TensorFlow中一些基本的概念:
(1)tf.placeholder():tf.placeholder(dtype, shape=None, name=None)
placeholder就是一个占位符,可以规定数据类型,数据的维度以及数据的名称;变量在定义时要初始化,但可能有些变量我们一开始定义的时候并不一定知道该变量的值,只有当真正开始运行程序的时候才由外部输入,比如我们需要训练的数据,所以就用占位符来占个位置,告诉TensorFlow,等到真正运行的时候再通过输入数据赋值。
(2)tf.Session():可以认为session就是tensorflow运行的环境,所有的操作都是在sesssion中执行,比如对变量的初始化等等。
(3)sess.run():sess.run(fetches,feed_dict={})
参数说明:fetches:单个图元素,图元素列表或字典,字典元素其值是图元素或图元素列表;feed_dict:作用是替换图中的某个tensor的值。
返回值:如果fetches是单个图元素则返回单个值,如果fetches是列表则返回值列表,如果fetches是字典则返回具有相同键的字典。
(4)tf.Variable():定义一个变量,如:
y = tf.Variable(1.0, tf.float32) # 声明一个tf.float32的变量,并将初始值设为1.0
(5)tf.Constant():定义一个常量,用法与tf.Variable()相近。
下面是实现线性回归的代码以及相关注释:
#coding=utf-8
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.compat.v1.disable_eager_execution()
#Parameters
learning_rate=0.01
training_epochs=1000
display_step=50
#training Data
train_X=np.asarray([3.3,4.4,5.5,6.71,6.93,4.168,9.779,6.182,7.59,2.167,7.042,10.791,5.313,7.997,5.654,9.27,3.1])
train_Y=np.asarray([1.7,2.76,2.09,3.19,1.694,1.573,3.366,2.596,2.53,1.221,2.827,3.465,1.65,2.904,2.42,2.94,1.3])#产生数组的实例化对象,asarray不新产生副本占据内存
n_samples=train_X.shape[0]#shape[0]用于读取数组的第一维长度
X=tf.compat.v1.placeholder("float")
Y=tf.compat.v1.placeholder("float")
W=tf.Variable(np.random.randn(),name="weight")#Variable(变量),需要有初始值,这里初始值是随机生成的一个浮点数
b=tf.Variable(np.random.randn(),name='bias')#np.random.randn()生成一个浮点数
pred=tf.add(tf.multiply(X,W),b)#pred=x*w+b
#定义损失函数和优化方法
#损失函数cost
cost=tf.reduce_sum(tf.pow(pred-Y,2))/(2*n_samples)
#优化函数GradientDescentOptimizer(梯度下降)后面传入的值是学习效率。一般是一个小于1的数。越小收敛越慢,但并不是越大收敛越快
optimizer=tf.compat.v1.train.GradientDescentOptimizer(learning_rate).minimize(cost)
#初始化变量的操作
init =tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
sess.run(init)#初始化变量
for epoch in range(training_epochs):
for (x,y) in zip(train_X,train_Y):
sess.run(optimizer,feed_dict={X:x,Y:y})#feed_dict作用是替换图中的某个tensor的值
if (epoch+1) % display_step==0:
c=sess.run(cost,feed_dict={X:train_X,Y:train_Y})
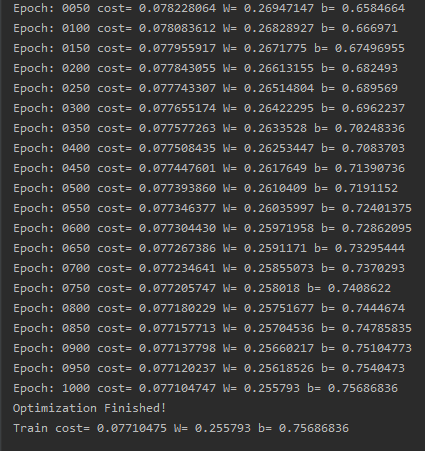
print("Epoch:" ,'%04d' %(epoch+1),"cost=","{:.9f}".format(c),"W=",sess.run(W),"b=",sess.run(b))
print("Optimization Finished!")
training_cost=sess.run(cost,feed_dict={X:train_X,Y:train_Y})
print("Train cost=",training_cost,"W=",sess.run(W),"b=",sess.run(b))
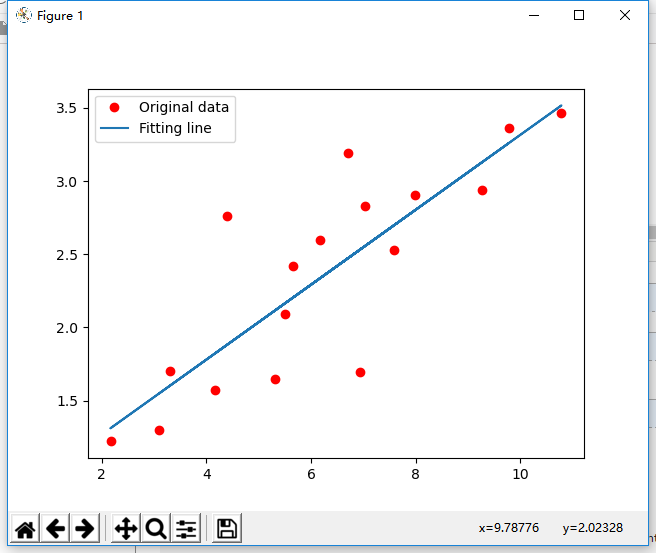
plt.plot(train_X,train_Y,'ro',label='Original data')
plt.plot(train_X,sess.run(W)*train_X+sess.run(b),label="Fitting line")
plt.legend()#给图加上图例
plt.show()
结果截图: