Python测试函数的方法之一是用:try……except
def gameover(a,b): if a>=10 and b>=10 and abs(a-b)==2: return True if (a>=11 and b<11) or (a<11 and b>=11): return True return False try: a=gameover(10,11) print(a) except: print("Error")
gameover测试的函数,没传参数的a,b,函数结果是True or False
try:试着执行gameover()函数,正常就执行函数
except:否则 打印'Error'
这里用10,11这一对来测试,结果为:
runfile('D:/新建文件夹/chesi.py', wdir='D:/新建文件夹')
True
程序运行正常且结果正确
若不输入参数,结果应为Error,结果为:

requests库是一个简洁且简单的处理HTTP请求的第三方库。
get()是对应与HTTP的GET方式,获取网页的最常用方法,可以增加timeout=n 参数,设定每次请求超时时间为n秒
text()是HTTP相应内容的字符串形式,即url对应的网页内容
content()是HTTP相应内容的二进制形式
用requests()打开百度20次
from requests import * try: for i in range(20): r=get("http://www.baidu.com") r.raise_for_status() r.encoding='utf-8' print(r) print(len(r.text)) print(len(r.content)) except: print("Error")
结果为:

爬取2015年的排行:
# -*- coding: utf-8 -*- #""" #Created on Tue May 21 22:02:48 2019 #@author: ASUS #""" import requests from bs4 import BeautifulSoup allUniv=[] def get(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "" def f(soup): data=soup.find_all('tr')
fw=open("pq2015.csv","w",encoding='utf-8') for tr in data: ltd=tr.find_all('td') if len(ltd)==0: continue s=[] for td in ltd: s.append(td.string) allUniv.append(s)
fw.write(",".join(s)+" ")
fw.close() def p(num): print("{1:^4}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}{6:{0}^10}{7:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","人才培养得分","科学研究得分","社会服务得分")) for i in range(num): u=allUniv[i] print("{1:^4}{2:{0}^11}{3:{0}^6}{4:{0}^7.1f}{5:{0}^10}{6:{0}^12}{6:{0}^10}".format(chr(12288),u[0],u[1],u[2],eval(u[3]),eval(u[4]),eval(u[5]),eval(u[6]))) def main(num): u='http://www.zuihaodaxue.cn/zuihaodaxuepaiming2015_0.html' h=get(u) soup=BeautifulSoup(h,"html.parser") f(soup) p(num) main(30)
结果为:
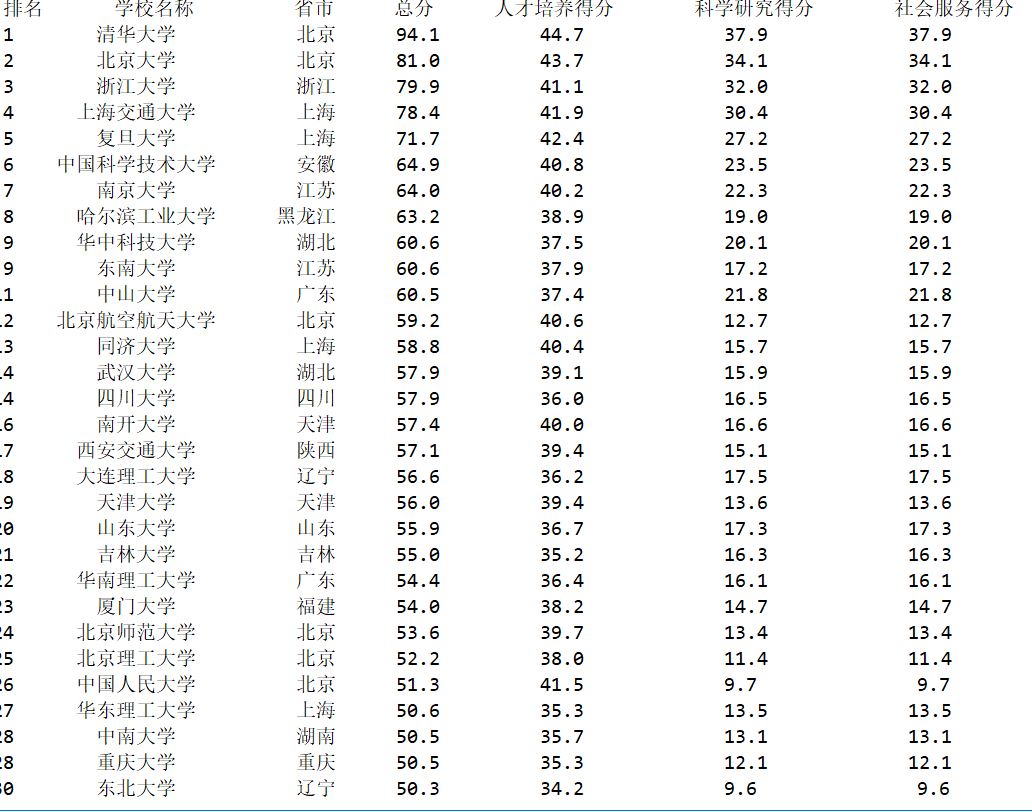
将数据保存到csv,结果为:
