学习视频:http://cookdata.cn/auditorium/course_room/10014/
用回归解决分类
三种算法
1、感知机(Perceptron) 概念:找到一条直线,讲两类数据分开即可


2、支持向量机(Support Vector Machines) 概念:找到一条直线,不仅将两类数据正确分类,还使得数据离直线尽量远


3、逻辑回归(Logistic Regression) 概念:找到一条直线使得观察到训练集的“可能性”最大


Sklearn分类模块介绍
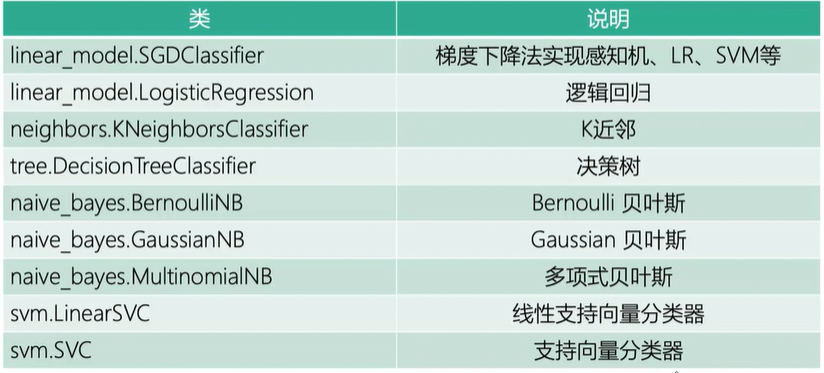
案例学习:
1、画点和相关直线
首先使用sklearn中的datasets模块生成一个随机的二分类数据集
from sklearn import datasets random_samples=datasets.make_classification(n_samples=60,#样本数量 n_classes=2,#类别数量 n_features=2,#特征数量 n_informative=2,#有信息特征数量 n_redundant=0,#冗余特征数量 n_repeated=0,#重复特征数量 n_clusters_per_class=1,#每一类的簇数 flip_y=0,#样本标签随机分配的比例 class_sep=3,#不同类别样本的分散程度 random_state=203)
为了便于后续处理,我们将生成的数据封装到Pandas的DataFrame中。数据集数据包含两个特征,特证名为x1和x2,标签值存放在label中。为了后续处理方便,我们给数据集添加一个取值全为1的ones
import pandas as pd data=pd.DataFrame(data=random_samples[0],columns=["x1","x2"]) data["label"]=random_samples[1] data["ones"]=1#添加一个取值全为1的列"ones" data.head()

在本案例即将实现的算法中,我们假设标签取值为1或-1,观察上表label列取值可见,默认的取值为0或-1,应用map方法,我们将label列取值映射为1和-1
data["label"]=data["label"].map({0:-1,1:1})#将y的取值替换成1和-1
为了值观地了解数据,我们将数据集用散点图绘制出来。matplotlib.pyplot模块地scatter函数可以绘制散点图,他的主要参数为横轴数据x,纵轴数据y,点地颜色c,点的形状等marker
数据集中正样本和负样本需要进行区分,我们首先将他们进行分离
data_pos=data[data["label"]==1]#筛选出正样本 data_neg=data[data["label"]==-1]#筛选出负样本来
将绘图框大小设置成(8,8),然后将正样本化成洋红色(c="#E4007E")的三角形(marker="^"),将负样本化成深绿色(c="#007979")的图形(marker="o")

import matplotlib.pyplot as plt plt.reParam['axes.nuicode_minus']=False plt.figure(figsize=(8,8))#设置图片尺寸 plt.scatter(data_pos["x1"],data_pos["x2"],c="#E4007F",marker="^")#类别为1的数据绘制成洋红色 plt.scatter(data_neg["x1"],data_neg["x2"],c="#007979",marker="o")#类别为-1的数据绘制成深绿色
plt.xlabel("$x_1$")#设置横轴标签
plt.ylabel("$x_2$")#设置纵轴标签
plt.xlim(-6,6)#设置横轴显示范围
plt.ylim(1,5)#设置纵轴显示范围
plt.show()
画出直线
import numpy as np w=[1,1,-4] x1=np.linspace(-6,6,50) x2=(w[0]/w[1])*x1-w[2]/w[1]