1.常用方法
1、添加操作(与之前的有点不同)
- V put(K key,V value)
- void putAll(Map<? extends K,? extends V> m)
2、删除
- void clear() 清空所有键值对
- V remove(Object key) 移除指定key的键值对
3、元素查询的操作
- V get(Object key)
- boolean containsKey(Object key) 查找指定key的键值对
- boolean containsValue(Object value) 类似上
- boolean isEmpty()
4、元视图操作的方法:
- Set
keySet() - Collection
values() - Set<Map.Entry<K,V>> entrySet()
5、其他方法
- int size()
2.遍历
- foreach
- 通过Iterator对象遍历
- 注意!!!!!!!!!!!(先看这个)
- Map的遍历,不能支持foreach,因为Map接口没有继承java.lang.Iterable
接口,也没有实现Iterator iterator()方法。 - 分开遍历:
- 单独遍历所有key
- 单独遍历所有value
- 成对遍历:
- 遍历的是映射关系Map.Entry类型的对象,Map.Entry是Map接口的内部接口。每一种Map内部有自己的Map.Entry的实现类。在Map中存储数据,实际上是将Key---->value的数据存储在Map.Entry接口的实例中,再在Map集合中插入Map.Entry的实例化对象,
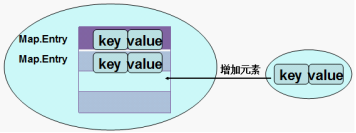
- 遍历的是映射关系Map.Entry类型的对象,Map.Entry是Map接口的内部接口。每一种Map内部有自己的Map.Entry的实现类。在Map中存储数据,实际上是将Key---->value的数据存储在Map.Entry接口的实例中,再在Map集合中插入Map.Entry的实例化对象,
- Map的遍历,不能支持foreach,因为Map接口没有继承java.lang.Iterable
3.Map实现类
1、HashMap重点
特点
- key
- 无序:
- 不是添加顺序
- 唯一
- key不重复
- 无序:
- value
- 只要满足泛型要求即可
- 注意:
- 如果key 重复 新的value 会替换旧的value
key 存储自定义类型数据
需要重写 hashCode equals()
与Hashtable的区别
- HashMap和Hashtable都是哈希表。
- HashMap和Hashtable判断两个 key 相等的标准是:两个 key 的hashCode 值相等,并且 equals() 方法也返回 true。因此,为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
- Hashtable是线程安全的,key和value都不能为null
- HashMap是线程不安全的,key和value可以使用 null (可以单独一个使用)。
从源码解释HashMap
- \1.创建HashMap
- 将默认的负载因子 0.75f 赋值给了成员变量
- \2. 数据添加 第一次添加时 给底层Node[] 16 threshold 12
- 2.1 key null
- 将数据添加到哈西表内下标为0的位置
- 2.2 key 非null
- 2.2.1 插入位置没有数据
- 直接添加
- 2.2.2 插入位置有数据 key 不一样
- 原有节点的后面进行追加
- 七上八下 jdk8 下 后面追加
- 2.2.3 插入位置有数据 key相同
- 将新的value 替换 旧的value 并将旧的value返回
- 2.2.4
- 扩容
- 当集合中元素的数量>阈值 触发扩容 数组<<1 阈值<<1
- 树化
- 0.插入位置节点的数量>=8
- \1. 底层数组长度 >=64
- \3. 插入新的数据 新数据的位置不能为null
- 扩容
- 2.2.1 插入位置没有数据
- 2.1 key null
2、TreeMap
定义:
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
当其key存储自定义类型数据
需要指定key的比较规则
特点
- key
- 有序:
- 自然顺序
- 唯一
- key不重复
- 有序:
- value
- 只要满足泛型要求即可
- 注意:
- 如果key 重复 新的value 会替换旧的value
3、LinkedHashMap
定义
LinkedHashMap 是 HashMap 的子类。此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。
特点
- key
- 有序:
- 添加顺序
- 唯一
- key不重复
- 有序:
- value
- 只要满足泛型要求即可
- 注意:
- 如果key 重复 新的value 会替换旧的value
key 存储自定义类型数据
需要重写 hashCode equals()
4、Properties
- Properties 类是 Hashtable 的子类,Properties 可保存在流中或从流中加载。属性列表中每个键及其对应值都是一个字符串。
- 存取数据时,建议使用setProperty(String key,String value)方法和getProperty(String key)方法。
4.拓展
- HashSet 底层采用的是 HashMap将存储的值放到了 Map key 的位置
- LinkedHashSet 底层采用的是 LinkedHashMap将存储的值放到了 Map key 的位置
- TreeSet 底层采用的是 TreeMap将存储的值放到了 Map key 的位置