redis通过前面几篇的数据结构构键了一个对象系统,这个对象系统包含了字符串对象,列表对象,哈希对象,集合对象,有序集合对象
每一个对象都是一个redisobject
typedef struct redisObject { // 类型 unsigned type:4; // 编码 unsigned encoding:4; // 指向底层实现数据结构的指针 void *ptr; // ... } robj;
type表示类型,有5种,就是
REDIS_STRING,REDIS_LIST,REDIS_HASH,REDIS_SET,REDIS_ZSET
编码表示的就是底层的实现,因为每一种对象都至少有两种以上的实现方式。ptr指向的就是底层实现的数据结构
字符串对象的编码可以是int,raw,embstr
int针对的是整数
如果字符串的长度小于39,那么使用embram,否则使用raw
embstr和raw的区别
(1)embstr是连续的,object和sds是一块连续的内存,这样的话分配内存和释放内存都不是两次,而是一次
(2)充分利用缓存的优势
double类型其实也是字符串类型的
当时用的时候会从字符串类型转换为double类型
int和embstr在满足条件的时候都会转换为raw编码,比如一个整数10085 appending一个字符串的话就不在是一个整数了
另外embsr不可以修改的,他是只读的,如果要修改的话,他会自动转换为raw之后再进行修改
列表对象:
列表对象的编码可以使压缩列表和双端链表,如果其中有字符串的话,字符串是字符串对象的表示,说明字符串对象可以被其他的对象嵌套
编码转换
(1)每一个元素得长度都小于64,
(2)数量小于512,
满足上面两个条件的话就是用压缩列表,否则的话使用双端链表
哈希对象
哈希对象的编码可以是压缩列表和字典
如下图所示
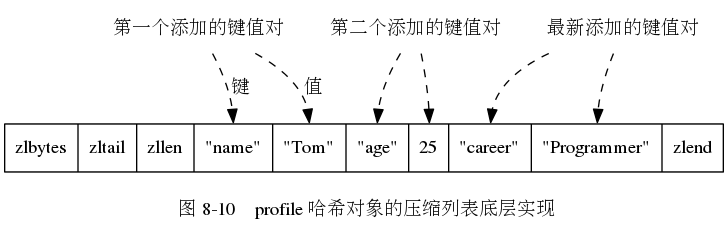
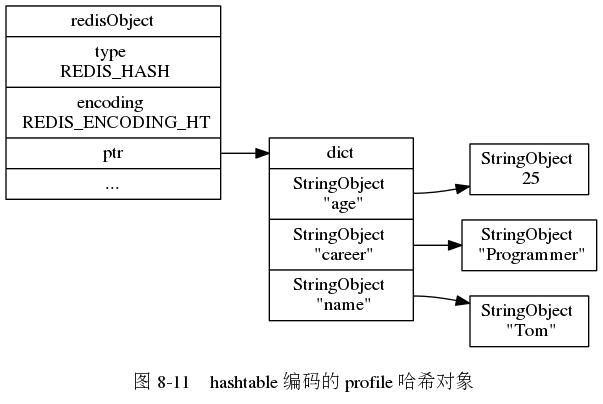
至于编码的转换,和上面的是一样的,如果两个都满足,就使用压缩列表,否则使用字典
ps:注意这两个限制条件在redis.conf的配置文件中是可以修改的
集合对象:
集合对象的编码可以是整数集合和hashtable
看下面:

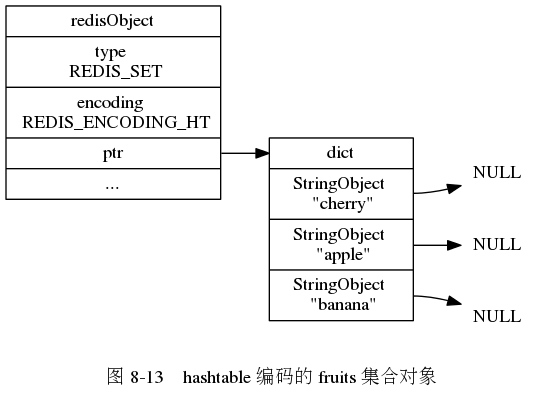
编码的转换条件
(1)都是整数
(2)元素数量不超过512个
满足以上条件使用整数集合,否则的话使用hashtable
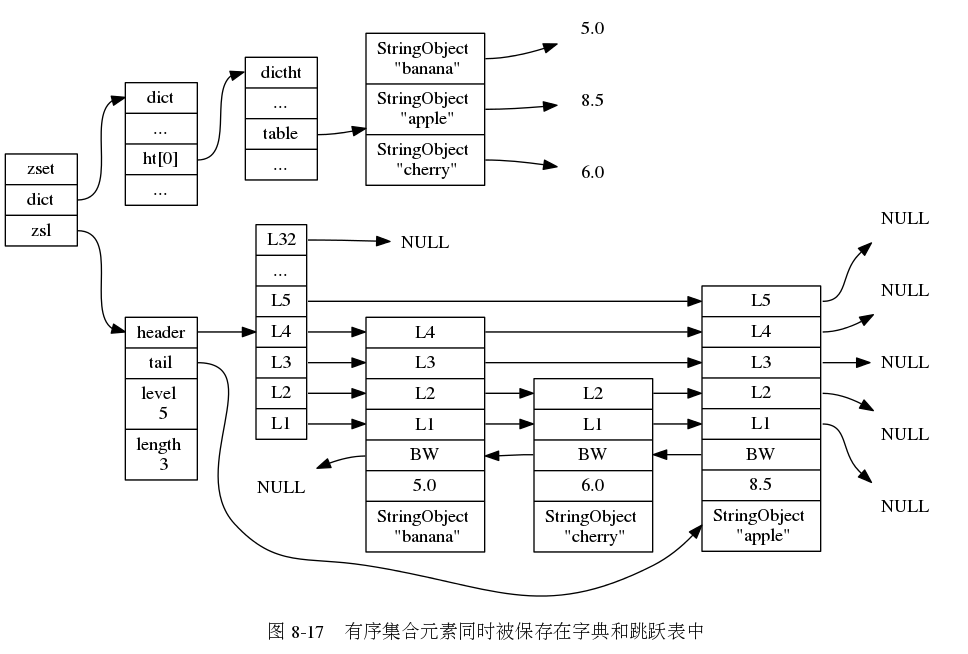
有序集合对象:
编码可以是压缩列表和跳跃表
压缩列表实现的话,使按照分值排序,并且存储的话对象在前,分值在后
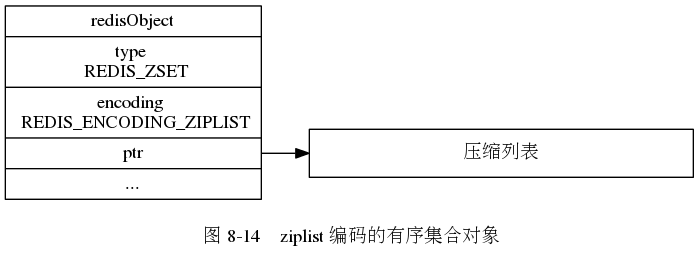

zset中基于跳跃表实现的话,就是讲分值从小到大排序,建立一个跳跃表,但是额外还需要一个字典,记录对象和分值的映射,这样的话对于ZSCORE命令,我们可以在O(1)的时间复杂度就可以获得到指定对象的分值
两者结合,无论是有序遍历还是获得指定元素,都会择优选择,降低时间复杂度
编码转换
(1)长度都小于64
(2)数量不超过128个
这两个都满足就是用压缩列表,否者就是用skiplist作为编码
额外对于对象还有很多优化和处理
(1)多态:很多命令都是具有多态的性质,就是可以处理多种命令
在执行一个命令的时候,我们首先会根据值对象的类型去判断这个命令能否执行,如果可以的话,我们还会根据值对象的编码方式选择正确的API去执行
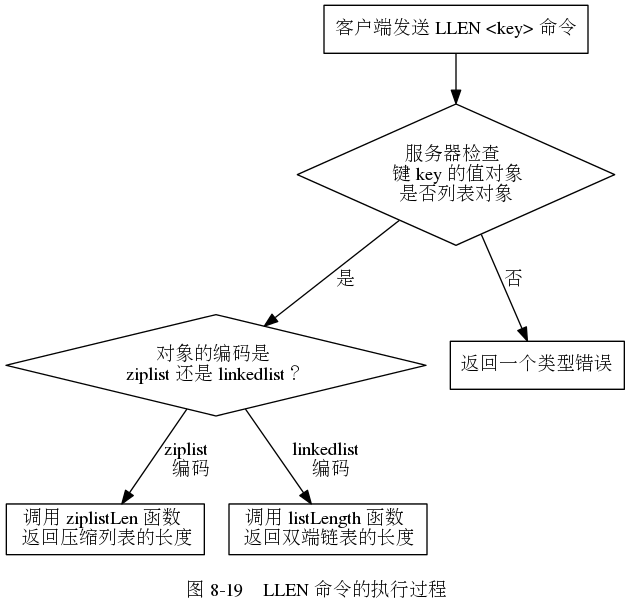
比如上面,我们就可以认为LLEN是多态的,多态可以包括基于类型的多态,和基于编码的多态
(2)内存管理:
对于redisobject我们基于引用计数原值,定义在redisobject结构里面的refcount int,当对象引用计数降低为0的时候,释放对象。这个有点类似windows线程回收机制,采用计数原值,关闭handle减一,线程函数退出减一,为0的时候自动回收线程资源
(3)对象共享:
redis中多个键的值一样的话,会使值指针只想一块内存,引用计数增加,redis服务器初始化的时候会默认创建0-9999字符串,所以他们的引用计数在还没使用的时候就是1了
(4)空转时长:
redisobject中有个lru,表示最后访问的时候
通过idletime可以求出多久没有被访问了,就是当前时间和lru时间差(空转时长)
但是ps(这个命令不会修改lru属性)
如果服务器设置了maxmemory选项,那么当内存达到上线了,服务器会优先空转时间长的进行释放