前言
其实之前大家都了解过volatile,它的第一个作用是保证内存可见,第二个作用是禁止指令重排序。今天系统学习下为什么CPU会指令重排。
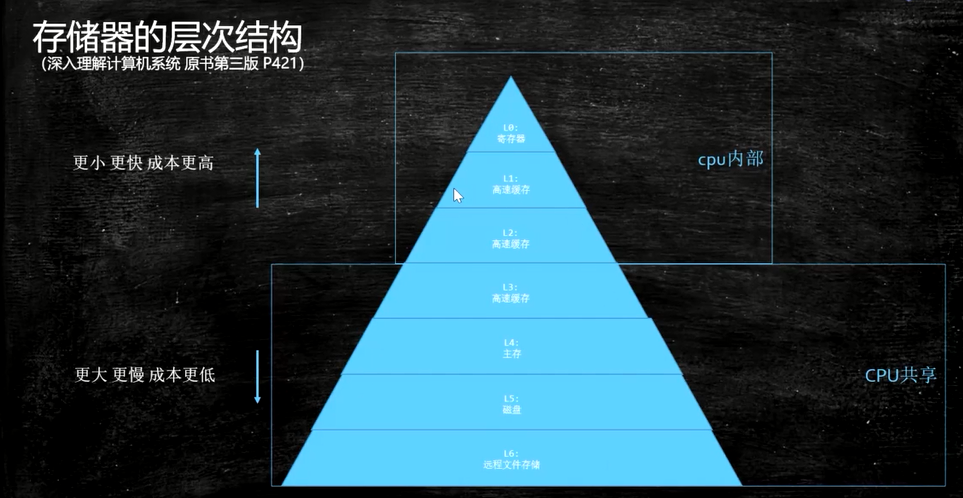
存储器的层次结构图
1.CPU乱序执行指令的根源
CPU读取数据的时候会先从离自己最近且速度最快的L1_cache高速缓存取数据,取不到就找L2_cache,还取不到,就读内存。
CPU如果一个cpu在执行的时候需要访问的内存都不在cache中,cpu必须要通过内存总线到主存中取,那么在数据返回到cpu这段时间内(这段时间cpu大致能够执行成百上千条指令的时间,至少两个数据量级)
在CPU看来,从内存读取数据的速度慢得接受不了,CPU得找点事做,那它干什么呢?
答案是cpu会继续执行其他的符合条件的指令。
比如cpu有一个指令序列【指令1 指令2 指令3 …】,在指令1时需要访问主存,在数据返回前cpu会继续后续的和指令1在逻辑关系上没有依赖的”独立指令”,cpu一般是依赖指令间的内存引用关系来判断的指令间的”独立关系”,具体细节可参见各cpu的文档。
这也是导致cpu乱序执行指令的根源之一。
2.CPU合并写(Write Combining)技术
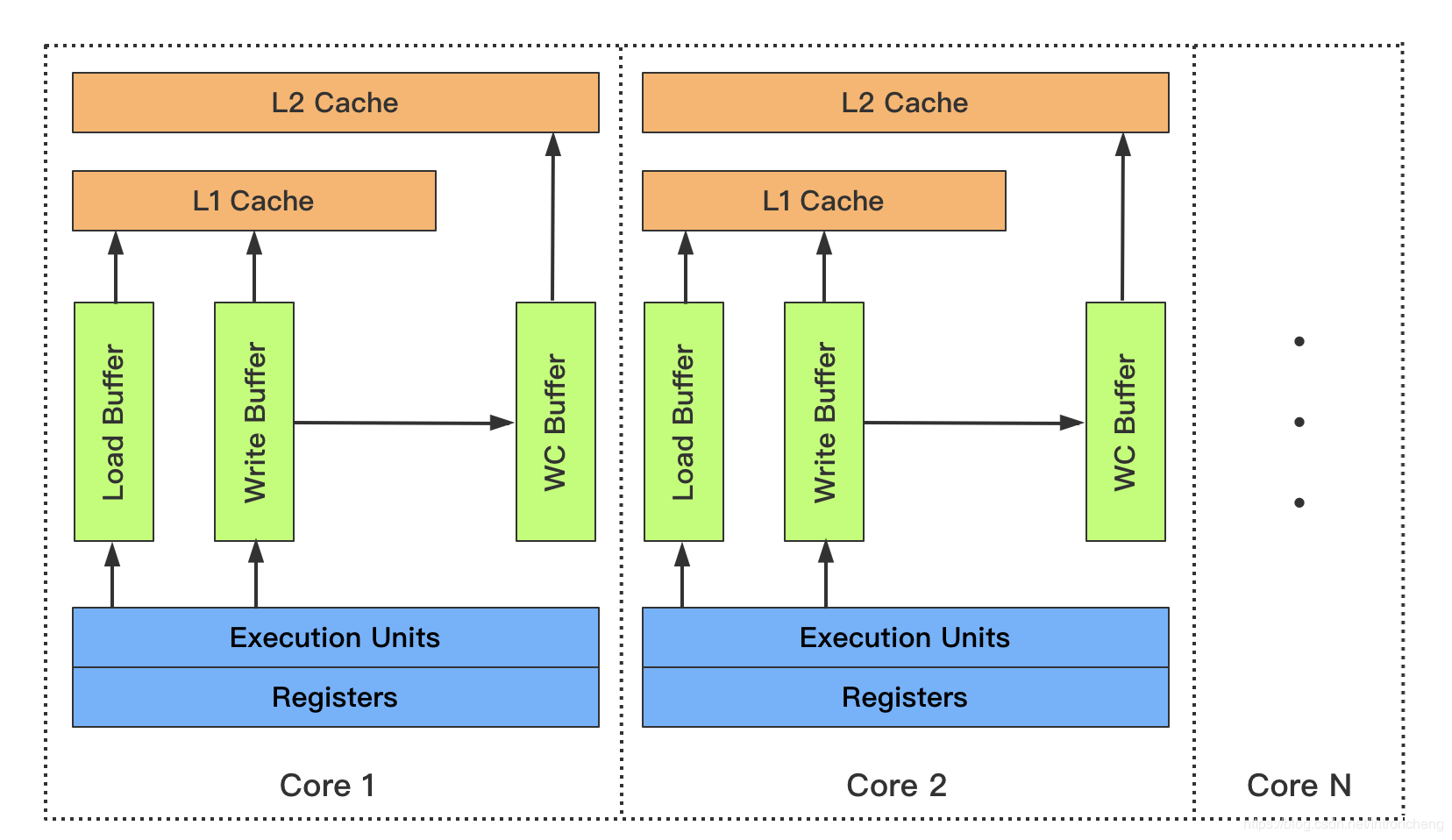
当cpu执行存储指令时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区。这一技术称为合并写入技术。
当CPU执行一个Store操作时,它将会把数据写到离CPU最近的L1_cache的数据缓存,如果这个时候发生Write miss, 则CPU将会去L2_cache缓存。
这个时候,Write Combining Buffer就来了,为了减少Write Miss带来的性能开销,Intel和其它很多型号的CPU都引入了Write Combining 技术。
Write Combining Buffer不是编程时内存里的Buffer,而是CPU里面真实的存储单元,是硬件。
当发生L1 Write Miss时,WC可以把多个对同一缓存行Store操作的数据放在WC中,在程序对相应缓存行(或者理解为这些数据)读之前先合并,等到需要读取时再一次性写入来减少写的次数和总线的压力。
此时,CPU可以在把数据放入WC后继续执行指令,减少了很多时钟周期的浪费。不同的CPU, WC的数量可能是不一样的。Intel的CPU中,其实只有4个WC可以真正被我们同时使用。
这几个Buffer非常有意思的是要求后续的写操作都要对同一缓存行进行写操作,这样后续的写操作才可以被放到一起提交到L2缓存。
WC缓冲区大小和一个cache line大小一致,一般都是64字节。
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24; //ITEMS == 16777216
private static final int MASK = ITEMS - 1;
//每个字节数组大小是16777216,保证每个数组的元素改变都不在同一个缓存行
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
/**
* 下面的代码一次性通过CPU写了7个缓存行:因为6个字节数组肯定占6个不同的缓存行,还有一个int的赋值。
* 一次性的WC缓冲区是装不下的,因为一个CPU只有4个WC缓冲区的位置。
* 因此它需要先写满前4个到WC buffer,满了,然后cpu需要暂停,等待WC刷到L2_cache里去,然后再写后3个
*/
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
/**
* 下面的代码一次性通过CPU写了4个缓存行:因为3个字节数组肯定占3个不同的缓存行。还有一个int的赋值。
* 因为byte b = (byte) i;可能占另外的缓存行
* 每循环一次WC就会刷到L2_cache上去,CPU暂停的时间就没那么多。
*/
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
}
执行结果:我电脑性能比较差,其他人一般是一半的时间差。
1 SingleLoop duration (ns) = 10489399305
1 SplitLoop duration (ns) = 7520512347
2 SingleLoop duration (ns) = 10046797497
2 SplitLoop duration (ns) = 7413160235
3 SingleLoop duration (ns) = 9980700466
3 SplitLoop duration (ns) = 8644205043
原理:
最开始,我看这个例子的时候:没有理得非常清楚,还是懵懵懂懂的。
后面自己想了很久很久,时间无限放大后runCaseOne的执行流程应该是这样的:
step1:CPU收到6条指令,在一个循环内。分别把arrayA,BCDEF的某个位置写为b。
step2:CPU给arrayA执行写操作,准备把它设置为b
step3:CPU查询L1_cache是否有缓存行,发现没有。申请L2_cache的缓存行权限【请求L2缓存行的所有权】,申请的过程比较慢,CPU在此期间是有能力执行很多其他指令的
step4:CPU把写操作arrayA[slot] = b;写到WC buffer中,这个时候WC Buffer使用了一个,总共四个。L2_cache的申请结果还没有来。
step5:CPU把写操作arrayB[slot] = b;arrayC[slot] = b;arrayD[slot] = b;都写进了WC Buffer。这个时候申请还没来。但是此时WC buffer已经使用4个,总共4个。
step6:没办法,CPU必须等待了。
经过上述步骤后,WC缓冲区的数据还是会在某个延时的时刻更新到外部的缓存(L2_cache).如果我们能在WC缓冲区传输到缓存之前将其尽可能填满,这样的效果就会提高各级传输总线的效率,以提高程序性能。
step7:L2申请下来了,WC的缓冲区4个数据能刷给L2了
step8:然后CPU继续执行下面的写操作
runCaseTwo函数中是每次写入4个不同位置的内存,可以很好的利用合并写缓冲区,因合并写缓冲区满到引起的cpu暂停的次数会大大减少,当然如果每次写入的内存位置数目小于4,也是一样的。
下面是其他文章的分析:
上面提到的合并写存入缓冲区离cpu很近,容量为64字节,很小了,估计很贵。数量也是有限的,一般都是4个WC缓冲,每个64字节。WC缓冲个数(4个)是依赖cpu模型的,intel的cpu在同一时刻只能拿到4个。
因此,runCaseOne函数中连续写入7个不同位置的内存,那么当4个数据写满了合并写缓冲时,cpu就要等待合并写缓冲区更新到L2cache中,因此cpu就被强制暂停了。然而在runCaseTwo函数中是每次写入4个不同位置的内存,可以很好的利用合并写缓冲区,因合并写缓冲区满到引起的cpu暂停的次数会大大减少,当然如果每次写入的内存位置数目小于4,也是一样的。虽然多了一次循环的i++操作(实际上你可能会问,--i也是会写入内存的啊,其实i这个变量保存在了寄存器上), 但是它们之间的性能差距依然非常大。
当CPU执行存储指令(store)时,它会尝试将数据写到离CPU最近的L1缓存。如果此时出现缓存未命中,CPU会访问下一级缓存。此时,无论是英特尔还是许多其它厂商的CPU都会使用一种称为“合并写(write combining)”的技术。
在请求L2缓存行的所有权尚未完成时,待存储的数据被写到处理器自身的众多跟缓存行一样大小的存储缓冲区之一。这些芯片上的缓冲区允许CPU在缓存子系统准备好接收和处理数据时继续执行指令。当数据不在任何其它级别的缓存中时,将获得最大的优势。
当后续的写操作需要修改相同的缓存行时,这些缓冲区变得非常有趣。在将后续的写操作提交到L2缓存之前,可以进行缓冲区写合并。 这些64字节的缓冲区维护了一个64位的字段,每更新一个字节就会设置对应的位,来表示将缓冲区交换到外部缓存时哪些数据是有效的。
这些缓冲区的数量是有限的,且随CPU模型而异。例如在Intel CPU中,同一时刻只能拿到4个。这意味着,在一个循环中,你不应该同时写超过4个不同的内存位置,否则你将不能享受到合并写(write combining)的好处。
从上面的例子可以看出,这些cpu底层特性对程序员并不是透明的。程序的稍微改变会带来显著的性能提升。对于存储密集型的程序,更应当考虑到此到特性。
3.CPU乱序执行的Java证明
下面程序如果run()方法内的指令没有重排序的话,x和y的值可能为如下三种:
x=0 y=1
x=1 y=0
x=1 y=1
一旦程序停止并输出了结果,说明指令重排了。
public class T04_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b =0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for(;;) {
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.
//shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();other.start();
one.join();other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
//System.out.println(result);
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}
执行结果:每个机器都肯定会遇到程序结束,时间问题。结果如下图

4.CPU级别(汇编级别)的有序性保障
硬件层面的内存屏障(Intel x86)
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令(windows的虚拟机直接偷懒使用lock汇编指令,不知道说得对不对)
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
5.JVM对屏障的规范
JVM级别如何规范(JSR133)
可以参考Doug Lea的文章:The JSR-133 Cookbook for Compiler Writers
LoadLoadBarrier:
对于这样的语句Load1; LoadLoadBarrier; Load2,
在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStoreBarrier:
对于这样的语句Store1; StoreStoreBarrier; Store2,
在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStoreBarrier:
对于这样的语句Load1; LoadStoreBarrier; Store2,
在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoadBarrier:
对于这样的语句Store1; StoreLoadBarrier; Load2,
在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
6.volatile的实现细节
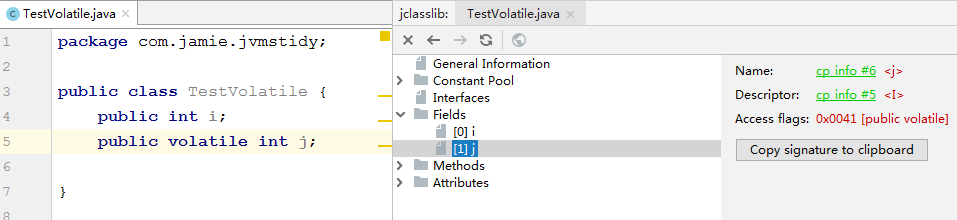
6.1 字节码层面
编译之后,会发现字节码文件在j变量前加了“ACC_VOLATILE”标记
6.2 JVM层面
volatile的底层实现是通过插入内存屏障,但是对于编译器来说,发现一个最优布置来最小化插入内存屏障的总数几乎是不可能的,所以,JMM采用了保守策略。如下:
在每一个volatile写操作前面插入一个StoreStoreBarrier
在每一个volatile写操作后面插入一个StoreLoadBarrier
在每一个volatile读操作后面插入一个LoadLoadBarrier
在每一个volatile读操作后面插入一个LoadStoreBarrier
StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作都已经刷新到主内存中。
StoreLoad屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。
LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。
LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。

6.3 OS和硬件层面
windows的volatile实现:采用lock汇编指令操作,lock add dword ptr [rsp],0h
linux的volatile实现:暂时就不知道了,有可能就是LFENCE、SFENCE、MFENCE等指令了
参考 五月的仓颉的文章:
反复思考IA-32手册对lock指令作用的这几段描述,可以得出lock指令的几个作用:
锁总线,其它CPU对内存的读写请求都会被阻塞,直到锁释放,不过实际后来的处理器都采用锁缓存替代锁总线,因为锁总线的开销比较大,锁总线期间其他CPU没法访问内存
lock后的写操作会回写已修改的数据,同时让其它CPU相关缓存行失效,从而重新从主存中加载最新的数据
不是内存屏障却能完成类似内存屏障的功能,阻止屏障两遍的指令重排序
所以为什么volatile可以实现禁止重排和内存可见呢?完全就是这里的根本原因。
7.synchronized实现细节
7.1 字节码层面
synchronized修饰方法时:
方法上加ACC_SYNCHRONIZED flag
synchronized同步块:
monitorenter
monitorexit

7.2 JVM层面
c/c++调用了操作系统的同步机制.
JVM规范中描述:每个对象有一个监视器锁(monitor)。
当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1.
3.如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
Synchronized的语义底层是通过一个monitor的对象来完成,其实wait/notify等方法也依赖于monitor对象,
这就是为什么只有在同步的块或者方法中才能调用wait/notify等方法,否则会抛出java.lang.IllegalMonitorStateException的异常的原因。
Synchronized是通过对象内部的一个叫做监视器锁(monitor)来实现的。
7.3 OS和硬件层面
但是监视器锁本质又是依赖于底层的操作系统的互斥锁(Mutex Lock)来实现的。而操作系统实现线程之间的切换这就需要从用户态转换到核心态,这个成本非常高,状态之间的转换需要相对比较长的时间,这就是为什么synchronized效率低的原因。
因此,这种依赖于操作系统互斥锁(Mutex Lock)所实现的锁我们称之为“重量级锁”。
我还不确定是在synchronized优化后会不会存在这样的问题,需要后续详细学习并发的时候再研究了。
可以参考这篇文章了解优化原理:Java中Synchronized的优化原理
X86的synchronized底层汇编语言: lock cmpxchg / xxx
在x86架构上,CAS被翻译为"lock cmpxchg..."
可以参考锁&锁与指令原子操作的关系 & cas_Queue
锁的深入知识需要自己后续详细学习并发的时候再研究了。
参考汇总
现代cpu的合并写技术对程序的影响
合并写(write combining)
五月的仓颉_就是要你懂Java中volatile关键字实现原理
Java中Synchronized的优化原理
锁&锁与指令原子操作的关系 & cas_Queue
Java使用字节码和汇编语言同步分析volatile,synchronized的底层实现
Doug Lea的文章:
The JSR-133 Cookbook for Compiler Writers