一个标准的监控系统所具备的基本功能:
3.万一某次采样的结果不在被认为是合理的范围内,然后就会做出告警操作,尽早的让相关人员得知到此消息
系统指标:CPU,memery,IO(Disk,Network)
1.CPU:sys(消耗在系统空间的比例),usr(用户空间的比例),idle(空闲的比例),,,等
2.memery:total(总大小),userd(已用空间大小),free(空闲大小),cached(放在缓存的大小),buffer,shm(共享内存的大小),,,等
系统一旦起来,会运行很多进程,对进程而言,他有多少个,他的变化量,处于运行状态的,处于睡眠状态的,处于僵死状态的等,,,这些又是指标
业务指标:比如:对于nginx服务,假如说nginx也算是一个进程,他时而处于运行状态,时而处于睡眠状态,对于nginx本身来说,他每秒接受的请求数量,每秒处理的请求数量等,这些可以理解为业务指标。
数据采集
1.ssh接口(监控中最为简单的方式)
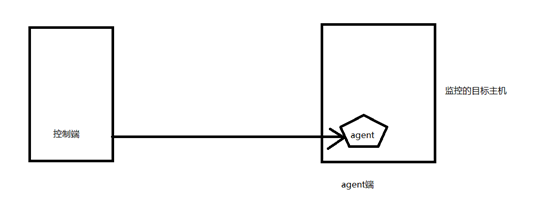
我们要监控的某个特定主机的某一项指标,如果这项指标是核心而敏感的数据,普通用户是不具有权限的,要想获取到核心的数据,就要以管理员的身份来运行,可以用ssh账号远程连接认证来连接到监控的主机上,从而获取到核心的数据,来实现管理。
在监控的目标主机上运行一个进程,这个进程可以与其控制端通过非系统的认证逻辑来进行认证,即便用户获得了认证的信息,也不能获得系统级权限。通过了认证后,控制端就会只会agent端做出一些操作,如果agent端以管理员身份来运行,就能在目标主机上获得设计者设计的权限。
3.英特尔智慧平台接口
一些专业的服务器也可以不依赖于操作系统提供的系统级接口来监控,就算没装操作系统,也可以获取该主机的CPU,memery,IO用量,这种方式依赖硬件级的接口,英特尔智慧平台接口
4.jmx接口
在jvm虚拟机上有一个jmx接口,通过这个接口来获取数据指标,来完成监控
趋势数据:按照固定的时间长度做聚合运算后仅保留有限数据项的数据
假如说,每5分钟收集一次数据,那么一小时就要采集12次,这12次采集的数据就是历史数据,将这12次采集的数据经过聚合运算得出聚合的结果,可能只有三四个数据项,最大,最小,平均值,这就是趋势数据。
所以为了展示数据的长期走势,多保留一些趋势数据,历史数据仅保留最近几个月的,但是这么一来,就会给数据库带来的更大的压力,因为既要存储趋势数据,又要存储历史数据,为了解决这个问题,早期使用关系型数据库作为存储系统,后来也有了一些其他的方案,例如:rrd(cacti),round-robin-database轮询数据库
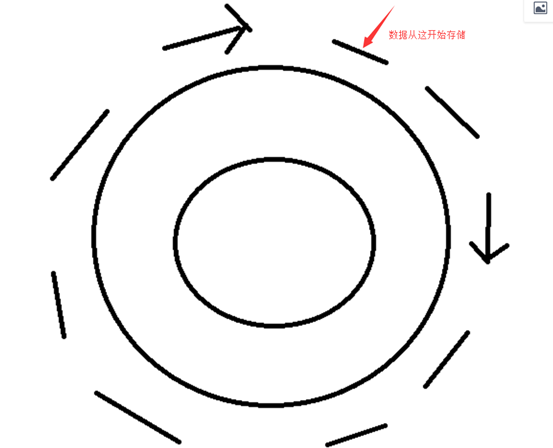
数据存储就像围绕一个圆进行存储,当存满了之后,再有新的数据来存储,就会覆盖原来最早存储的数据。
告警
如果一个监控系统监控到异常状态的信息,向用户发短信,就需要有一个前提,监控系统能够发短信,但是监控系统并不做这个工作,他只调用发短信这个服务,就需要写一个程序,来调短信服务的api接口,这个程序写好之后能够被监控系统所触发即可。
展示
常见的监控系统
Nagios:"难够死",是一个非常好的告警系统,但是没有提供存储系统
Cacti:Cron+SNMP+Mysql,很好的展示系统,但是问题出现比较多
1.支持多种接口完成数据采集:agent,SNMP,IPMI(英特尔智慧平台接口),jmx
(1)可以告警升级,刚开始出故障时,发短信给运维工程师,隔两小时后没有解决问题,就发给他的领导,再隔两小时没解决,发给领导的领导,,,
(2)可以发远程命令,刚开始出故障时,尤其是服务级故障,先不要立即发告警,在第一个周期内,试图尝试去解决问题,远程指挥目标主机重启一下服务,如果问题解决,就不用发警报了,如果没有解决,那就开始发警报
4.展示:简单图,图形,screen,slide,show,map,,,
1.statsd+influxdb(时序数据库)+grafana
2.promethues(自身就相当于时序数据库,可收集数据,存储下来,并展示,但展示界面不好看,所以可结合grafana)+grafana
zabbix程序架构
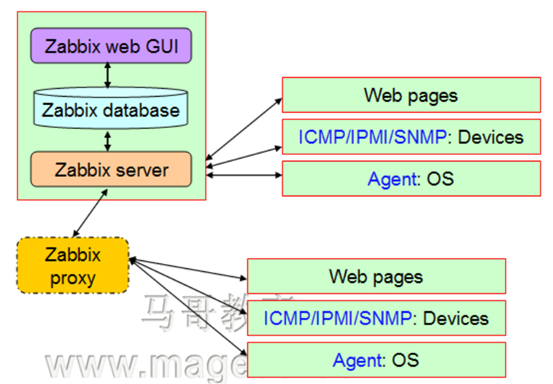
Zabbix组件概述
Zabbix Server:负责接收agent发送的报告信息的核心组 件,所有配置、统计数据及操作数据均由其组织进行;
Database Storage:专用于存储所有配置信息,以及由zabbix收集的数据,以及存储在Zabbix所配置的配置信息,比如:哪个指标需要监控,多长时间监控一次等;
Web interface:zabbix的GUI接口,通常与Server运行在 同一台主机上;
Proxy:可选组件,常用于分布监控环境中,代理Server收 集部分被监控端的监控数据并统一发往Server端;
Agent:部署在被监控主机上,负责收集本地数据并发往 Server端或Porxy端;
Zabbix监控Java应用
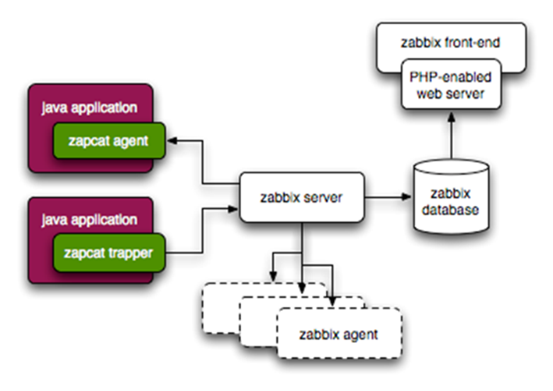
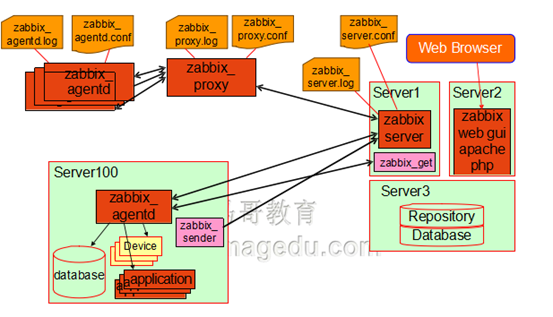
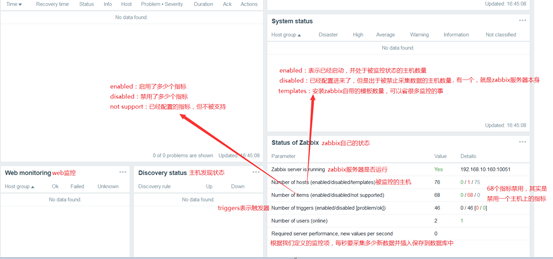
监控系统运行状态
Zabbix Server监控的主机上指标不只一个,以一个指标为例,假如每隔120秒采样一次,采集一次存一次,而且每当一个时间段满足时会做一次聚合运算,得出聚合运算结果,最大值,最小值,平均值等,每次采集存储下来之前会先评估一下数据是否满足触发器,既是否在合理区间范围内,如果在就OK,否则PROMBLE,一旦状态发生转换,假如上次是OK,现在转换成了PROMBLE,就会触发一个时间EVENT,就会采取行动,行动分多个层级,首先执行远程命令,如果不行,就发报警等。
采集----》判定阈值范围-----》如果没问题就存下来,如果有问题则有事件产生,就会产生某个行为,告警操作
Zabbix常用的术语
主机(host):要监控的网络设备,可由IP或DNS名称指定;
主机组(host group):主机的逻辑容器,可以包含主机和模 板,但同一个组内的主机和模板不能互相链接;主机组通常 在给用户或用户组指派监控权限时使用;
监控项(item):一个特定监控指标的相关的数据,这些数据 来自于被监控对象;item是zabbix进行数据收集的核心,没 有item,将没有数据;相对某监控对象来说,每个item都由"key"进行标识;
触发器(trigger):一个表达式,用于评估某监控对象的某特 定item内所接收到的数据是否在合理范围内,即阈值;接收 到的数据量大于阈值时,触发器状态将从"OK"转变为 "Problem",当数据量再次回归到合理范围时,其状态将从 "Problem"转换回"OK";
事件(event):即发生的一个值得关注的事情,例如触发器的 状态转变,新的agent或重新上线的agent的自动注册等;
动作(action):指对于特定事件事先定义的处理方法,通过包 含操作(如发送通知)和条件(何时执行操作);
报警升级(escalation):发送警报或执行远程命令的自义定方 案,如每隔5分钟发送一次警报,共发送5次等;
媒介(media):发送通知的手段或通道,如Email、Jabber或SMS等;
通知(notification):通过选定的媒介向用户发送的有关某事 件的信息;
远程命令(remote command):预定义的命令,可在被监控 主机处于某特定条件下时自动执行;
模板(template):用于快速定义被监控主机的预设条目集 合,通常包含了item、trigger、graph、screen、
application以及low-level discovery rule;模板可以直接链接至单个主机;
web场景(web scennario):用于检测web站点可用性的一个 或多个HTTP请求;
Zabbix的逻辑架构
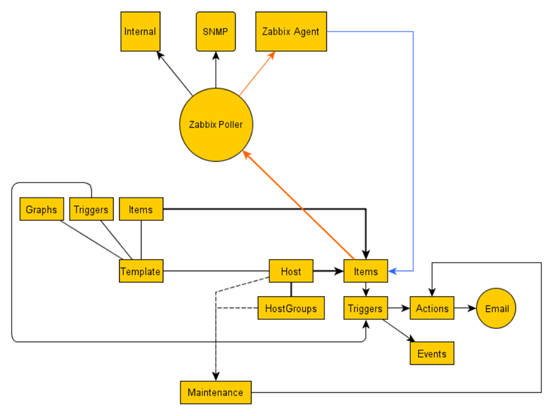
Zabbix Server Processes
安装zabbix
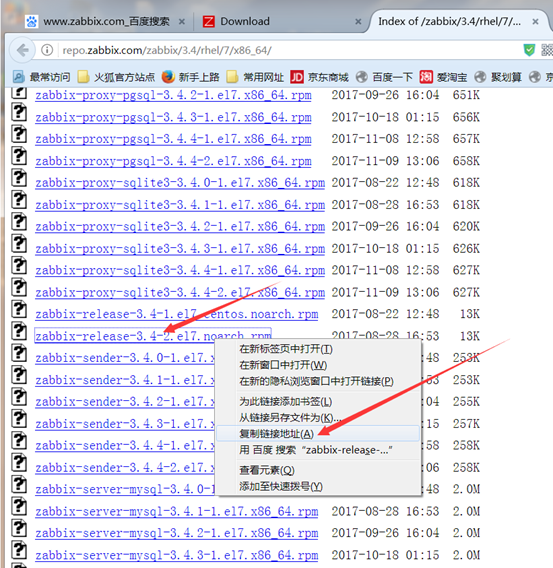
复制链接地址,然后在linux系统上,将其下载下来,注意你的dns和网关都正常,否则就会下载不上
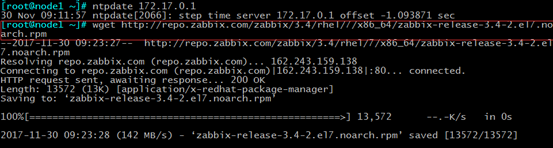
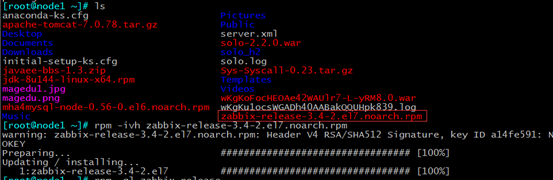
再来看一下安装了这个包,安装的文件,可以看到自动在/etc/yum.repo下面给你配好了zabbix仓库
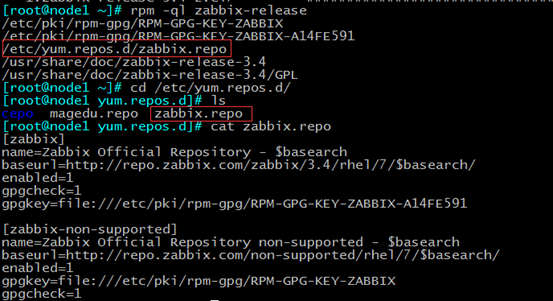
此时,再yum clean all,yum repolist就会列出安装zabbix的yum仓库
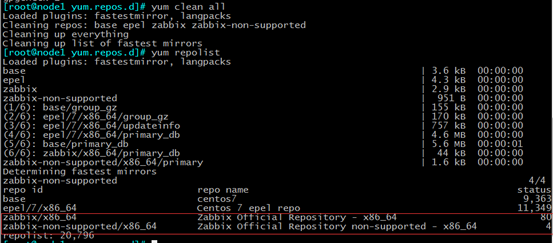
innodb_buffer_pool_size = 256M 缓冲池大小为256M
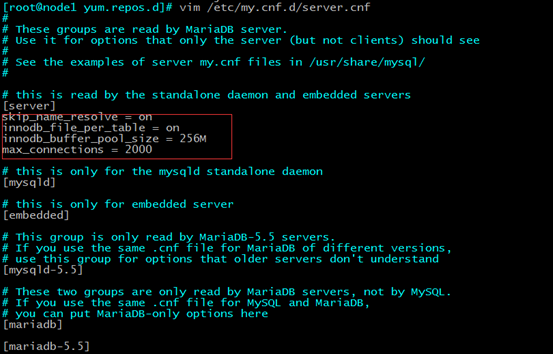
yum install zabbix-server-mysql zabbix-web zabbix-web-mysql zabbix-agent zabbix-get zabbix-sender -y
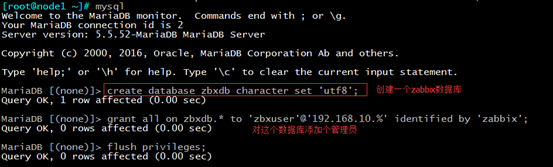
考虑到zabbix来连接数据库,尽可能用普通用户的身份来连接,所以需要进入数据库中创建用户
create database zbxdb character set 'utf8';
grant all on zbxdb.* to 'zbxuser'@'192.168.10.%' identified by 'zabbix';
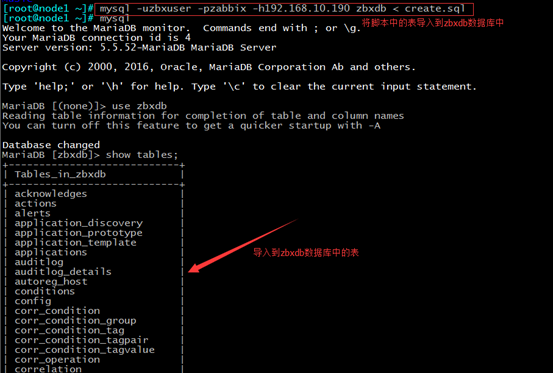
安装zabbix-server-mysql时提供了一些脚本,其中/usr/share/doc/zabbix-server-mysql-3.4.4/create.sql.gz就是在zabbix数据库生成表的脚本

cp /usr/share/doc/zabbix-server-mysql-3.4.4/create.sql.gz /root
cp /etc/zabbix/zabbix_server.conf /etc/zabbix/zabbix_server.conf.bak 修改配置文件先做好备份,养成良好习惯
LogFile=/var/log/zabbix/zabbix_server.log 日志文件
PidFile=/var/run/zabbix/zabbix_server.pid pid进程文件
DBHost=192.168.10.160 zabbix连接数据库所在的主机
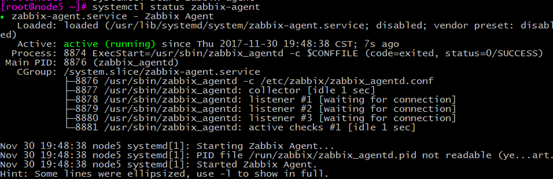
配置完后,启动zabbix服务,然后查看zabbix服务状态
systemctl status zabbix-server
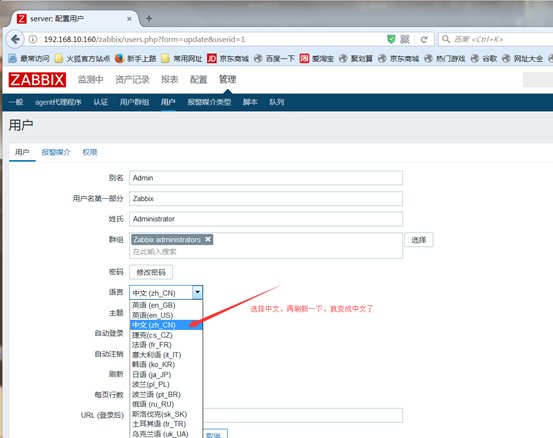
接下来就是通过zabbix GUI接口来访问zabbix的web页面,需要修改配置文件
vim /etc/httpd/conf.d/zabbix.conf
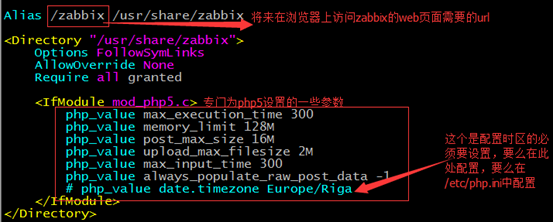
在/etc/php.ini中配置时区(在/etc/php.ini中配置时区对所有的php程序都有效,在/etc/httpd/conf.d/zabbix.conf中配置时区只对zabbix应用有效)

然后开启httpd服务,在浏览器上去访问zabbix的web页面
在浏览器上去访问zabbix的web页面,访问成功,第一次访问的时候,需要做一些初始化设置,如下图



monitoring

configuration
要配置监控目标主机的指标需要在configuration中配置

Report
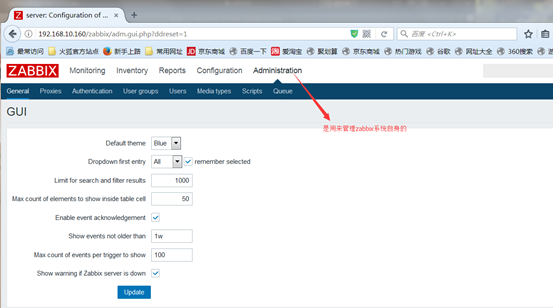
administration是用来管理zabbix系统自身的
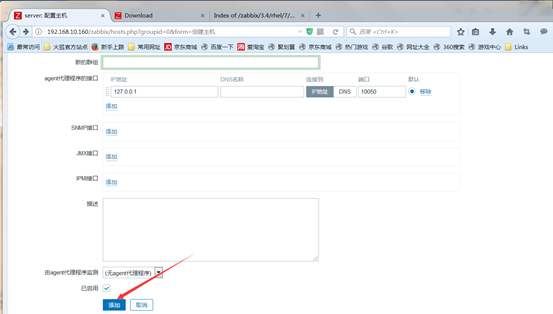
1.安装agent(在监控的目标主机上配置)
yum install zabbix-agent zabbix-sender -y
2.修改agent配置文件
vim /etc/zabbix/zabbix_agentd.conf
PidFile=/var/run/zabbix/zabbix_agentd.pid
LogFile=/var/log/zabbix/zabbix_agentd.log
Server=192.168.10.160 监控服务器是哪台主机
ServerActive=192.168.10.160 主动监控的服务器是哪台主机
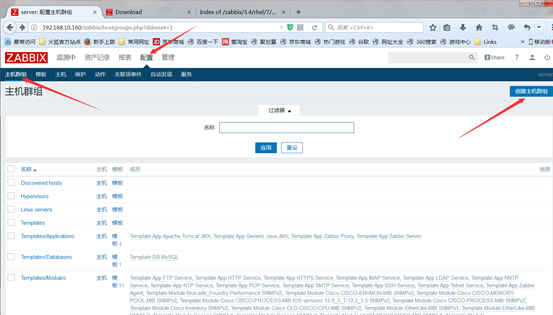
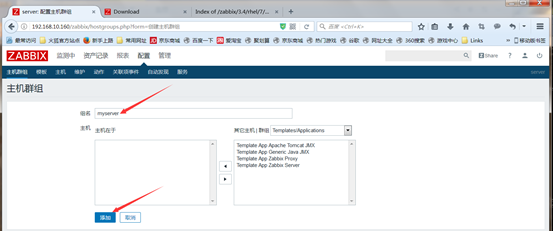


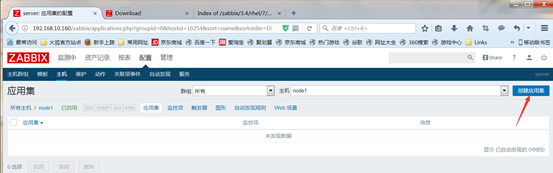
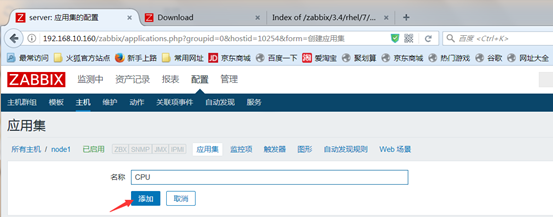
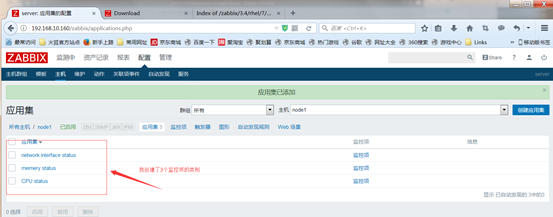
然后点击application应用集来定义监控项的类别,点击创建应用集
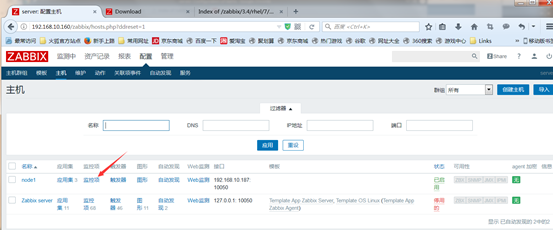

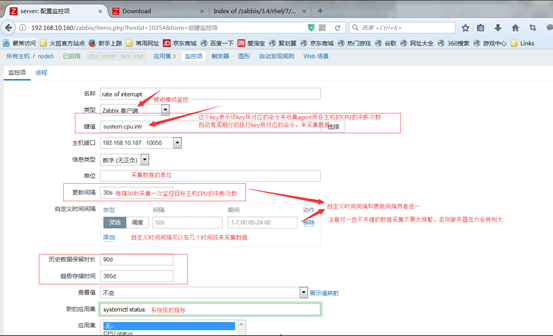
key其实就是一些命令,而內建key其实就是经过多次优化的命令,采集数据速度快,效率高,如果內建key不足以满足我们的需要的话,还可以用户自定义key
3.(delta)本次采样减去前一次采样的值,在除以经过的时长


再来编辑一个item,网卡指标数据,要考虑的是要获取哪个网卡的值,要获取哪个网卡上的指标
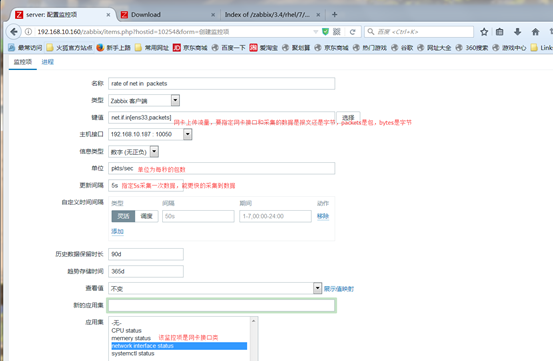
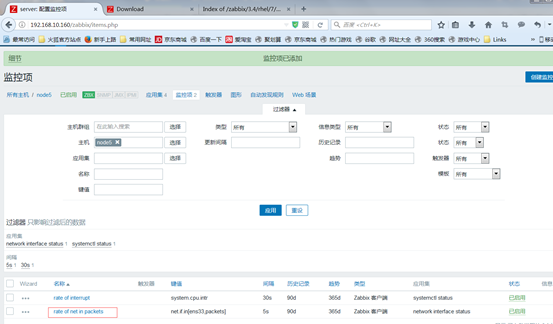
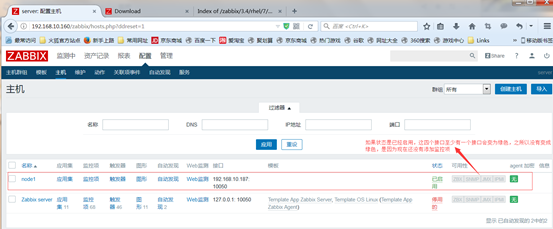
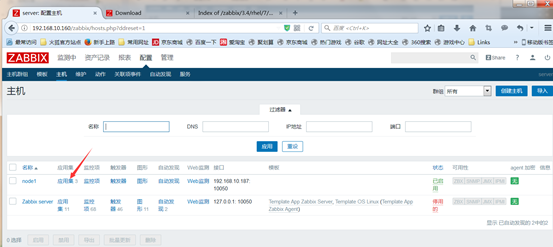
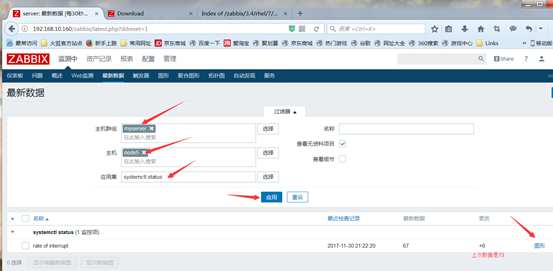
接着查看采集的数据,在monitoring中的latest data查看


trigger触发器
界定某特定的item采集到的数据的非合理区间或非合理状态:逻辑表达式
problem:非正常状态 --> 较老的zabbix版本为true;
创建触发器(trigger)
1.监控项"仅负责收集数据,而通常收集数据的目的还包括在 某指标对应的数据超出合理范围时给相关人员发送告警信 息,"触发器"正是用于为监控项所收集的数据定义阈值
2.每一个触发器仅能关联至一个监控项,但可以为一个监控项 同时使用多个触发器
事实上,为一个监控项定义多个具有不同阈值的触发器,可以 实现不同级别的报警功能
3.一个触发器由一个表达式构成,它定义了监控项所采取的数 据的一个阈值
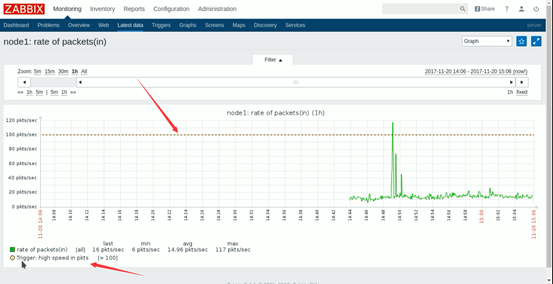
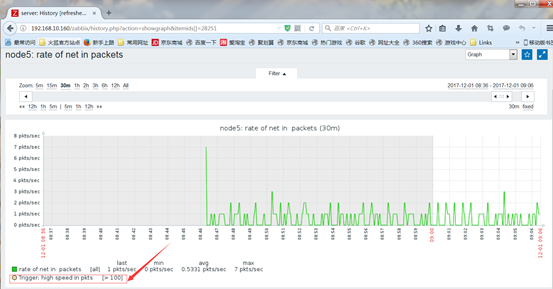
4.一旦某次采集的数据超出了此触发器定义的阈值,触发器状 态将会转换为"Problem";而当采取的数据再次回归至合理范 围内时,其状态将重新返回到"OK"
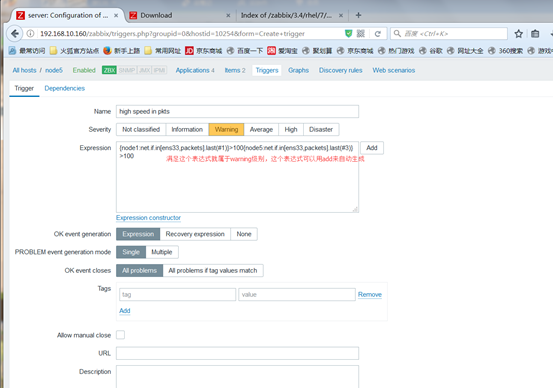
触发器表达式
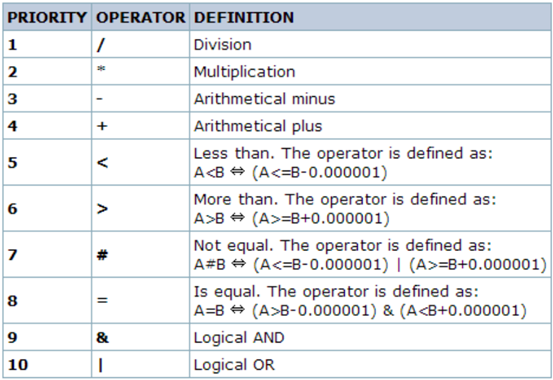
{<server>:<key>.<function>(<parameter>)}<operator><constant>
function:评估采集到的数据是否在合理范围内时所使用的函数,其 评估过程可以根据采取的数据、当前时间及其它因素进行;
目前,触发器所支持的函数有avg、count、change、date、dayofweek、delta、diff、iregexp、last、max、min、nodata、now、sum等
parameter:函数参数;大多数数值函数可以接受秒数为其参数,而 如果在数值参数之前使用"#"做为前缀,则表示为最近几次的取值,如:
sum(300)表示300秒内所有取值之和,而sum(#10)则表示最近10次取值之和;
此外,avg、count、last、min和max还支持使用第二个参数,用于完 成时间限定;例如,max(1h,7d)将返回一周之前的最大值;
触发器表达式的例子
{www.magedu.com:system.cpu.load[all,avg1].last(0)}>3
表示主机www.magedu.com上所有CPU的过去1分钟内的平均负 载的最后一次取值大于3时将触发状态变换
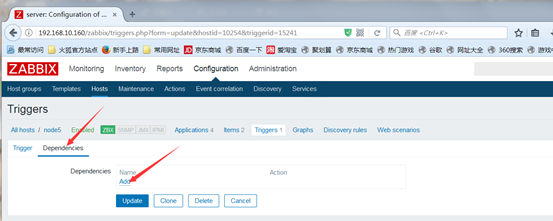
触发器间的依赖关系
例如,当某网关主机不可用时,其背后的所有主机都将无法正常访问
如果所有主机都配置了触发器并定义了相关的通知功能,相关人员将会接收到许多告警信息,这既不利于快速定位问题,也 会浪费资源
正确定义的触发器依赖关系可以避免类似情况的发生,它将使 用通知机制仅发送最根本问题相关的告警
注意:目前zabbix不能够直接定义主机间的依赖关系,其依 赖关系仅能通过触发器来定义
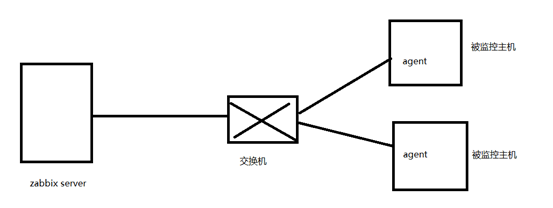
监控主机zabbix server 通过交换机的网络连接线来监控两台主机,假如交换机出现故障了,那么zabbix server也就采集不了被监控主机的数据了,不仅交换机的触发器会报警,被监控主机的触发器也会报警,此时定位故障就不好定位了,我们不知道到底是交换机出现了故障,还是被监控主机出现了问题,所以此时要定义触发器间的依赖关系,如果交换机出现了故障,交换机的触发器报警了,所有依赖此交换机触发器的主机就不用报警了。
2.被监控主机上服务触发器的依赖关系
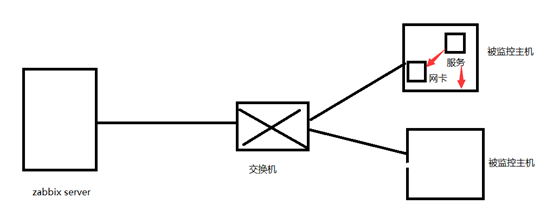
如图:触发器之间的依赖关系:被监控主机上的服务是否正常依赖于主机和主机网卡,而主机和主机网卡是否正常,依赖于交换机,所以监控到交换机故障,被监控主机就不用报警了,监控到被监控主机网卡故障,被监控主机上的服务就不用报警了(被监控网卡故障会导致zabbix server不能采集到被监控主机服务指标的数据)。
注释:定义触发器之间的依赖关系需要根据网络拓扑图来定义的
在web界面创建触发器(trigger)

action执行动作
1.在配置好监控项和触发器之后,一旦正常工作中的某触发器状态发生改变,一般意味着有异常情况发生,此时通常需要采取一定的动作(action),如告警或者执行远程命令等
2.并非所有的触发器状态发生改变的场景都需要对其进行干预,如转变为"OK"状态时,相应地,如果触发器的状态转变为"Problem",就需要告知所有关心其相关监控指标的人员了。
3."通知(notification)"是zabbix中最常用的"动作"之一
实现zabbix的通知功能,一般需要两个步骤:
1. 定义所需的"媒介(media)":通常指发送信息的途径,如邮件、Jabber和SMS等;
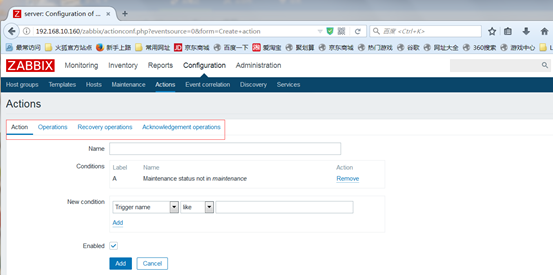
2.配置一个"动作(action)":发送信息至某"媒介";
动作由"条件"和"操作"组成,它的逻辑为当"条件"满足时,就执行相应的"操作" "发送通知"和"执行远程命令"是两个最基本的操作
zabbix事件(event)
1.触发器(trigger)事件:触发器状态每次发生改变,都会生成相 应"事件",且通常包含详细信息,如发生的时间及新的状态等;
2.发现(discovery)事件:zabbix会周期性地扫描"网络发现规则" 中指定的IP范围,一旦发现主机或服务,就会生成一个或几个 发现事件;
发现事件有8类:Service Up、Service Down、Host Up、 Host Down、Service Discovered、Service Lost、Host
选择合适的事件源,来创建action,我们只了解了触发器,所以就选择triggers

operations:操作,在operations里面可以定义一些操作,每隔多长时间执行一次(是从正常到非正常的而执行的动作)
Recovery operations:还没有执行operations的动作,又恢复了(从problem到ok状态),要执行Recoery operations里定义的动作
Acknowledge operations:声明已经执行了operations里定义的动作
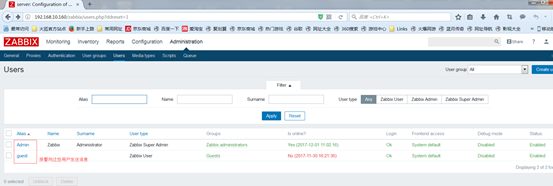
报警向Adminstration中users中的用户发送消息
1.定义媒介的类型,关联到用户,让他们收到告警信息
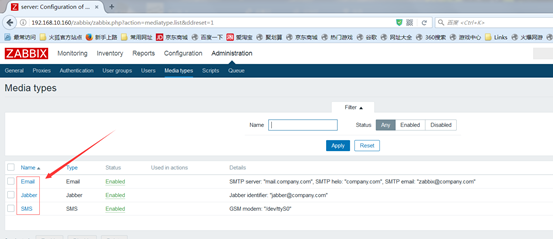
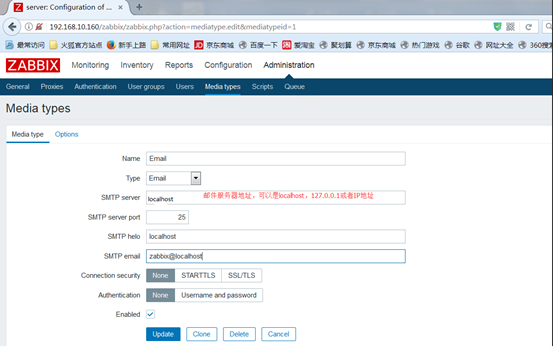
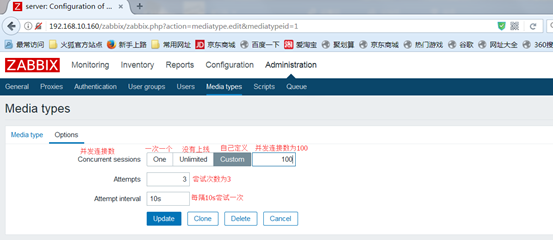
配置完之后,点击更新Update,ming_mail定义好了
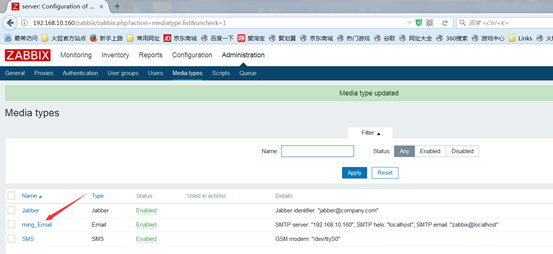
接着就可以回到Users中点击admin,就可以选择定义好的媒介类型了

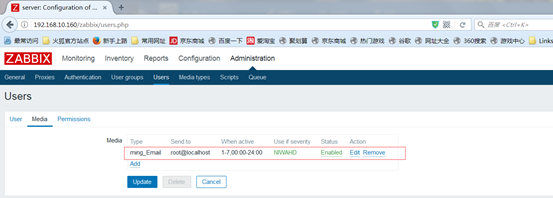
将来在公司里面,有好多人都想了解线上服务的信息,那么就要在zabbix上给他们创建一个账号,再给他们关联一个媒介类型,这样才能让他们收到告警信息
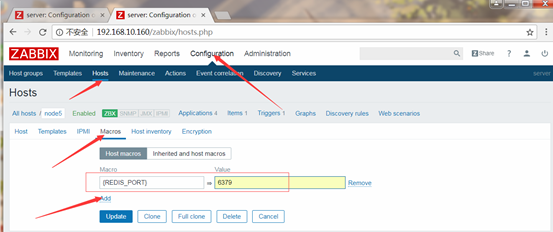
2.创建action,监控一个服务,如果这个服务挂了,那么就尝试重启,成功了就ok,没成功就发告警信息
(1)配置redis服务
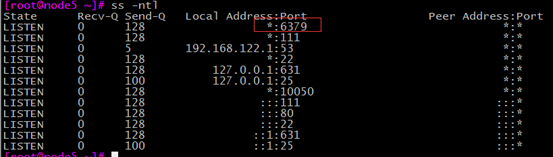
(2)定义item


回到monitoring中查看定义的监控项 up或1为redis服务正常
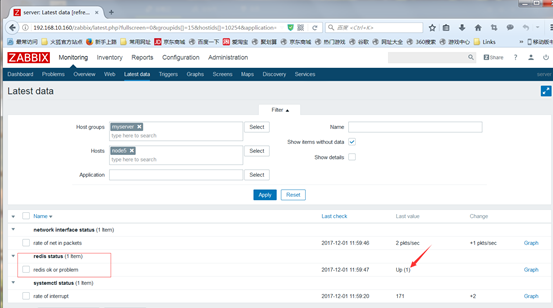
(3)定义触发器triggers,如果发现服务挂了,就会发送触发器事件
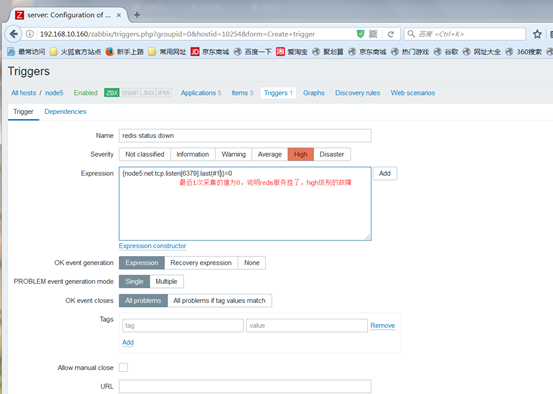
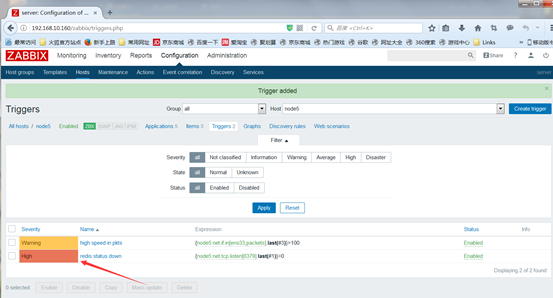
(4)创建action



vim /etc/zabbix/zabbix_agentd.conf

systemctl restart zabbix-agent
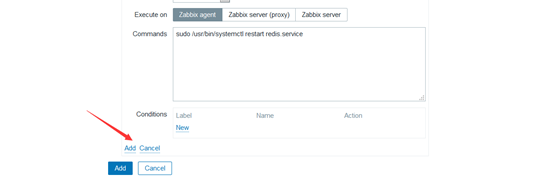
第一步做好了,当redis服务挂了之后,就会先尝试重新启动redis服务,重启成功就ok,不成功开始执行第二步,给相关人员发消息,接着就开始定义第二步的操作

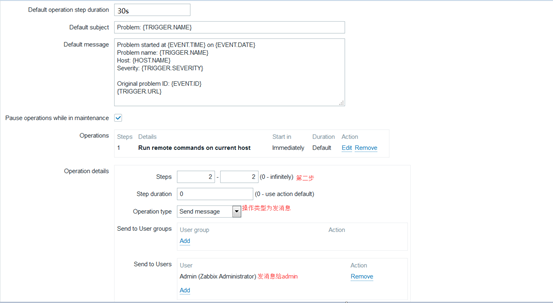

如果执行远程命令服务重启成功了,怎么办,接下来的操作就要在recovery operations里定义,一样也是给相关人员发消息,说服务已经恢复了,可以不用来了
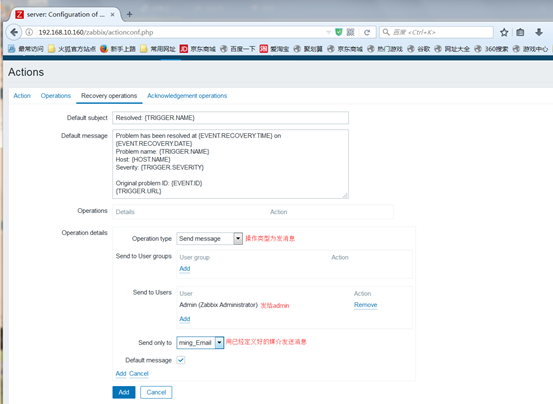
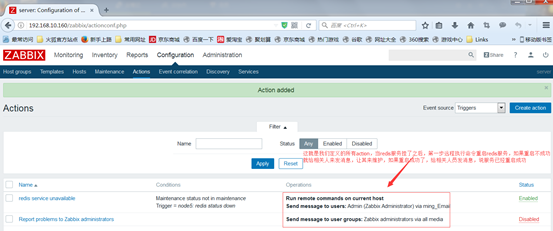
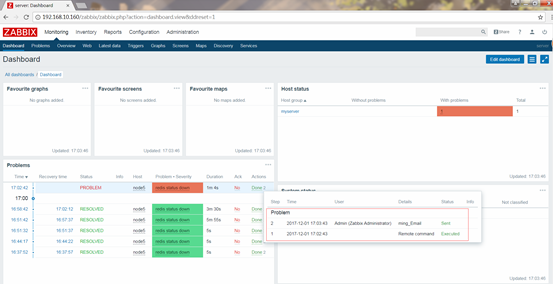
接着我们就可以测试了,先停掉redsi服务,去monitoring中查看dashboard面板,如图:
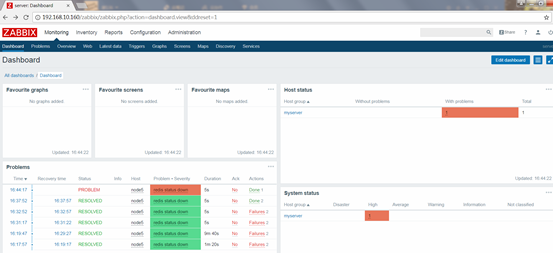
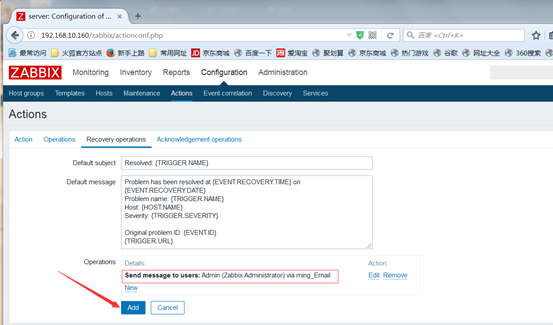
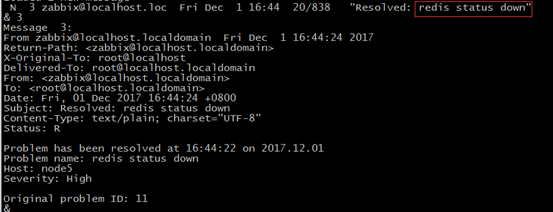
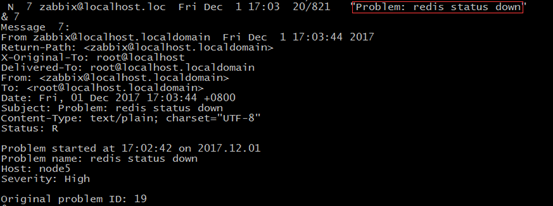
过了一会,自动恢复过来,说明远程执行命令重启redis服务成功,接着又会向admin发消息,如图:

接着我们在开启redis服务,然后再关掉redis服务并卸载redis
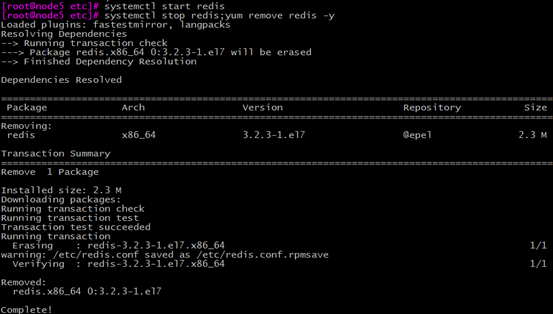
过了一会没有自动回复,说明远程执行命令失败,再过一会,就开始发邮件了
zabbix可视化
zabbix提示了众多的可视化工具提供直观展示,如graphscreen及map等
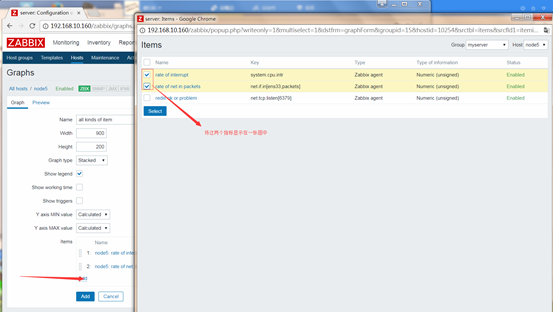
自定义图形(graphs)
支持"线状图(normal)"、"堆叠面积图(stacked)"、"饼图(pie)" 和"分离型饼图(exploded)"四种不同形式的图形
"Configuration → Hosts (或者Templates) → Graphs→Create graph"
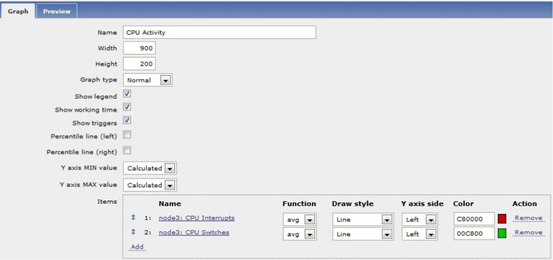
自定义图形的相关属性说明
Width:图形的宽度,单位为像素;仅适用于"预览(preview)"模式、饼图或分离型饼图;
Graph type:图形类型,共有四种,即"线状图(normal)"、"堆 叠面积图(stacked)"、"饼图(pie)"和"分离型饼图(exploded)";
Show working time:是否高亮显示工作时间区域;选定时, 非工作时间区间的背景为灰色;此功能不适用于pie和 exploded;
Show triggers:是否显示触发器;此功能不适用于pie和 exploded;
Y axis MIN value:Y轴最小刻度,其类型有三种;
Fixed:固定值,此功能不适用于pie和exploded;
Y axis MAX value:Y轴最大刻度,其类型同上述最小刻度的 说明;
3D view:3D风格,此功能仅适用于pie和exploded;
Items:图形展示的数据序列所来自的item,一个图形中可以同 时展示多个item;
在一个图形中,不同item的图形还有一些可单独配置的属 性,如图形颜色、绘图风格等
Y axis side:Y轴显示的位置,可以为图形左侧或右侧;
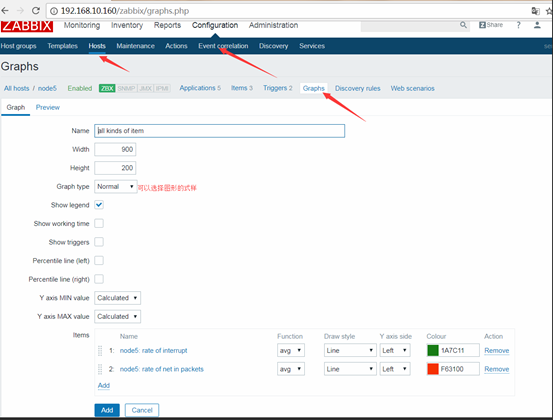
多个指标显示在一张图上
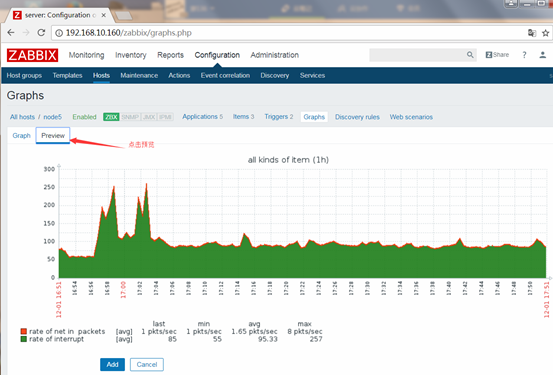
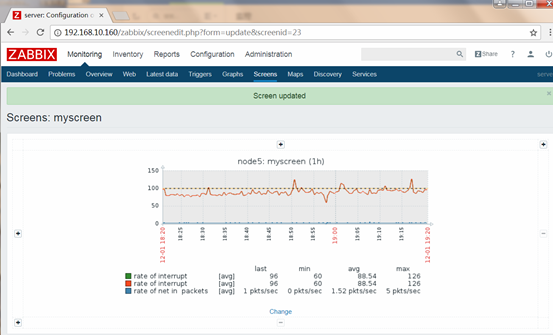
屏幕(screen)
屏幕用于集中展示多个数据源的相关信息,可实现快速浏览 关注的信息
从根本上来讲,screen就是一个图表,可以在创建时可以指 定其行数和列数,而后在每个格子中指定要展示的内容
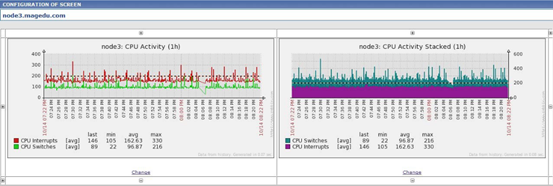
screen可以展示的信息有许多种,如:简单图形、用户自定 义图形、maps、其它screen、文本信息、概述的服务器信息、 概述的主机信息、概述的触发器信息、触发器状态、系统状 态等等
查看
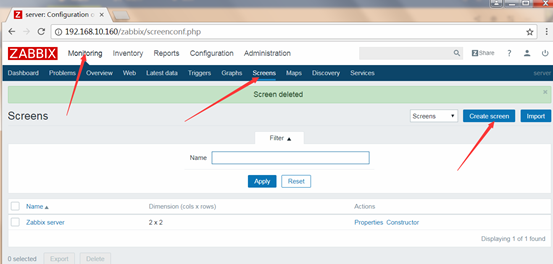
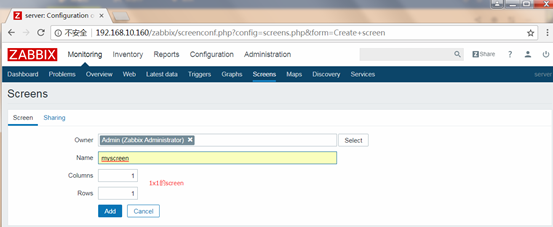
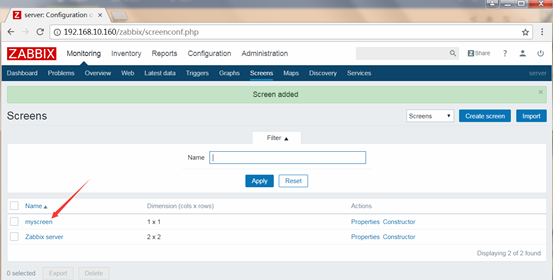
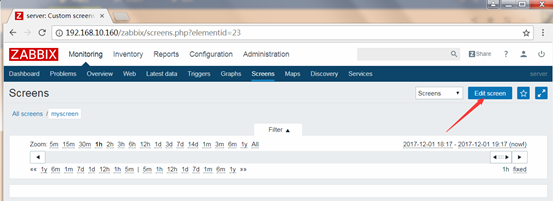
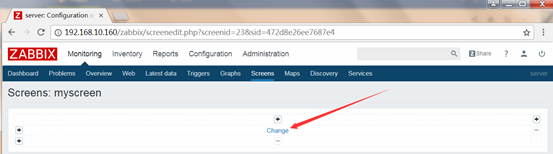
Configuration-->Screens-->Create Screen
创建
创建screen

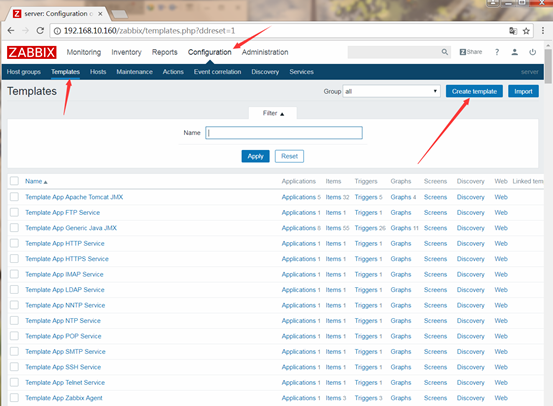
模板(Templates)
模板是一系列配置的集合,它可以方便地快速部署在某监控 对象上,并支持重复应用
low-level discovery rules (since Zabbix 2.0)
模板的另一个好处在于,必要时,修改了模板,被应用的主机都会相应的作出修改
创建模板(Templates)
在模板上可以按需添加item、trigger、screen、graph,application及发现规则
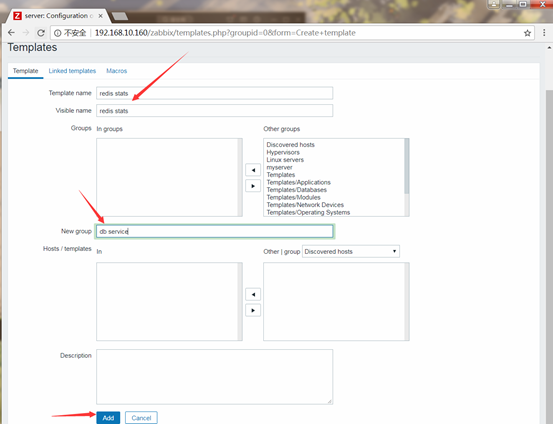
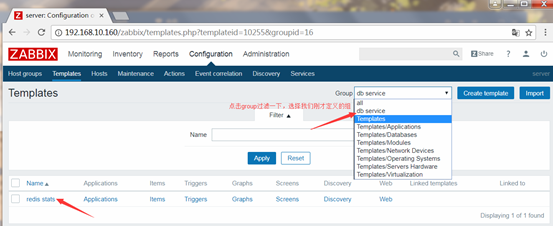
然后将模板关联到主机上去,Configuration-->Hosts

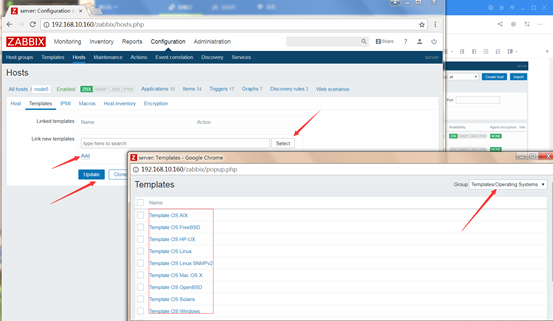
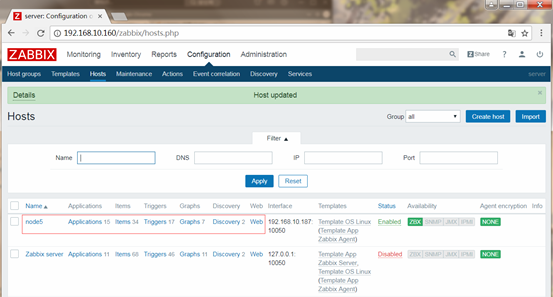
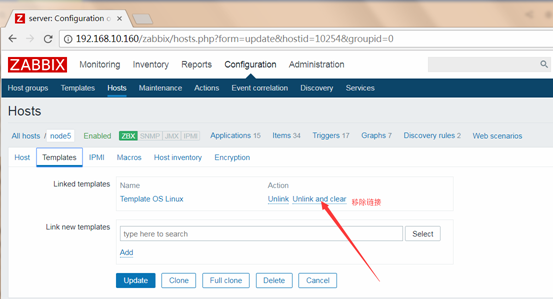
宏(macros)
宏是一种抽象(Abstraction),它根据一系列预定义的规则替 换一定的文本模式,而解释器或编译器在遇到宏时会自动进 行这一模式替换
类似地,zabbix基于宏保存预设文本模式,并且在调用时将 其替换为其中的文本
zabbix有许多内置的宏,如{HOST.NAME}、{HOST.IP}、{TRIGGER.DESCRIPTION}、{TRIGGER.NAME}、{TRIGGER.EVENTS.ACK}等
https://www.zabbix.com/documentation/2.0/manual/appendix/macros/supported_by_location
为了更强的灵活性,zabbix还支持在全局、模板或主机级别 使用用户自定义宏(user macro)
宏可以应用在item keys和descriptions、trigger名称和表达 式、主机接口IP/DNS及端口、discovery机制的SNMP协议 的相关信息中等
https://www.zabbix.com/documentation/2.0/manual/appendix/macros/supp
orted_by_location#additional_support_for_user_macros
宏替换次序
其次是当前主机上一级模板中(直接链接至主机的模板)的宏, 多个一级模板按其ID号排序;
zabbix如果无法查找到某主机定义使用的宏,则不会对其进行替换操作。要使用用户自定义宏,有以下两种算途径:
全局宏:"Administration → General → Macros"
Macros使用示例
在主机级别定义一个名为{$CPUMAXSWITCHES}的宏,以 定义当前主机所接受的CPU上下文切换的合理次数


宏就是一个变量,分全局宏和主机或者模板上的宏(全局宏在adminstration中的user中定义,主机宏在host中定义,模板宏在模板上定义),定义完一个宏,在任何地方都可调用,假如说将被监控上某服务的端口定义为一个宏,那么如果该服务的端口发生变化,也不用在zabbix web界面上去更改
定义宏