HashMap底层实现采用了哈希表。哈希表的结构是“数组+链表”。
(1)数组:占空间连续,寻址容易,查询速度快,但是,增加和删除效率非常低。
(2)链表:占空间不连续,寻址困难,查询速度慢,但是,增加和删除效率高。
而哈希表就结合了二者的优点。
transient Node<K,V>[] table; //核心结点数组结构,也称为“位桶数组”。
看看Node节点的代码:(单链表结构)

Node对象的示意图:

HashMap的结构:
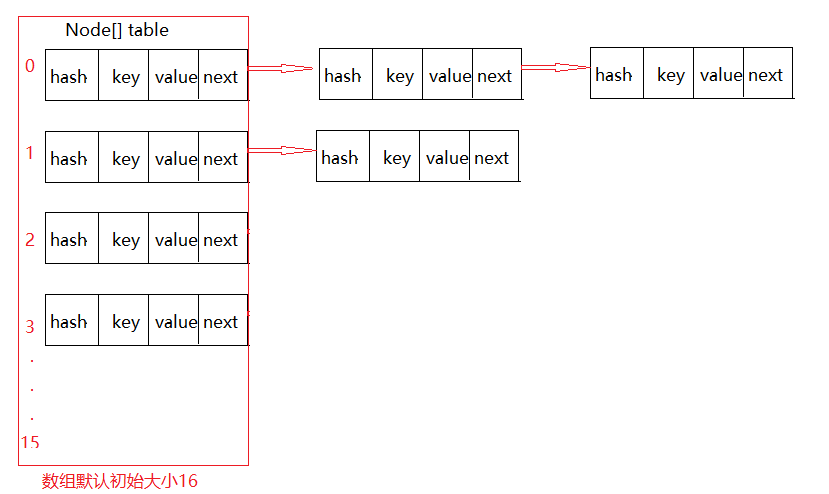
存储数据put(key,value)
会产生一个hash值。
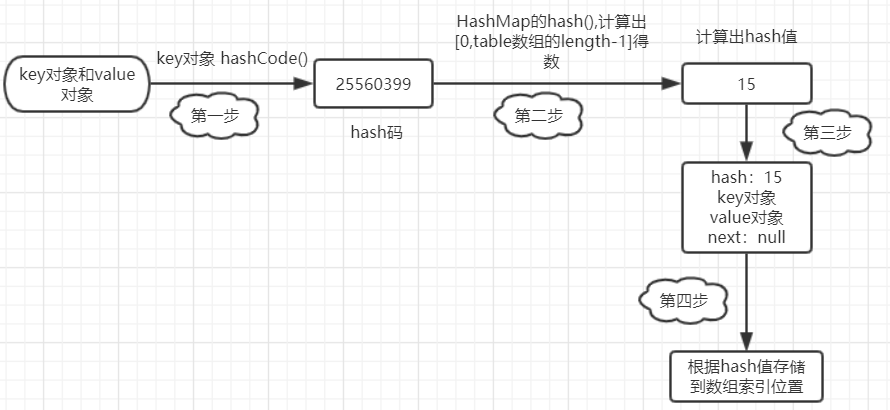
如果算出来的哈希值相同,则在数组索引位置后面进行链表串接(hash值相同)。
HashMap插入元素时会进行重hash,不能保证插入的有序性。
例如:

结果:

取数据get(key)
(1) 获得key的hashcode,通过hash()散列算法得到hash值,进而定位数组的位置。
(2) 在链表上挨个比较key对象。调用equals() 方法,将key对象和链表上所有节点的key对象进行比较,直到碰到返回true的结点对象为止。
(3) 返回equals()为true的结点对象的value对象。
扩容问题
HashMap的位桶数组,初始大小为16,实际使用中,大小是可变的。如果位桶数组的元素达到(0.75*数组length),就重写调整数组大小变为原来的2倍大小。
扩容很耗时。扩容的本质是定义新的更大的数组,并将旧数组的内容拷贝到新数组中。
JDK8将链表在大于8情况下变为红黑二叉树
大大提高查找效率。
import java.util.HashMap; import java.util.Iterator; import java.util.Map; public class HashMapDemo { public static void main(String[] args) { Map<String,String> hashMap = new HashMap<>(); //插入元素 hashMap.put("张三","zhangsan"); hashMap.put("李四","lisi"); System.out.println(hashMap); System.out.println(hashMap.isEmpty()); hashMap.put("李四","lisi1"); //键值对遍历 Iterator<Map.Entry<String, String>> iterator = hashMap.entrySet().iterator(); while (iterator.hasNext()){ Map.Entry<String, String> next = iterator.next(); String key = next.getKey(); String value = next.getValue(); System.out.print(key+":"+value+" "); } System.out.println(); //以值遍历 Iterator<String> iterator1 = hashMap.values().iterator(); while (iterator1.hasNext()){ System.out.print(iterator1.next()+" "); } System.out.println(); //以键遍历 Iterator<String> iterator2 = hashMap.keySet().iterator(); while (iterator2.hasNext()){ System.out.print(iterator2.next()+" "); } System.out.println(); } }
Iterator 的三种遍历方法:以键值对遍历,以值遍历,以键遍历。 当put的key键相同时,后面会覆盖前面的。

结果如图:
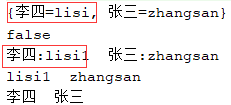
以上部分源码基于JDK1.8。