDict.items()) dictList.sort(key=lambda item: item[1], reverse=True) for dict in dictList: keyWords.append(dict[0]) writekeyword(keyWords) # 将新闻内容写入到文件 def writeNews(pagedetail): f = open('news.txt', 'a', encoding='utf-8') for detail in pagedetail: f.write(detail['content']) f.close() # 将词云写入到文件 def writekeyword(keywords): f = open('keywords.txt', 'a', encoding='utf-8') for word in keywords: f.write(' ' + word) f.close() # 获取一页的新闻 def getListPage(listUrl): res = requests.get(listUrl) res.encoding = "utf-8" soup = BeautifulSoup(res.text, 'html.parser') pagedetail = [] # 存储一页所有新闻的详情 for news in soup.select('#news-flow-content')[0].select('li'): newsdetail = getNewsDetail(news.select('a')[0]['href']) # 调用getNewsDetail()获取新闻详情 pagedetail.append(newsdetail) return pagedetail def getWordCloud(): keywords = open('keywords.txt', 'r', encoding='utf-8').read() # 打开词云文件 wc = WordCloud(font_path=r'C:WindowsFontssimfang.ttf', background_color='white', max_words=100).generate( keywords).to_file('kwords.png') # 生成词云,字体设置为可识别中文字符 plt.imshow(wc) plt.axis('off') plt.show() pagedetail = getListPage('http://tech.163.com/it/') # 获取首页新闻 writeNews(pagedetail) for i in range(2, 20): # 因为网易新闻频道只存取20页新闻,直接设置20 listUrl = 'http://tech.163.com/special/it_2016_%02d/' % i # 填充新闻页,页面格式为两位数字字符 pagedetail = getListPage(listUrl) writeNews(pagedetail) getKeyWords() # 获取词云,并且写到文件 getWordCloud() # 从词云文件读取词云,生成词云
生成词云结果
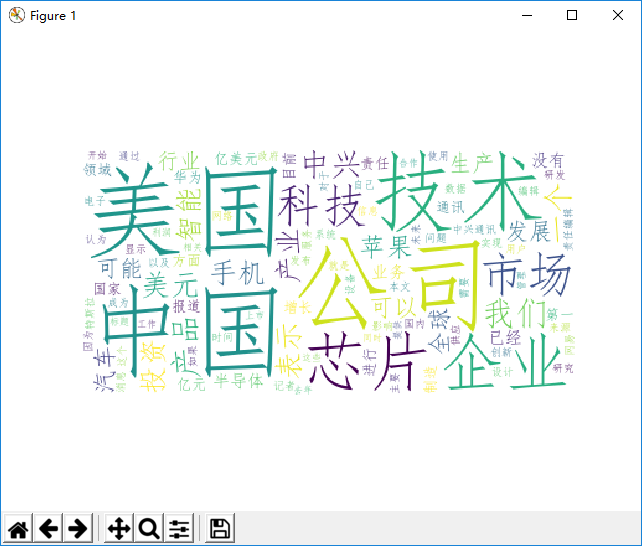
我们可以从此图中分析出,科技新闻近期热点是中美、技术公司等,可以了解到无论是在中国还是美国,在IT行业中一个公司最重要的因素就是技术,其次是产品产业诸如芯片等的由此才能占据IT领域的市场。
结果: