树蛙<del>数据挖掘<del>作业,看见Kaggle上有许多优秀的kernel,准备学习一波
先占个坑
最近ddl有点多,Kaggle这个比赛我打了三天就不打了,最后结果前4%。用了之前数据挖掘比赛中学到的不少方法,但是也有一些想法因为时间原因自己没有实现(主要是data mining)。这里先放一个我的技术说明文档吧,后面贴代码。
1.结果说明

2.技术方案
2.1数据清洗
- 剔除离群点,如在
GrLivArea中占地面积小,但是售价高的数据。 - 填写缺失值,根据每列的实际情况,将缺失值填写。
- 标签编码,使用
LabelEncoder将字符串类别特征转化为数字类别特征
2.2特征工程
- 首先,将需要预测的
SalePrice列,使用ln(1+x)使其值符合正态分布,更有利于模型结果预测 - 然后,使用同样的方法,对数值特征转化。对于偏度大于0.5的数值特征使其转化为更符合正态分布。
- 将数值特征转化为类别特征(增加特征)。比如有无二楼,泳池等。
- 使用
get_dummies函数,将类别向量化,大量增加特征 曾试图PCA但是效果不好- (不重要特征剔除)使用gbdt、xgb、lgb先使用数据训练一波,然后提出这三个模型认为不重要的后50个特征
2.3模型融合
- 主要使用了以下模型
- Lasso、ElasticNet、KernelRidge、gbdt、xgb、lgb
- 然后使用Lasso、ElasticNet、KernelRidge、gbdt这四个模型,用
StackingCVRegressor函数作模型融合 - 使用xgb、lgb分别预测
- 然后将函数作的模型融合结果和xgb、lgb结果以0.7、0.15、0.15的比例加权平均。
- 压缩最终结果,将最低值和最高值往平均靠拢。
- 提交最终结果
3.python代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from scipy.stats import norm, skew, boxcox_normmax
import warnings
from sklearn import decomposition
from scipy.special import boxcox1p
warnings.filterwarnings('ignore')
pd.set_option('display.float_format', lambda x: '{:.3f}'.format(x))
train = pd.read_csv('../data/train.csv')
test = pd.read_csv('../data/test.csv')
print("The train data size before dropping Id feature is : {} ".format(train.shape))
print("The test data size before dropping Id feature is : {} ".format(test.shape))
train_ID = train.pop('Id')
test_ID = test.pop('Id')
train = train.drop(train[(train['GrLivArea'] > 4000) & (train['SalePrice'] < 300000)].index)
# We use the numpy fuction log1p which applies log(1+x) to all elements of the column
train["SalePrice"] = np.log1p(train["SalePrice"])
# 据说正态分布更适合预测?
# 将预测的结果取对数,看起来更符合正态分布
# concat一起,方便之后的数据处理(一个函数,两组数据)
ntrain = train.shape[0]
ntest = test.shape[0]
y_train = train.SalePrice.values
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape))
all_data["PoolQC"] = all_data["PoolQC"].fillna("None")
all_data["MiscFeature"] = all_data["MiscFeature"].fillna("None")
all_data["Alley"] = all_data["Alley"].fillna("None")
all_data["Fence"] = all_data["Fence"].fillna("None")
all_data["FireplaceQu"] = all_data["FireplaceQu"].fillna("None")
# 与物业相连的街道的英尺数,缺失值用均值代替
all_data["LotFrontage"] = all_data.groupby("Neighborhood")["LotFrontage"].transform(lambda x: x.fillna(x.median()))
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond'):
all_data[col] = all_data[col].fillna('None')
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col] = all_data[col].fillna(0)
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[col] = all_data[col].fillna(0)
for col in ('BsmtQual', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2'):
all_data[col] = all_data[col].fillna('None')
all_data["MasVnrType"] = all_data["MasVnrType"].fillna("None")
all_data["MasVnrArea"] = all_data["MasVnrArea"].fillna(0)
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])
all_data = all_data.drop(['Utilities'], axis=1)
# new drop
all_data = all_data.drop(['Street'], axis=1)
all_data["Functional"] = all_data["Functional"].fillna("Typ")
# Electrical 这个设置有点草率,设置了一个mostly,但是是one
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
# one NA value
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
# one NA value
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
# file with most “WD”
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
all_data['MSSubClass'] = all_data['MSSubClass'].fillna("None")
all_data['MSSubClass'] = all_data['MSSubClass'].apply(str)
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond', 'HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
'''
cols = ('Alley', 'BldgType', 'BsmtCond', 'BsmtExposure', 'BsmtFinType1', 'BsmtFinType2', 'BsmtQual',
'CentralAir', 'Condition1', 'Condition2', 'Electrical', 'ExterCond', 'ExterQual',
'Exterior1st', 'Exterior2nd', 'Fence', 'FireplaceQu', 'Foundation', 'Functional',
'GarageCond', 'GarageFinish', 'GarageQual', 'GarageType', 'Heating', 'HeatingQC',
'HouseStyle', 'KitchenQual', 'LandContour', 'LandSlope', 'LotConfig', 'LotShape',
'MSZoning', 'MasVnrType', 'MiscFeature', 'Neighborhood', 'PoolQC', 'RoofMatl',
'RoofStyle', 'SaleCondition', 'SaleType', 'PavedDrive')
'''
# 将类别特征转化为数值表示
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(all_data[c].values))
all_data[c] = lbl.transform(list(all_data[c].values))
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']
# 计算数据的偏度,正态函数偏度为0,对称
skewed_feats = all_data[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
skewness = pd.DataFrame({'Skew': skewed_feats})
skewness = skewness[abs(skewness) > 0.5]
print(skewness.shape[0])
skewed_features = skewness.index
# lam = 0.15
for feat in skewed_features:
# lam = boxcox_normmax() # find best lambda
lam = boxcox_normmax(all_data[feat] + 1)
if lam > 0.2:
lam = 0.2
all_data[feat] = boxcox1p(all_data[feat], lam)
all_data['haspool'] = all_data['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
all_data['has2ndfloor'] = all_data['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
all_data['hasgarage'] = all_data['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
all_data['hasbsmt'] = all_data['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)
all_data['hasfireplace'] = all_data['Fireplaces'].apply(lambda x: 1 if x > 0 else 0)
all_data = pd.get_dummies(all_data)
print(all_data.shape)
pca = decomposition.PCA()
train = all_data[:ntrain].values
test = all_data[ntrain:].values
# pca.fit(train)
# train = pca.transform(train)
# test = pca.transform(test)
# model begin ====================================================================== #
from sklearn.linear_model import ElasticNetCV, LassoCV, RidgeCV
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import mean_squared_error
from mlxtend.regressor import StackingCVRegressor
import xgboost as xgb
import lightgbm as lgb
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train)
mse = np.sqrt(-cross_val_score(model, train, y_train, scoring="neg_mean_squared_error", cv=kf))
return mse
kfolds = KFold(n_splits=n_folds, shuffle=True, random_state=42)
alph = [0.01, 0.001, 0.0001, 0.0002, 0.0004, 0.0008, 0.002, 0.004, 0.008, 1, 2, 4, 6, 8, 10, 12]
alph2 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
lasso = make_pipeline(RobustScaler(), LassoCV(alphas=alph, cv=kfolds, random_state=1))
ENet = make_pipeline(RobustScaler(), ElasticNetCV(alphas=alph, l1_ratio=.9, cv=kfolds, random_state=3))
ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alph2, cv=kfolds))
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state=5)
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=3,
min_child_weight=2, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=True,
random_state=7, nthread=-1)
model_lgb = lgb.LGBMRegressor(objective='regression', num_leaves=5,
learning_rate=0.05, n_estimators=720,
max_bin=55, bagging_fraction=0.8,
bagging_freq=5, feature_fraction=0.2319,
feature_fraction_seed=9, bagging_seed=9,
min_data_in_leaf=6, min_sum_hessian_in_leaf=11)
stacked_averaged_models = StackingCVRegressor(regressors=(ENet, GBoost, KRR),
meta_regressor=lasso,
use_features_in_secondary=True)
# stacked_averaged_models = StackingCVRegressor(regressors=(ridge, lasso, ENet, GBoost, model_xgb, model_lgb),
# meta_regressor=model_lgb,
# use_features_in_secondary=True)
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))
# stacked_averaged_models.fit(train.values, y_train)
# stacked_train_pred = stacked_averaged_models.predict(train.values)
# stacked_pred = np.expm1(stacked_averaged_models.predict(test.values))
# 下一步,更改融合方式
model_xgb.fit(train, y_train)
xgb_train_pred = model_xgb.predict(train)
xgb_importance = model_xgb.feature_importances_
xgb_out = np.argsort(xgb_importance)
print(rmsle(y_train, xgb_train_pred))
model_lgb.fit(train, y_train)
# save all models feature importance and drop the bad feature
# 给特征排序,然后删除无用特征
# lgb.plot_importance(model_lgb, max_num_features=30)
# plt.show()
booster = model_lgb.booster_
lgb_importance = booster.feature_importance(importance_type='split')
lgb_out = np.argsort(lgb_importance)
lgb_train_pred = model_lgb.predict(train)
print(rmsle(y_train, lgb_train_pred))
print('RMSLE score on train data:')
# lasso.fit(train, y_train)
# lasso_train_pred = lasso.predict(train)
# lasso_pred = np.expm1(lasso.predict(test))
GBoost.fit(train, y_train)
GBoost_train_pred = GBoost.predict(train)
GBT_feature = GBoost.feature_importances_
gbt_out = np.argsort(GBT_feature)
drop_num = 50
lgb_out = lgb_out[:drop_num]
xgb_out = xgb_out[:drop_num]
gbt_out = gbt_out[:drop_num]
# drop_feature = [val for val in lgb_out if (val in xgb_out and val in gbt_out)]
drop_feature = list(set(lgb_out).union(xgb_out).union(gbt_out))
print(drop_feature)
train = np.delete(train, drop_feature, axis=1)
test = np.delete(test, drop_feature, axis=1)
# ========================================== pred ===================================#
stacked_averaged_models.fit(train, y_train)
stacked_train_pred = stacked_averaged_models.predict(train)
stacked_pred = np.expm1(stacked_averaged_models.predict(test))
print(rmsle(y_train, stacked_train_pred))
model_lgb.fit(train, y_train)
model_xgb.fit(train, y_train)
xgb_pred = np.expm1(model_xgb.predict(test))
# GBoost_pred = np.expm1(GBoost.predict(test))
lgb_pred = np.expm1(model_lgb.predict(test))
print(rmsle(y_train, stacked_train_pred * 0.7 + xgb_train_pred * 0.15 + lgb_train_pred * 0.15))
ensemble = stacked_pred * 0.7 + xgb_pred * 0.15 + lgb_pred * 0.15
submission = pd.DataFrame()
submission['Id'] = test_ID
submission['SalePrice'] = ensemble
q1 = submission['SalePrice'].quantile(0.005)
q2 = submission['SalePrice'].quantile(0.995)
submission['SalePrice'] = submission['SalePrice'].apply(lambda x: x if x > q1 else x * 0.85)
submission['SalePrice'] = submission['SalePrice'].apply(lambda x: x if x < q2 else x * 1.1)
submission.to_csv('../result/submission1.csv', index=False)
注意代码中的这两行:
train = pd.read_csv('../data/train.csv')
test = pd.read_csv('../data/test.csv')
submission.to_csv('../result/submission1.csv', index=False)
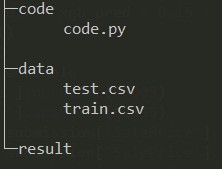
确保输入输出文件路径正确,文件结构概图如下:
惊闻吴亦凡大碗宽面出新歌了,暂且不说歌唱的怎么样,先给吴亦凡的态度赞一个,不在乎别人黑自己,反而以此自嘲,确实真男人。