本文由 网易云 发布。
这篇博文主要的内容不是分析说明kudu的性能指标情况,而是分析为什么kudu的scan性能会这么龊!当初对外宣传可是加了各种 逆天黑科技的呀:列独立存储、bloom filter、压缩、原地修改、b+tree、mvcc ... ...
这里先贴个kudu和parquet小部分的TPCDS测试结果对比图吧:
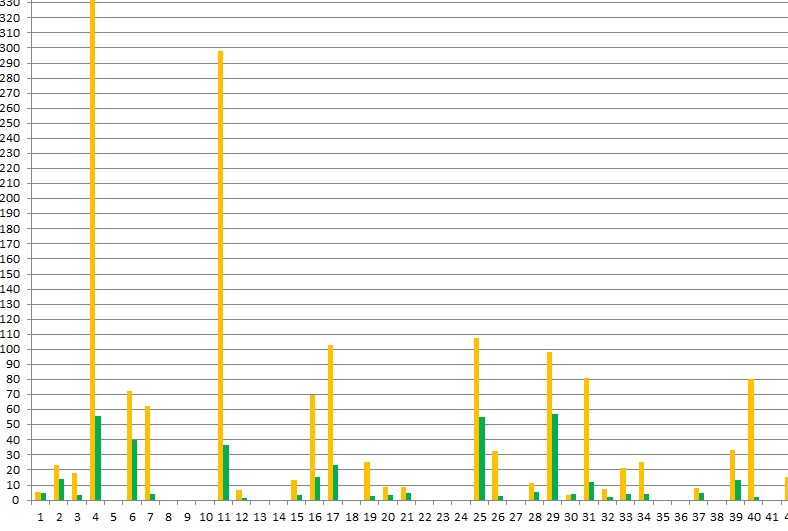
没有对比就没有伤害,有了对比就有了乐趣。纵坐标是耗时,单位是秒,代表kudu的黄色柱子太高了,说人话就是kudu耗时太 长,性能太差!
老大:为什么kudu性能会这么差? 本人:我不清楚 ... ...
当时真的不知道原因,前前后后忙着测试,急着获取测试指标,还来不及分析,何况还是两个陌生的大系统:impala和kudu,很 是尴尬:(
等到TPCDS测试用例全部跑完以后,有一个空档期,就花了几天时间来找原因,阅读资料、翻文档、google来google去,过程这 里不再叙述,下面着重描述下原因吧。
我们知道impala有个交互式的管理工具impala-shell,它有个profile命令,在每次执行完sql以后执行它,可以获取到这个sql的执 行计划及每个点的耗时统计。因为测试kudu和parquet,计算引擎都用的是impala,所以是不是可以从这里面获取些信息?
所以我就拿了上图中对比比较明显的query7和query40做试验,分别对kudu和parquet执行了一遍,搜集了它们各自的profile,总 共有4个文件,然后拿来分析。可能你不信,profile的结果实在是太大了,1个文件接近1万行,你还有信心分析么?(query40的 profile见底下附件)当时我是一脸懵逼样,没办法,原因总得找,所以硬着头皮从头到尾的阅读。无意间,手贱,点开了以前经常 用来比对代码的beyond compare,把执行query40的两个profile(kudu和parquet)比对了下,一点点往下拉,在执行计划这一 段,居然真发现了宝!
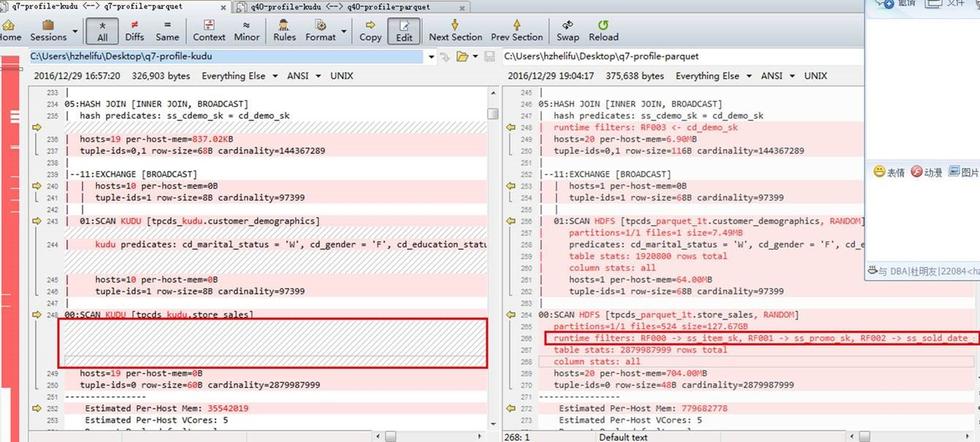
parquet有runtime filter,而kudu没有,接着往下拉,对应的磁盘scan部分:
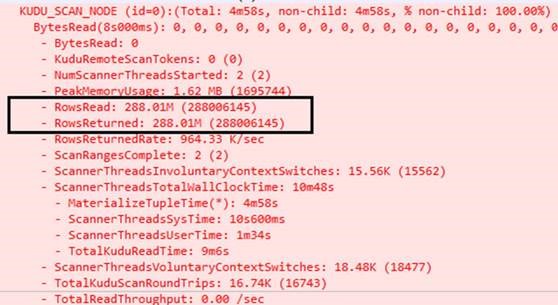
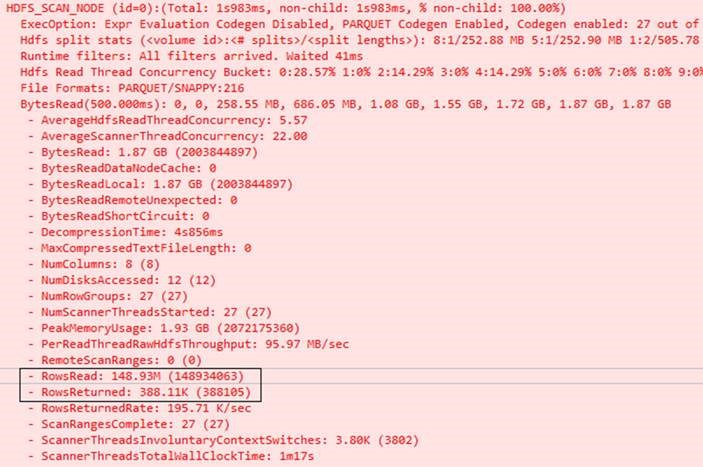
两者扫描磁盘获取的结果集也不一样了!!难怪在比较测试过程中,kudu集群跑query的时候会有大量的磁盘IO和网络传输开销, 而parquet负荷比较低!你看懂了么?
为什么kudu没有runtime filter?于是去kudu的jira库搜索,好吧,没找到!那试试impala的jira库呢,还真找到了,Matthew Jacobs是cloudera公司impala/kudu的开发工程师,找到他的两个jira单:impala-3741和impala-4252

+
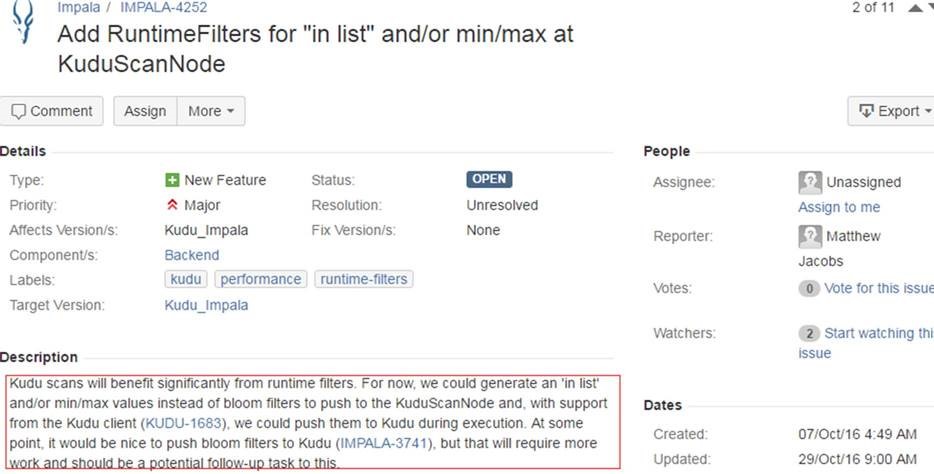
看到这里,基本上问题已经比较明确了,答案有了,可是我不甘心啊,于是不管三七二十一就注册了账号,在他们的jira库上提了 bug单:impala-4719(正常情况应该是在userlist发邮件咨询,那么就当我帮他们测试了jira库的权限问题了=_=),再次确认下 是否支持。
后来又重新去阅读了kudu的官方documents,字里行间其实已经有些端倪的,只不过当时没有引起足够的重视:
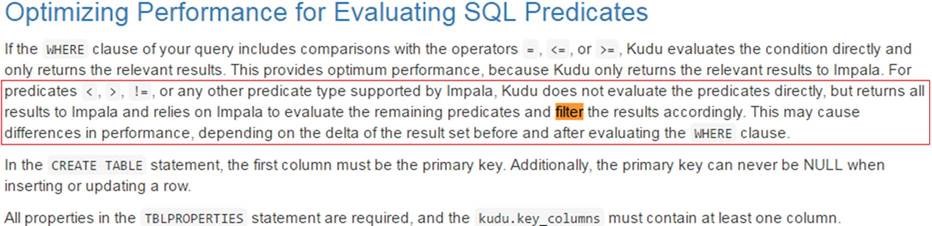
至此,本文结束。希望大伙儿能从中吸取到一点经验,谢谢!
网易有数
企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。
点击这里---免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/