去哪儿 Hadoop 集群 Federation 数据拷贝优化
背景
去哪儿 Hadoop 集群随着去哪儿网的发展一直在优化改进,基本保证了业务数据存储量和计算量爆发式增长下的存储服务质量。然而,随着集群规模的发展,单组 NameNode 组成的集群也到达了新的瓶颈:因为 NameNode 内存使用和元数据量正相关,在 180GB 堆内存配置下,元数据量红线约为 7 亿,而随着集群规模和业务的发展,即使经过小文件合并与数据压缩,仍然无法阻止元数据量逐渐接近红线。而且在性能方面,随着业务的发展,集群规模的扩大,NameNode RPC 响应时间增大,QPS 逐渐降低。
HDFS Federation 是 Hadoop-0.23.0 中为解决 HDFS 单点限制而提出的 NameNode 水平扩展方案。该方案可以为 HDFS 服务创建多个 NameSpace ,从而提高集群的扩展性和隔离性,分散单个 NameNode 的负载。(在 HDFS 中 NameSpace 是指 NameNode 中负责管理文件系统中的树状目录结构以及文件与数据块的映射关系的一层逻辑结构,在 Federation 方案中,NameNode 之间相互隔离,因此社区也用一个 NameSpace 来指代 Federation 中一组独立的 NameNode 及其元数据。)
在 Federation 过程中,非常重要的一个环节就是数据的拷贝。
原来所有的数据都是从源主节点 NameNode1 下访问,例如 /user/flight,/user/hotel 等。 如果 Federation 后,/user/flight 从 NameNode1 访问,/user/hotel 从 NameNode2 访问,这样就需要将 /user/hotel 目录下所有的数据和元数据拷贝到 NameNode2 的集群中。
fastcopy 简介
如果集群数据比较少,可以直接 distcp 完成。
现在去哪儿网的数据,单个 DataNode 的使用占比中位数已经超过 80%,即,要拷贝出 70% 的数据的话,不考虑时间,磁盘空间也满足不了要求。 如果拆成多次操作,周期和运维成本会高出很多。
所以选择了社区中的 fastcopy 方案, https://issues.apache.org/jira/browse/HDFS-2139 ,FastCopy 是 Facebook 开源的数据拷贝方案。主要逻辑就是,从源 NameNode 读文件信息和 block 对应关系,然后在目标 NameNode 上创建文件,添加 block ,拷贝 block 。 其中拷贝 block 的方式(最终数据块的拷贝)是使用 linux 的硬链拷贝来完成,这样就不会增加存储成本了。
fastcopy 的优点,速度快,不占存储空间。也有缺点,是没有进行文件权限和属主的拷贝,还需要再次修改,这个权属从源 NameNode 也需要读所有的文件,然后写到目标 NameNode 去,这个时间基本是拷贝时间的 1/3 到 1/2 。
fastcopy 与 distcp 测试对比
为了更直观的了解 fastcopy 的性能,我们先测试了 fastcopy 和 distcp 的比较。
测试集群环境: 2 个 NameSpace,50 个 DataNode。
测试结果
元数据量从 100 万到 1 亿,fastcopy 花费时间从 0.68 分钟到 90 分钟,distcp 从 5m 到 830m。
元数据总量与拷贝时间折线图:
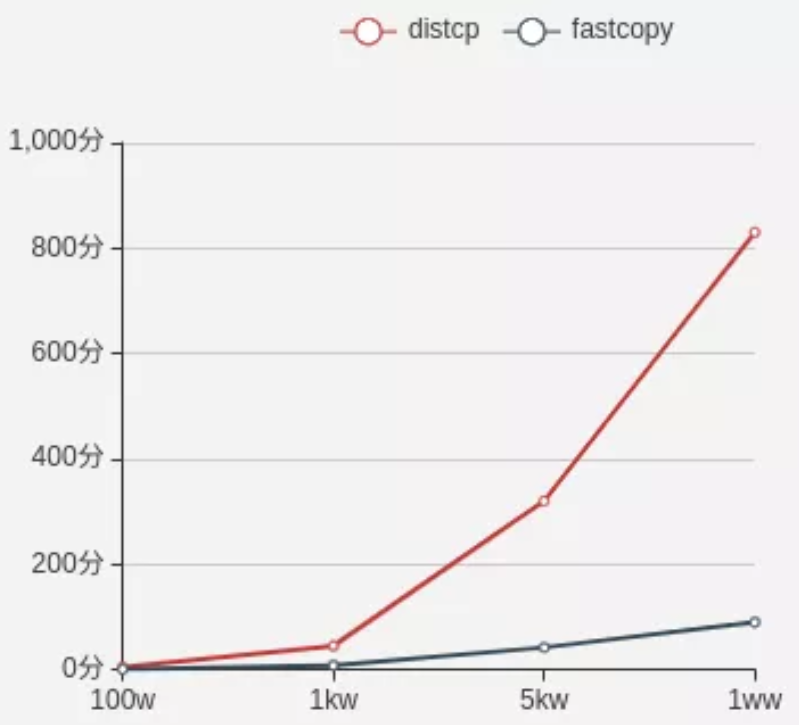
测试分析结论
根据测试结果,生产集群拷贝 5 亿元数据:
distcp 需要花费为 4 天。如果开用 distcp ,公司集群停用 4 天,业务报表统计、业务模型训练等都不可用,这是不可接受的,此方案不通。
fastcopy 需要花费 90*5/60*1.8=13.5 个小时,1.8 为一个系数,表示元数据增大到 7 亿后响应时间增大的程度。fastcopy 拷贝后,还需要对原文件的权限属主进行设置,也需要 6 个小时左右,最终 fastcopy 需要 20 个小时左右,对公司的报表等影响很大。
测试过程中,我们发现 fastcopy 的瓶颈是 active 主节点的并发度。在阅读 fastcopy 源码的过程中,我们发现 fastcopy 对同一个元数据有多次请求。我们准备从这点开始对源码优化。
fastcopy 优化
fastcopy 适用范围较宽,在 Federation 集群中任何一个时间节点都可以使用。
而我们现在面临的是单 NameNode 拆分多个 NameNode 时大量数据迁移时间过长问题。拆分时刻可以停止集群写服务,提前创建 Snapshot ,保证 fsimage 不变,在此前提下我们进行优化。
优化后的 fastcopy 简称 qfastcopy 。
原 fastcopy 流程以及步骤
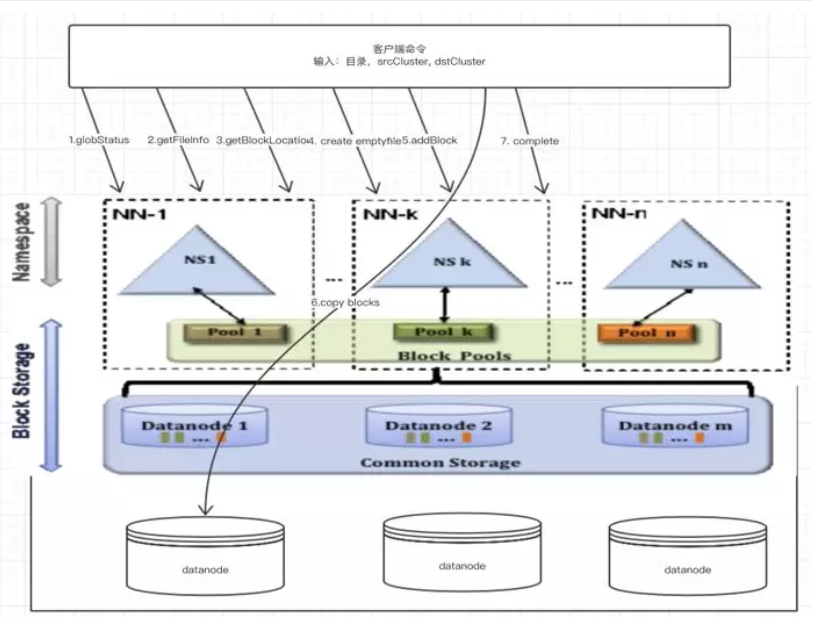

原 fastcopy 步骤所需资源与性能分析

优化方案

qfastcopy
qfastcopy 流程:
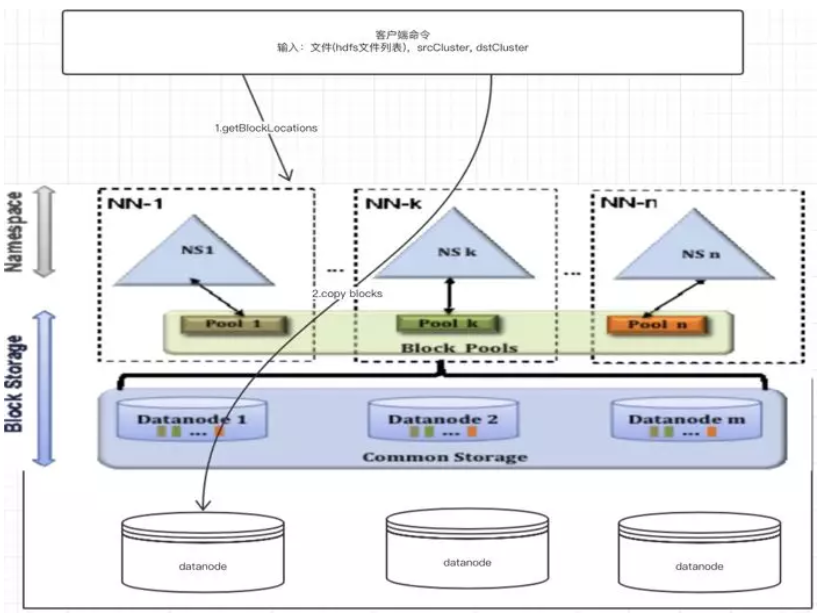
qfastcopy 具体步骤:

qfastcopy 的缺点
-
使用场景单一,只能在 Federation 过程中 NameNode 拆分时使用,需要提前 copy fsimage 到目标集群。
-
目标文件与源文件绝对路径相同。
-
整个流程中集群不能对外提供写操作。
qfastcopy 测试
fastcopy 和 qfastcopy 对比
元数据量与拷贝时间折线图:
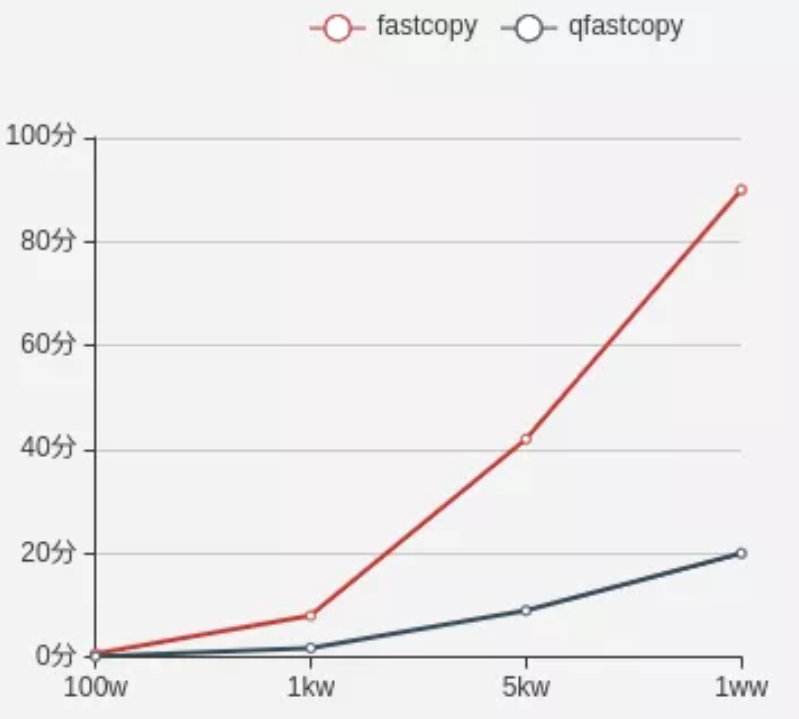
分析与结论
根据测试结果,生产集群拷贝 5 亿元数据,qfastcopy 需要花费 22*5/60*1.8=3.5 小时。
最终,我们将近集群 Federation 的 5 亿元数据拷贝时间从 20 小时优化到了 3.5 小时。