本文由 网易云 发布。
本文具体讨论了Join基础算法的一种优化方案 – Runtime Filter,在本文最后还引申地聊了聊谓词 下推技术。同时,在本文文章开头,笔者引出了两个问题,SQL执行引擎如何知晓参与Join的两波数据集大小?衡量两波数据集 大小的是物理大小还是纪录多少抑或两者都有?这关系到SQL解析器如何正确选择Join算法的问题。好了,这些就是这篇文章要为 大家带来的议题-基于代价优化(Cost-Based Optimization,简称CBO)。
CBO基本原理
提到CBO,就不得不提起一位’老熟人’ – 基于规则优化(Rule-Based Optimization,简称RBO)。RBO是一种经验式、启发式 的优化思路,优化规则都已经预先定义好,只需要将SQL往这些规则上套就可以。说白了,RBO就像是一个经验丰富的老司机,基 本套路全都知道。
然而世界上有一种东西叫做 – 不按套路来,与其说它不按套路来,倒不如说它本身并没有什么套路。最典型的莫过于复杂Join算子 优化,对于这些Join来说,通常有两个选择题要做:
1. Join应该选择哪种算法策略来执行?BroadcastJoin or ShuffleHashJoin or SortMergeJoin?不同的执行策略对系统的资源要求 不同,执行效率也有天壤之别,同一个SQL,选择到合适的策略执行可能只需要几秒钟,而如果没有选择到合适的执行策略就可能 会导致系统OOM。
2. 对于雪花模型或者星型模型来讲,多表Join应该选择什么样的顺序执行?不同的Join顺序意味着不同的执行效率,比如A join B join C,A、B表都很大,C表很小,那A join B很显然需要大量的系统资源来运算,执行时间必然不会短。而如果使用A join C join B的执行顺序,因为C表很小,所以A join C会很快得到结果,而且结果集会很小,再使用小的结果集 join B,性能显而易见会好于 前一种方案。
大家想想,这有什么固定的优化规则么?并没有。说白了,你需要知道更多关于表的基础信息(表大小、表记录总条数等),再通 过一定规则代价评估才能从中选择一条最优的执行计划。CBO意为基于代价优化策略,就是从多个可能的语法树中选择一条代价最 小的语法树来执行,换个说法,CBO的核心在于评估出一条给定语法树的实际代价。比如下面这颗SQL语法树:

要评估给定整棵树的代价,分而治之只需要评估每个节点执行的代价,最后将所有节点代价累加即可。而要评估单个节点执行实际 代价,又需要知道两点,其一是这种算子的代价规则,每种算子的代价计算规则必然都不同,比如Merge-Sort Join、Shuffle Hash Join、GroupBy都有自己的一套代价计算算法。其二是参与操作的数据集基本信息(大小、总记录条数),比如实际参与 Merge-Sort Join的两表大小,作为节点实际执行代价的一个重要因素,当然非常重要。试想,同样是Table Scan操作,大表和小 表的执行代价必然不同。
为给定算子的代价进行评估说到底也是一种算法,算法都是死的,暂且不表,下文详述。而参与的数据集基本信息却是活的,为什 么如此说,因为这些数据集都是原始表经过过滤、聚合之后的中间结果,没有规则直接告诉你这个中间结果有多少数据!那中间结 果的基本信息如何评估呢?推导!对,原始表基本信息我们是可以知道的,如果能够一层一层向上推导,是不是就有可能知道所求 中间结果信息!
这里又将任意节点中间结果信息评估拆分为两个子问题:首先评估叶子节点(原始表)的基本信息,其次一层一层往上推导。评估 原始表基本信息想想总是有办法的,粗暴点就全表扫描,获取记录条数、最大值、最小值,总之是可以做到的。那基本信息如何一 层一层往上推导呢?规则!比如原始表经过 id = 12这个Filter过滤之后的数据集信息(数据集大小等)就可以经过一定的规则推导 出来,不同算子有不同的规则,下文详述!
1. 基于代价优化(CBO)原理是计算所有执行路径的代价,并挑选代价最小的执行路径。问题转化为:如何计算一条给定执行路径 的代价;
2. 计算给定路径的执行代价,只需要计算这条路径上每个节点的执行代价,最后相加即可。问题转化为:如何计算其中任意一个节 点的执行代价;
3. 计算任意节点的执行代价,只需要知道当前节点算子的代价计算规则以及参与计算的数据集(中间结果)基本信息(数据量大 小、数据条数等)。问题转化为:如何计算中间结果的基本信息以及定义算子代价计算规则;
4. 算子代价计算规则是一种死的规则,可定义。而任意中间结果基本信息需要通过原始表基本信息顺着语法树一层一层往上推导得 出。问题转化为:如何计算原始表基本信息以及定义推导规则。
很显然,上述过程是思维过程,真正工程实践是反着由下往上一步一步执行,最终得到代价最小的执行路径。现在再把它从一个个 零件组装起来:
1. 首先采集原始表基本信息;
2. 再定义每种算子的基数评估规则,即一个数据集经过此算子执行之后基本信息变化规则。这两步完成之后就可以推导出整个执行 计划树上所有中间结果集的数据基本信息;
3. 定义每种算子的执行代价,结合中间结果集的基本信息,此时可以得出任意节点的执行代价;
4. 将给定执行路径上所有算子的代价累加得到整棵语法树的代价;
5. 计算出所有可能语法树代价,并选出一条代价最小的。
CBO基本实现思路
上文从理论层面分析了CBO的实现思路,将完整的CBO功能拆分为了多个子功能,接下来聊聊对每一个子功能的实现。
第一步,采集原始表基本信息
这个操作是CBO最基础的一项工作,采集的主要信息包括表级别指标和列级别指标,如下所示,estimatedSize和rowCount为表级 别信息,basicStats和Histograms为列级别信息,后者粒度更细,对优化更加重要。
estimatedSize: 每个LogicalPlan节点输出数据大小(解压)
rowCount: 每个LogicalPlan节点输出数据总条数
basicStats: 基本列信息,包括列类型、Max、Min、number of nulls, number of distinct values, max column length, average column length等
Histograms: Histograms of columns, i.e., equi-width histogram (for numeric and string types) and equi-height histogram (only for numeric types).
这里有两个问题值得思考:
1. 为什么要采集这些信息?每个对象在优化过程中起到什么作用?
2. 实际工程一般是如何实现这些数据采集的?
为什么要采集这些信息?很显然,estimatedSize和rowCount这两个值是算子代价评估的直观体现,这两个值越大,给定算子执行 代价必然越大,所以这两个值后续会用来评估实际算子的执行代价。那basicStats和Histograms这俩用来干啥呢,要不忘初心,之 所以采集原始表的这些信息,是为了顺着执行语法树往上一层一层推导出所有中间结果的基本信息,这俩就是来干这个的,至于怎 么实现的,下一小节会举个例子解释。
实际工程如何实现这些数据采集?一般有两种比较可行的方案:打开所有表扫描一遍,这样最简单,而且统计信息准确,缺点是对 于大表来说代价比较大;针对一些大表,扫描一遍代价太大,可以采用采样(sample)的方式统计计算。
支持CBO的系统都有命令对原始数据信息进行统计,比如Hive的Analyze命令、Impala的Compute命令、Greenplum的Analyze 命令等,但是需要注意这些命令并不是随时都应该执行的,首先在表数据没有大变动的情况下没必要执行,其次在系统查询高发期 也不应该执行。这里有个最佳实践:尽可能在业务低峰期对表数据有较大变动的表单独执行统计命令,这句话有三个重点,不知道 你看出来没有?
第二部,定义核心算子的基数推导规则
规则推导意思是说在当前子节点统计信息的基础上,计算父节点相关统计信息的一套推导规则。对于不同算子,推导规则必然不一 样,比如fliter、group by、limit等等的评估推导是不同的。这里以filter为例进行讲解。先来看看这样一个SQL:select * from A , C where A.id = C.c_id and C.c_id > N ,经过RBO之后的语法树如下图所示:
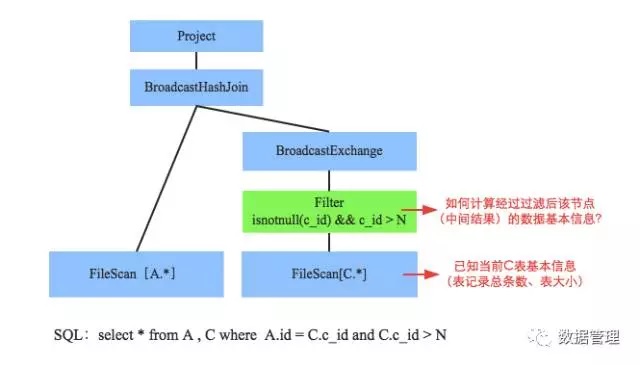
问题定义为:假如现在已经知道表C的基本统计信息(estimatedSize、rowCount、basicStats以及histograms),那么如何推导 出经过C.c_id>N过滤后中间结果的基本统计信息呢?让我们来看看:
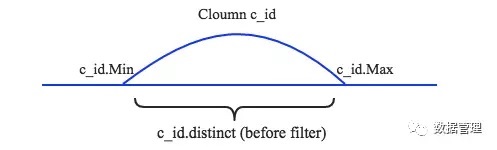
1. 假设已知C列的最小值c_id.Min、最大值c_id.Max以及总行数c_id.Distinct,同时假设数据分布均匀,如下图所示:
2. 现在分别有三种情况需要说明,其一是N小于c_id.Min,其二是N大于c_id.Max,其三是N介于c_id.Min和c_id.Max之间。前两 种场景是第三种场景的特殊情况,这里简单的针对第三种场景说明。如下图所示:
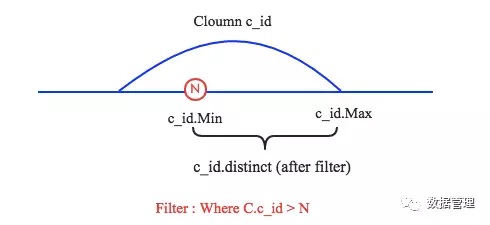
在C.c_id>N过滤条件下,c_id.Min会增大到N,c_id.Max保持不变。而过滤后总行数c_id.distinct(after_filter)=(c_id.Max– N)/(c_id.Max–c_id.Min)*c_id.distinct(before_filter)
简单吧,但是注意哈,上面计算是在假设数据分布均匀的前提下完成的,而实际场景中数据分布很显然不可能均衡。数据分布通常 成概率分布,histograms在这里就要登场了,说白了它就是一个柱状分布图,如下图:
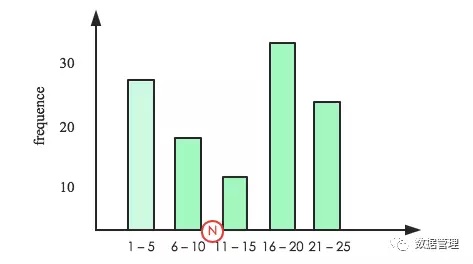
柱状图横坐标表示列值大小分布,纵坐标表示频率。假设N在如图所示位置,那过滤后总行数c_id.distinct(after_filter)= height(>N)/height(All)*c_id.distinct(before_filter)。
当然,上述所有计算都只是示意性计算,真实算法会复杂很多。另外,如果大家对group by 、limit等谓词的评估规则比较感兴趣 的话,可以阅读SparkSQL CBO的设计文档,这里就不再赘述。至此,通过各种评估规则以及原始表统计信息就可以计算出语法树 中所有中间节点的基本统计信息了,这是万里长征的第二步,也是至关重要的一步。接下来继续往前走,看看如何计算每种核心算 子的实际代价。
因为实现的原因设置的比较简单,有的会比较复杂。这一节主要来简单聊聊每个节点的执行代价,上文说了,一条执行路径的总代 价就是这条路径上所有节点的代价累加之和。
通常来讲,节点实际执行代价主要从两个维度来定义:CPU Cost以及IO Cost。为后续讲解方便起见,需要先行定义一些基本参数:
Hr:从HDFS上读取1byte数据所需代价
Hw:往HDFS上写入1byte数据所需代价
Tr:数据总条数(the number of tuples in the relation )
Tsz:数据平均大小(Average size of the tuple in the relation
)
CPUc : 两 值 比 较 所 需 CPU 资 源 代 价 ( CPU cost for a comparison in nano seconds )
NEt:1byte数据通过网络在集群节点间传输花费代价(the average cost of transferring 1 byte over network in the Hadoop cluster from any node to any node )
……
上文说过,每种算子的实际执行代价计算方式都不同,在此不可 能列举所有算子,就挑两个比较简单、容易理解的来分析,第一 个是Table Scan算子,第二个是Hash Join算子。
Table Scan算子 Scan算子一般位于语法树的叶子结点,直观上来讲这类算子只有IO Cost,CPU Cost为0。Table Scan Cost = IO Cost = Tr * Tsz * Hr,很简单,Tr * Tsz表示需要scan的数据总大小,再乘以Hr就是所需代价。OK,很直观,很简单。
Hash Join算子 以Broadcast Hash Join为例(如果看官对Broadcast Hash Join工作原理还不了解,可戳这里),假设大表分布在n个节点上,每 个 节 点 的 数 据 条 数 平 均 大 小 分 别 为 Tr(R1)Tsz(R1) , Tr(R2)Tsz(R2), … Tr(Rn)Tsz(Rn) , 小 表 数 据 条 数 为 Tr(Rsmall)Tsz(Rsmall),那么CPU代价和IO代价分别为:
CPU Cost = 小表构建Hash Table代价 + 大表探测代价 = Tr(Rsmall) * CPUc + (Tr(R1) + Tr(R2) + … + Tr(Rn)) * N * CPUc,此 处假设HashTable构建所需CPU资源远远高于两值简单比较代价,为N * CPUc
IO Cost = 小表scan代价 + 小表广播代价 + 大表scan代价 = Tr(Rsmall) * Tsz(Rsmall) * Hr + n * Tr(Rsmall) * Tsz(Rsmall) * NEt + (Tr(R1)* Tsz(R1) + … + Tr(Rn) * Tsz(Rn)) * Hr
很显然,Hash Join算子相比Table Scan算子来讲稍稍复杂了一点,但是无论哪种算子,代价计算都和参与的数据总条数、数据平 均大小等因素直接相关,这也就是为什么在之前两个步骤中要不懈余力地计算中间结果相关详细的真正原因。可谓是步步为营、环 环相扣。这下好了,任意节点的实际代价都能评估出来,那么给定任意执行路径的代价必然也就很简单喽。
第四步:选择最优执行路径(代价最小执行路径)
这个思路很容易理解的,经过上述三步的努力,可以很容易地计算出任意一条给定路径的代价。那么你只需要找出所有可行的执行 路径,一个一个计算,就必然能找到一个代价最小的,也就是最优的执行路径。
这条路看起来确实很简单,但实际做起来却并不那么容易,为什么?所有可行的执行路径实在太多,所有路径都计算一遍,黄花菜 都凉了。那么有什么好的解决方案么?当然,其实看到这个标题-选择代价最小执行路径,就应该很容易想到-动态规划,如果你 没有想到,那只能说明你没有读过《数学之美》、没刷过LeetCode、没玩过ACM,ACM、LeetCode如果觉得太枯燥,那就去看 看《数学之美》,它会告诉你从当前这个你所在的地方开车去北京,如何使用动态规划选择一条最短的路线。在此不再赘述。
至此,笔者粗线条地介绍了当前主流SQL引擎是如何将CBO这么一个看似高深的技术一步一步落地的。接下来,笔者将会借用 Hive、Impala这两大SQL引擎开启CBO之后的优化效果让大家对CBO有一个更直观的理解。
3 Hive-CBO优化效果
Hive本身没有去从头实现一个SQL优化器,而是借助于Apache Calcite,Calcite是一个开源的、基于CBO的企业级SQL查询优化框 架,目前包括Hive、Phoniex、Kylin以及Flink等项目都使用了Calcite作为其执行优化器,这也很好理解,执行优化器本来就可以 抽象成一个系统模块,并没有必要花费大量时间去重复造轮子。
hortonworks曾经对Hive的CBO特性做了相关的测试,测试结果认为CBO至少对查询有三个重要的影响:Join ordering optimization、Bushy join support以及Join simplification,本文只简单介绍一下Join ordering optimization,有兴趣的同学可 以继续阅读这篇文章(HIVE 0.14 Cost Based Optimizer (CBO) Technical Overview)来更多地了 解其他两个重要影响。(下面数据以及示意图也来自于该篇文章,特此注明)
select dt.d_year,
item.i_brand_id brand_id,
item.i_brand brand,
sum(ss_ext_sales_price) sum_agg from
date_dim dt, store_sales, item where
dt.d_date_sk = store_sales.ss_sold_date_sk and
store_sales.ss_item_sk = item.i_item_sk and
item.i_manufact_id =436 and dt.d_moy =12
group by dt.d_year , item.i_brand , item.i_brand_id
order by dt.d_year , sum_agg desc , brand_id limit 10
上述Query涉及到3张表,一张事实表store_sales(数据量大)和两张维度表(数据量小),三表之间的关系如下图所示:
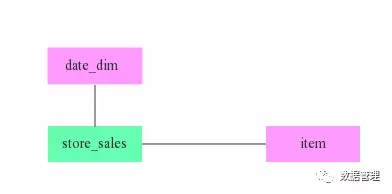
这里就涉及上文提到的Join顺序问题,从原始表来看,date_dime有73049条记录,而item有462000条记录。很显然,如果没有其 他暗示的话,Join顺序必然是store_sales join date_dim join item。但是,where条件中还带有两个条件,CBO会根据过滤条件对 过滤后的数据进行评估,结果如下:
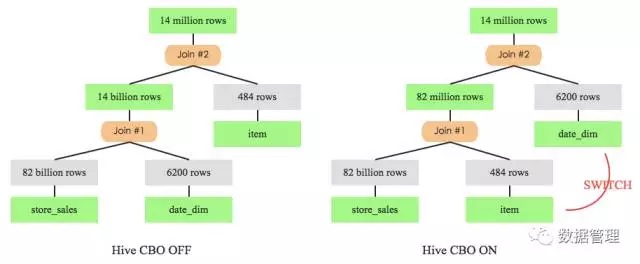
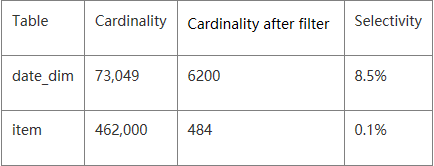
根据上表所示,过滤后的数据量item明显比date_dim小的多,剧情反转的有点快。于是乎,经过CBO之后Join顺序就变成了 store_sales join item join date_dim,为了进一步确认,可以在开启CBO前后分别记录该SQL的执行计划,如下图所示:
左图是未开启CBO特性时Q3的执行计划,store_sales先与date_dim进行join,join后的中间结果数据集有140亿条。而再看右图, store_sales先于item进行join,中间结果只有8200w条。很显然,后者执行效率会更高,实践出真知,来看看两者的实际执行时间:
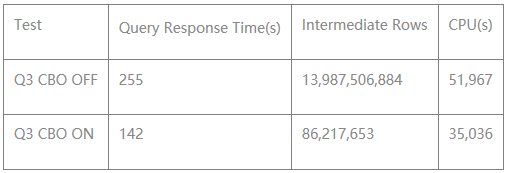
上图很明显的看出Q3在CBO的优化下性能将近提升了1倍,与此同时,CPU资源使用率也降低了一半左右。不得不说,TPCDS中有很多相似的Query,有兴趣的同学可以进一步深入的了解。
Impala-CBO优化效果
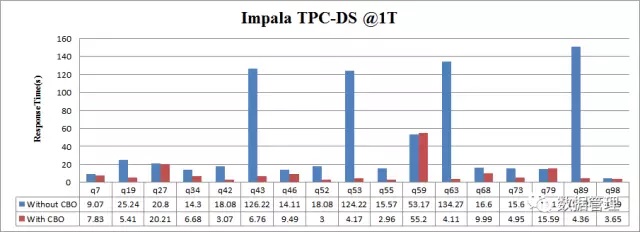
和Hive优化的原理相同,也是针对复杂join的执行顺序、Join的执行策略选择优化等方面进行的优化,本人使用TPC-DS对Impala 在开启CBO特性前后的部分Query进行了性能测试,测试结果如下图所示:
CBO总结
这篇文章其实很早就开始构思了,前前后后花了将近3个月时间断断续续来写,写了删、删了写,记得第二稿已经写了很多内容, 有天一大早醒来完完整整地看了一遍,发现写的东西并不是自己想要的,准确说,写的缺少那么一些些条理性,改又不好改,索性 就全删了。另一方面,也有因为当前网络上并没有太多关于CBO的完整介绍,倒是找到一些英文资料,但总感觉还是缺乏条理性, 很难理解。本文第一节重点从思维上带大家认识CBO,第二节更多的从实现的视角一步一步将整个原理粗线条地落地,第三节挑选 Hive与Impala两款产品对比介绍开启CBO之后的优化效果,使大家有一个更直观的感受。
好了,关于Join这个话题,洋洋洒洒前前后后写了三篇文章,能看到这里的只能说是真爱!说实话,笔者并没有完整的看过 RuntimeFilter的代码实现,也没有系统地学过任何一套CBO的代码实现,所写内容大体来自于三个方面:官方博客文档、分析理 解、撸起袖子实践。所以看官可要批判性地去阅读,有错误的地方在所难免,希望能够多多交流指正。后期笔者一定会阅读相关的 代码实现,有新的发现再和大家一起分享~
网易有数
企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。
点击这里---免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/