一、啥是数据解析
在上一篇关于爬虫的博客里,我提到过,整个爬虫分为四个部分,上一篇博客已经完成了前两步,也就是我说的最难的地方,接下来这一步数据解析不是很难,但就是很烦人,但只要你有耐心,一步一步查找、排除就会提取出目标信息,这一步就相当于从接收到的庞大数据中提取出真正想要、有意义的信息,所以对于爬虫来说,应该是很重要的。
数据解析有三种方式,一是通过正则表达式,在python中就是利用re模块;二是xpath;三是利用BeautifulSoup。
二、正则表达式
之前我们在学模块的时候讲过正则表达式,在这就不细说,献上经常用到的
单字符: . : 除换行以外所有字符 [] :[aoe] [a-w] 匹配集合中任意一个字符 d :数字 [0-9] D : 非数字 w :数字、字母、下划线 W : 非w s :所有的空白字符包,括空格、制表符、换页符等等。等价于 [ f v]。 S : 非空白 数量修饰: * : 任意多次 >=0 + : 至少1次 >=1 ? : 可有可无 0次或者1次 {m} :固定m次 hello{3,} {m,} :至少m次 {m,n} :m-n次 边界: $ : 以某某结尾 ^ : 以某某开头 分组: (ab) 贪婪模式: .* 非贪婪(惰性)模式: .*? re.I : 忽略大小写 re.M :多行匹配 re.S :单行匹配 re.sub(正则表达式, 替换内容, 字符串)
三、xpath
1,常用表达式
属性定位: #找到class属性值为song的div标签 //div[@class="song"] 层级&索引定位: #找到class属性值为tang的div的直系子标签ul下的第二个子标签li下的直系子标签a //div[@class="tang"]/ul/li[2]/a 逻辑运算: #找到href属性值为空且class属性值为du的a标签 //a[@href="" and @class="du"] 模糊匹配: //div[contains(@class, "ng")] //div[starts-with(@class, "ta")] 取文本: # /表示获取某个标签下的文本内容 # //表示获取某个标签下的文本内容和所有子标签下的文本内容 //div[@class="song"]/p[1]/text() //div[@class="tang"]//text() 取属性: //div[@class="tang"]//li[2]/a/@href
我们在使用xpath时,想要把字符串转化为etree对象:
tree=etree.parse(文件名)#这种是把一个本地文件转化成rtree对象
tree=etree.HTML(html标签字符串)
tree.xpath(xpath表达式) #这样就可以通过找到某个标签,取出标签的某个属性就得到想要的结果
2,示例一,爬取糗事百科图片,保存在本地
import requests
from lxml import etree
#这是请求的路径
url='https://www.qiushibaike.com/pic/' #这是伪造的浏览器UA
headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' }
#content拿到的是页面代码 content=requests.get(url=url,headers=headers).text
#把这个页面字符串代码转换成etree对象 tree=etree.HTML(content)
#这是拿到所有class=‘thumb’的div标签下的img标签的src属性,返回的是一个列表 img_src_list=tree.xpath('//div[@class="thumb"]//img/@src')
#循环每个src,然后再去访问,拿到图片的字节数据,存放于JPG文件,就得到每张图片了 for img_src in img_src_list: c1=requests.get(url='https:'+img_src,headers=headers).content with open('%s.jpg'%img_src[:5],'wb') as f: f.write(c1)
3,示例二,爬取煎蛋网的图片
这个就不是那么简单了,可以说是及其的难,我们用浏览器去访问一下煎蛋网,查看一下每张图片的src。
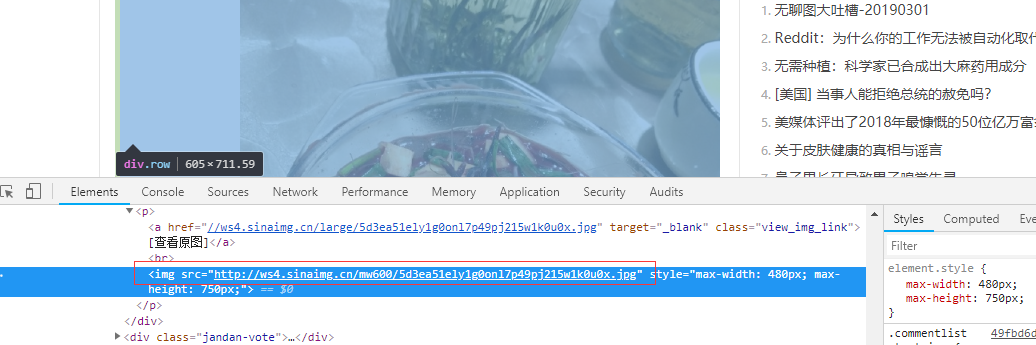
在这个元素的页面上,也就是加载完毕后的HTML文件,上面可以看到img的src属性,不用猜,这个肯定是图片的地址,很是兴奋,急急忙忙的写程序,访问页面,拿去img的src值,然后再发起请求拿到图片数据,保存下来,运行程序出错了,不是预期的结果。在这,给大家分享一个反爬机制,对于图片的src属性并不是直接写在html页面上的,而是在加载页面时用js得到img的src属性,然后赋值过去,其实我们可以点开network,查看response,这个response才是真正返回的HTML文件内容,也就是接收的内容。如下图:
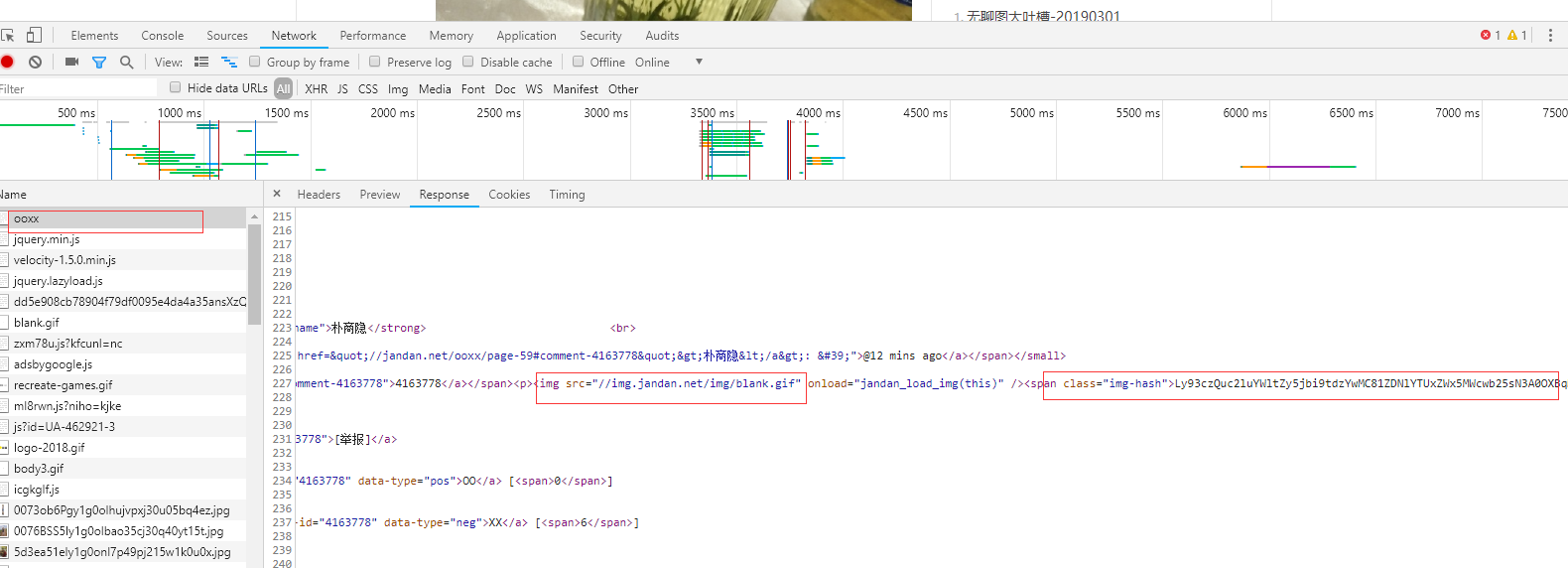
从response来看,它的所有图片的src都是一样的,说明并不是图片真正的输入窗路径,后面跟了一个span标签,class为img-hash,文本内容为一大段字符,可以猜出这是一个hash值,这个值就是img的src加密后的hash值,所以在加载页面时,通过js把加密的字符解开就是img的src属性,然后再赋给src(别问我是咋知道,我看别人这样写的,但确实是对的),这种通过js来动态加载的页面是一种反爬机制,而且是一种让人很头疼的反爬机制。
现在我们想要拿到他的src,就需要我们从返回的html文件中取出每个img-hash值,然后解密,得到真正的src,然后再对src发起请求。
import requests from lxml import etree headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } import base64 url='http://jandan.net/ooxx' content=requests.get(url=url,headers=headers).text tree=etree.HTML(content) hash_list=tree.xpath('//span[@class="img-hash"]/text()') #这是拿到了所有的img-hsah值,存放在一个列表中 for i in hash_list: ur=base64.b64decode(i).decode() #这里用base64解密(不要问我为啥用这个解密,你咋知道的。大佬说,在js代码发现有base64和md5的字样,然而md5是不可逆的,所以就是base64了) con=requests.get(url='http:'+ur,headers=headers).content with open('%s.jpg'%i,'wb') as f: f.write(con)
四、BeautifulSoup
1,方法
from bs4 import BeautifulSoup soup = BeautifulSoup(open('本地文件'), 'lxml') #这是把一个本地文件转换成BeautifulSoup对象 soup = BeautifulSoup('字符串类型或者字节类型', 'lxml')#这是把HTML字符串转换成BeautifulSoup对象 基础巩固: (1)根据标签名查找 - soup.a 只能找到第一个a标签,其他标签一样 (2)获取属性 - soup.a.attrs 获取第一个a标签所有的属性和属性值,返回一个字典 - soup.a.attrs['href'] 获取href属性 - soup.a['href'] 也可简写为这种形式 (3)获取内容 - soup.a.string - soup.a.text - soup.a.get_text() 【注意】如果标签还有标签,那么string获取到的结果为None,而其它两个,可以获取文本内容 (4)find:找到第一个符合要求的标签 - soup.find('a') - soup.find('a', title="xxx") - soup.find('a', alt="xxx") - soup.find('a', class_="xxx") #按类查找,得在把class写成class_ - soup.find('a', id="xxx") (5)find_all:找到所有符合要求的标签 - soup.find_all('a') - soup.find_all(['a','b']) 找到所有的a和b标签 - soup.find_all('a', limit=2) 限制前两个 (6)根据选择器选择指定的内容 #选择器的规则和css一模一样, select:soup.select('#feng') - 常见的选择器:标签选择器(a)、类选择器(.)、id选择器(#)、层级选择器 - 层级选择器: div .dudu #lala .meme .xixi 下面好多级 div > p > a > .lala 只能是下面一级 【注意】select选择器返回永远是列表,需要通过下标提取指定的对象
2,实例一,爬取抽屉网的新闻标题和连接
from bs4 import BeautifulSoup import requests url='https://dig.chouti.com/' headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' } con=requests.get(url=url,headers=headers).text
#这是实例化一个BeautifulSoup对象,对象就可以使用find、find_all等方法 soup=BeautifulSoup(con,'lxml') a_list=soup.find_all('a',class_="show-content color-chag")#这是拿到了很多的a标签, data_list=[] for a in a_list: dic={} dic['url']=a['href'] dic['content']=a.text.strip() data_list.append(dic) print(data_list)
3,实例二,爬取58同城的房源信息
from bs4 import BeautifulSoup import requests import xlwt import re headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36' }
#这是创建一个Excel,并创建一个sheet表,设置属性 workbook = xlwt.Workbook(encoding='ascii') worksheet = workbook.add_sheet('My Worksheet') worksheet.col(0).width = 14000 worksheet.col(5).width = 24000 #发送请求 url='https://sz.58.com/ershoufang/?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&PGTID=0d30000c-0000-4591-0324-370565eccba8&ClickID=1' res=requests.get(url=url,headers=headers) con=res.text
#实例化一个对象 soup=BeautifulSoup(con,'lxml') ss=soup.find('ul',class_='house-list-wrap') li_list=ss.find_all('li') #这是拿到了所有的li标签 patter=re.compile(r's',re.S)
#这是循环每个li标签,这里拿到的每个li标签还是一个BeautifulSoup对象,一样拥有find、find_all等方法,对每个li标签处理拿到每个房源的各种信息,然后写入Excel中 for num in range(len(li_list)): worksheet.write(num, 0, label=li_list[num].find('a',tongji_label="listclick").text.strip()) p1=li_list[num].find_all('p')[0] span_list=p1.find_all('span') worksheet.write(num, 1, label=patter.sub('',span_list[0].text)) worksheet.write(num, 2, label=patter.sub('',span_list[1].text)) worksheet.write(num, 3, label=patter.sub('',span_list[2].text)) worksheet.write(num, 4, label=patter.sub('',span_list[3].text)) worksheet.write(num,5, label=patter.sub('',li_list[num].find('div',class_='jjrinfo').text)) worksheet.write(num, 6, label=li_list[num].find('p',class_='sum').text) worksheet.write(num, 7, label=li_list[num].find('p',class_='unit').text) workbook.save('myWorkbook.xls')
4,实例三,爬取github
github是需要登录验证的,所以我们照我上一篇讲的模拟登录的步骤,先用浏览器输入一组错误信息,点击登录,找的登录发送的路径和数据结构,

明显发现这就是登录请求的路径,数据结构拿到了,再去拿到请求的路径
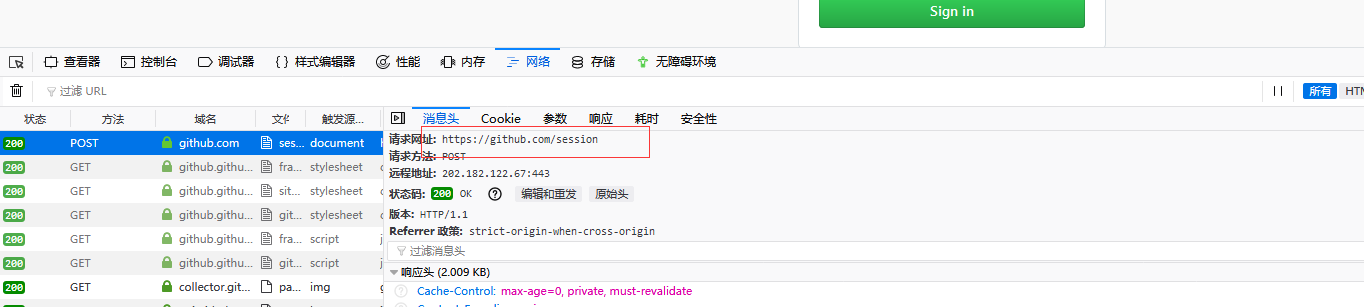
这下就可以发送请求,我最先访问的是login页面,得到cookie,带这个cookie和data数据,往登录的路径发送请求,但不得行。于是乎回来看了一看,要求的数据结构,其中有个叫token的东西,怎么那么熟悉,这个不是那个随机值CSRF-token,我就再去看了一下HTML页面,
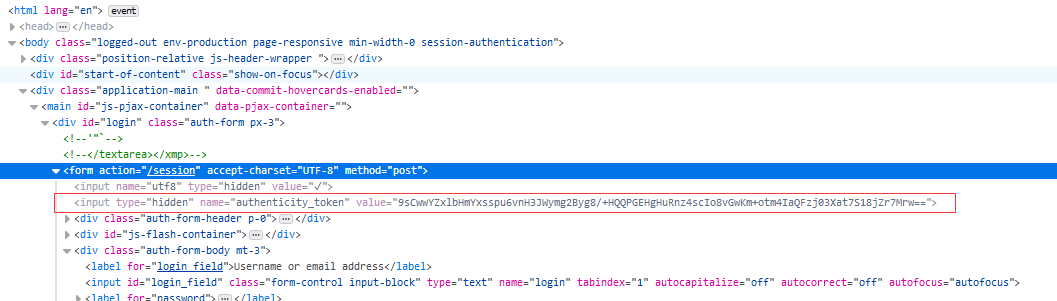
确实是基于form表单发送请求的CSRF-token,这个东西是一个随机值,所以我的程序得想去访问login页面,拿到登陆页面,取得这个token值,放在data数据里,我之前程序的其他部分就不用变了,于是乎就成功了。
import requests import re url='https://github.com/login' url1='https://github.com/session' headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36', } session=requests.session() res1=session.get(url=url,headers=headers) token=re.findall(r'name="authenticity_token".*?value="(?P<name>.*?)"',res1.text,re.S)[0] #这就是用BeautifulSoup取得token值 data={ 'commit': 'Sign in', 'utf8': '✓', 'authenticity_token': token, 'login': 'xxxxxx', 'password':'xxxxx' } session.post(url=url1,data=data,headers=headers) url2='https://github.com/' res=session.get(url=url2,headers=headers) with open('github1.html','wb') as f: f.write(res.content)