1.0.Sql语言分类(DML、DCL、DDL)

1.1.数据库三大特性
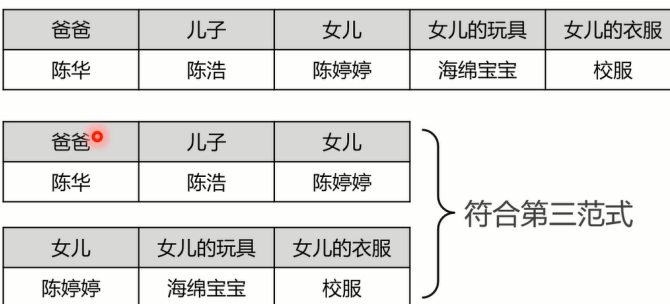
- 第一范式原子性:
-
第一范式是数据库的基本要求,不满足这一 点就不是关系数据库数据表的每一列都是不可分割的基本数据项,同一列中不能有多个值,也不能存在重复的属性。

-
- 第二范式:唯一性:数据表中的每条记录必须是唯一的。为了实现区分,通常要为表加上一个列用来存储唯一标识,这个唯一属性列被称作主键列
- 第三范式关联性:每列都与主键有直接关系,不存在传递依赖
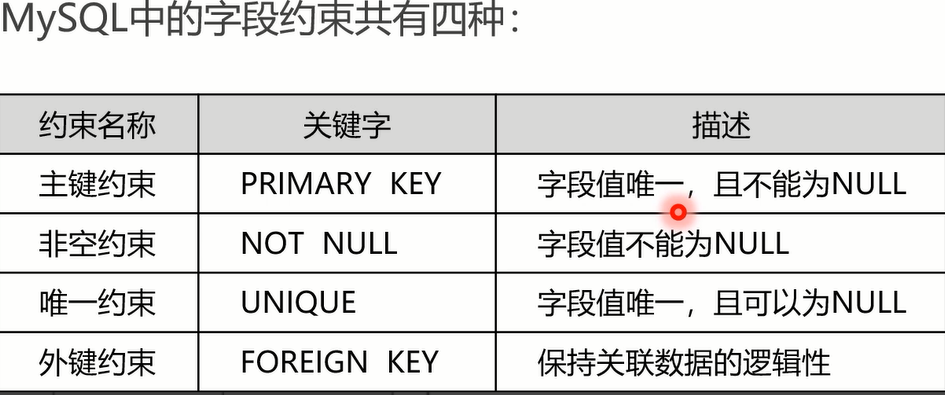
- 拓展:字段约束

1.2. 数据库设计规范
1.所有数据库对像名称必须使用小写字母并用下划线分割。不同的数据库名DbName、dbname
2.所有数据库对像名称禁止使用MySQL保留关建字,例如from等等。
3.数据库对像的命名要能做到见名识义,并且最好不要超过32个字符
4.临时库表必须以tmp_为前缀并以日期为后缀。
5.备份库,备份表必须以bak为前缀并以日期为后缀。
6.所有存储相同数据的列名和列类型必须-致
7.所有表必须使用Innodb存储引擎:
(1) 5.6以后的默认引擘
(2) 支持事务,行级锁,更好的恢复性,高并发下性能更好
(3) Mysql5.5使用之.前Myisam(默认存储引擎)情况
(4) 列无穷。空间数据可以使用其它(innodb无法满足)
8.数据库和表的字符集统一-使用UTF8/UTF8mb4
(1)utf8和utf8mb4区别:都是存汉字,utf8是3个字节一个汉字,utf8mb4是四个字节一个汉字,utf8mb4可以存生僻汉字和enjom表情
9.所有表和字段都需要添加注释.
(1) 使用comment从句添加表和列的备注
(2) 从一开始就进行数据字典的维护
10.尽量控制单表数据量的大小,建议控制在500万以内
(1) 500万并不是MySQL数据库的限制。
(2) 修改表结构,备份,恢复都会有很大问题。
(3) Mysql最多可以存储多少万数据呢?这种限制取决于存储设置和文件系统。
(4) 可以用历史数据归档,分库分表等手段来控制数据量大小。
11.谨慎使用MySQL分区表:
(1) 分区表在物理.上表现为多个文件,在逻辑上表现为一个表。
(2) 谨慎选择分区键,跨分区查询效率可能更低。
(3) 建议采用物理分表的方式管理大数据。
12.尽量做到冷热数据分离,减小表的宽度。
(1) Mysq|l限制最多存储4096列=》减少磁盘IO ,保证热数据的内存缓存命中率,利用更有效的利用缓存,避免读入无用的冷数据(SELECT * FROM )
(2) 经常一-起使用的列放到一个表中
(3) 禁止在表中建立预留字段
13.禁止在表中建立预留字段
(1) 预留字段的命名很难做到见名识义。
(2) 预留字段无法确认存储的数据类型,所以无法选择合适的类型。
(3) 对预留字段类型的修改,会对表进行锁定。
(4) 修改一个字段成本大于添加和删除。
14.禁止在数据库中存储图片,文件等二进制数据。
15.禁止在线上做数据库压力测试。
16.禁止从开发环境,测试环境直连生产环境数据库。
1.3. 索引设计规范(防止滥用索引)
1.限制每张表上的索引数量,建议单张表索引不超过5个。
(1) 索引并不是越多越好!索引可以提高效率同样可以降低效率。(优化查询、降低增加、删除)
(2) 禁止给表中的每一列都建立单独的索引
2.每个Innodb表必须有一个主键(主键就是一个索引)
(1) 不使用更新频繁的列作为主键,不使用多列主键
(2) 不使用UUID , MD5 , HASH,字符串列作为主键
(3) 主键建议选择使用自增ID值
3.对2的补充,int和uuid对比分析
(1) Int作为主键优点
① 需要很小的数据存储空间,bai仅仅需要4 byte。
② insert和update操作时使用INT的性能比GUID好,所以使用int将会提高应用程序的性能。
③ index和Join 操作,int的性能最好。
④ 容易记忆。
⑤ 支持通过函数获取最新的值,如:Scope_Indentity()。
(2) Int作为主键缺点
① 如果经常有合并表的操作,就可能会出现主键重复的情况。
② 使用INT数据范围有限制。如果存在大量的数据,可能会超出INT的取值范围。
③ 很难处理分布式存储的数据表。
(3) Uuid作为主键优点
① 它是独一无二的。
② 出现重复的机会少。
③ 适合大量数据中的插入和更新操作。
④ 跨服务器数据合并非常方便。
(4) Uud缺点
① 存储空间大(16 byte),因此它将会占用更多的磁盘大小。
② 很难记忆。join操作性能比int要低。
③ 没有内置的函数获取最新产生的guid主键。
④ GUID做主键将会添加到表上的所以其他索引中,因此会降低性能
4.常见索引列建议
(1) SELECT、UPDATE、DELETE语句的WHERE从句中的列
(2) 包含在ORDER BY、GROUP BY、DISTINCT中的字段
(3) 多表JOIN的关联列
5.索引列的顺序
(1) 联合索引中,索引是从左到右的顺序来使用的。
(2) 区分度最高的列放在联合索引的最左侧。
(3) 尽量把字段长度小的列放在联合索引的最左侧。
(4) 使用最频繁的列放到联合索引的左侧。
6.避免建立冗余索引和重复索引
7.对于频繁的查询优先考虑使用覆盖索引
(1) 覆盖索引:就是包含了所有查询字段的索引
(2) 避免Innodb表进行索引的二次查找
(3) 可以把随机I0变为顺序I0加快查询效率
8.尽量避免使用外键
(1) 不建议使用外键约束,但一定在表与表之间的关联键上建立索引
(2) 外键会影响父表和子表的写操作从而降低性能【外键建议在程序中判断】